本章节将介绍PaddleSeg的核心部分,分割模型和主干网络部分,在yaml配置文件中有以下定义:
#模型信息
model:
#模型的类型FCN
type: FCN
#使用的主干网络为HRNet
backbone:
type: HRNet_W18
#主干网络的预训练模型的下载地址。
pretrained: https://bj.bcebos.com/paddleseg/dygraph/hrnet_w18_ssld.tar.gz
#模型支持的类别为19种。
num_classes: 19
#模型的预训练地址,这里为空
pretrained: Null
#这个是创建模型时需要传入的参数,该参数指定FCN使用backbone返回的哪个特征图。backbone可以根据不同的块返回不同尺度的特征图。
backbone_indices: [-1]
以上配置文件定义了一个最基本的FCN网络。首先我们来介绍一下FCN网络。
FCN网络全称为Fully Convolutional Networks,按字面意思就是全部都是卷积的网络,没有全连接层。FCN是在论文《Fully convolutional networks for semantic segmentation》提出的。
FCN之所以可以对图像进行分割,是因为实现了像素级分类。试想一下,在一张图片里每一个像素点就被分为某一个类别,这样整张图像自然就被分割成不同的区域了。
下面贴一张论文中FCN结构图:
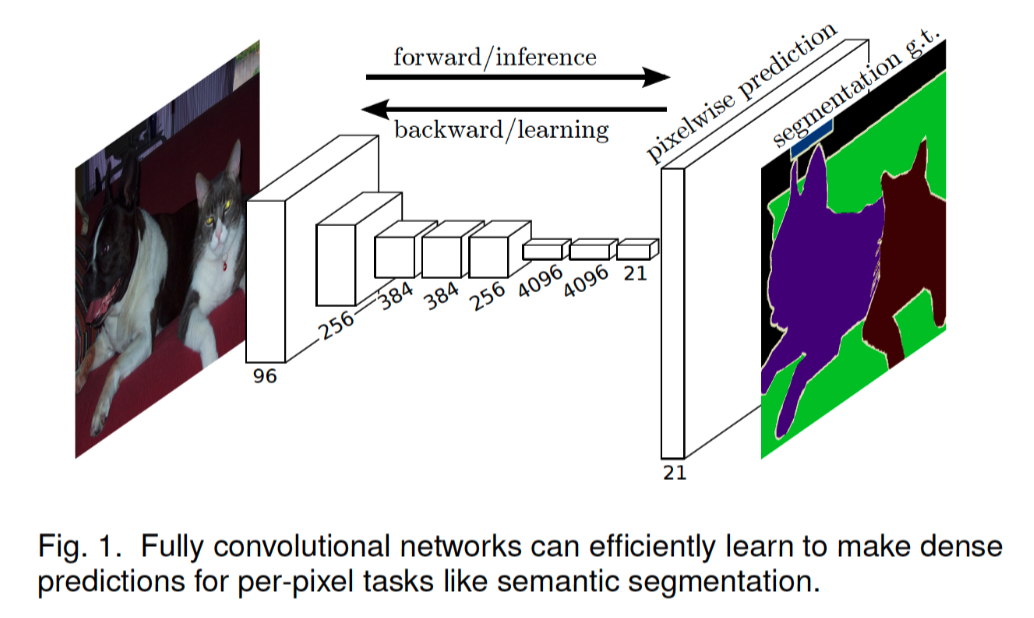
FCN网络的输入是RGB三通道的图像数据,例如形状为[224,224,3]的图像数据,输出的是每一个像素点类别,数据形状可以是[n_classes, 224, 224]。
在图像分类任务中,网络的最顶层是一个全连接网络,代表了图像的类别。而在图像分割任务中,最后需要输出的是一个与输入图像尺寸相同的分割图像。要实现这个目的我们需要做以下两方面的处理:
- 将分类网络中的FC层替换为1x1的卷积层。
- 上采样
在图像分割网络中将FC层替换为1x1的卷积层,这样对特征图进行卷积以后,不会改变特征图的尺寸,会改变特征图的通道数,可以认为1x1的卷积是在通道维度上对特征图进行升维或者降维。
对特征图进行1x1卷积操作以后,需要对图像进行上采样操作,使特征图恢复到输入图像大小。
一般上采样有以下三种方法:
- 上采样,比如双线性插值
- 反池化
- 转置卷积
下面介绍一下这三种方法具体实现方法。
1.双线性插值。
将一个小图像变成为一个大图像,一般都是在像素点之间插入一些点来扩充图像,但是插入的点的像素值如何确定是一个问题,在采样算法中,有多种插值的算法,这里我们介绍一种常用的双线性插值方法。这种方法不但计算比较简单,同时效果也不错。
假如有以下4个点Q11、Q12、Q21和Q22。想在坐标为(x,y)的位置插入一个P点。那如何确定P点的像素值呢?
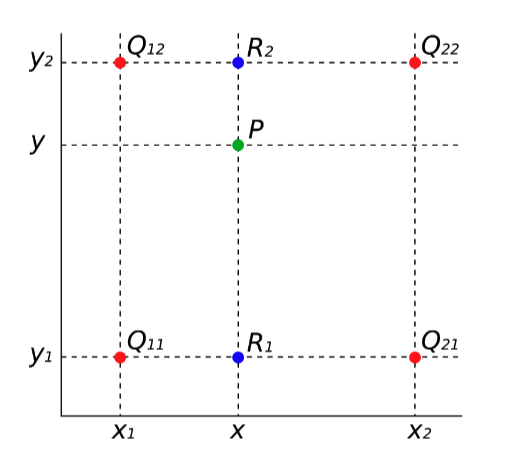
首先我们做第一次插值,x方向插值计算出图中R1和R2的像素值。
以计算R1的值为例,可以从图中观察到,点R1在X方向上,位于Q11和Q21之间,可以认为R1的值同时受Q11和Q21影响,R1距离Q11稍微近一些,那R1的像素值就受Q11影响比较大,受Q21的影响就比较少,所以根据R1距两点的距离可以得出以下公式:
v
(
R
1
)
=
x
2
−
x
x
2
−
x
1
v
(
Q
11
)
+
x
−
x
1
x
2
−
x
1
v
(
Q
21
)
v\left(R_1\right) = \frac{x_2 - x}{x_2 - x_1}v\left(Q_{11}\right) + \frac{x - x_1}{x_2 - x_1}v\left(Q_{21}\right)
v(R1)=x2−x1x2−xv(Q11)+x2−x1x−x1v(Q21)
同理计算R2的值的公公式如下:
v
(
R
2
)
=
x
2
−
x
x
2
−
x
1
v
(
Q
12
)
+
x
−
x
1
x
2
−
x
1
v
(
Q
22
)
v\left(R_2\right) = \frac{x_2 - x}{x_2 - x_1}v\left(Q_{12}\right) + \frac{x - x_1}{x_2 - x_1}v\left(Q_{22}\right)
v(R2)=x2−x1x2−xv(Q12)+x2−x1x−x1v(Q22)
然后我们在做第二次线性插值得出P点的像素值,与之前计算R1和R2的值类似,只不过这是在Y方向上进行计算,公式如下:
v
(
P
)
=
y
2
−
y
y
2
−
y
1
v
(
R
1
)
+
y
−
y
1
y
2
−
y
1
v
(
R
2
)
v\left(P\right) = \frac{y_2 - y}{y_2 - y_1}v\left(R_1\right) + \frac{y - y_1}{y_2 - y_1}v\left(R_2\right)
v(P)=y2−y1y2−yv(R1)+y2−y1y−y1v(R2)
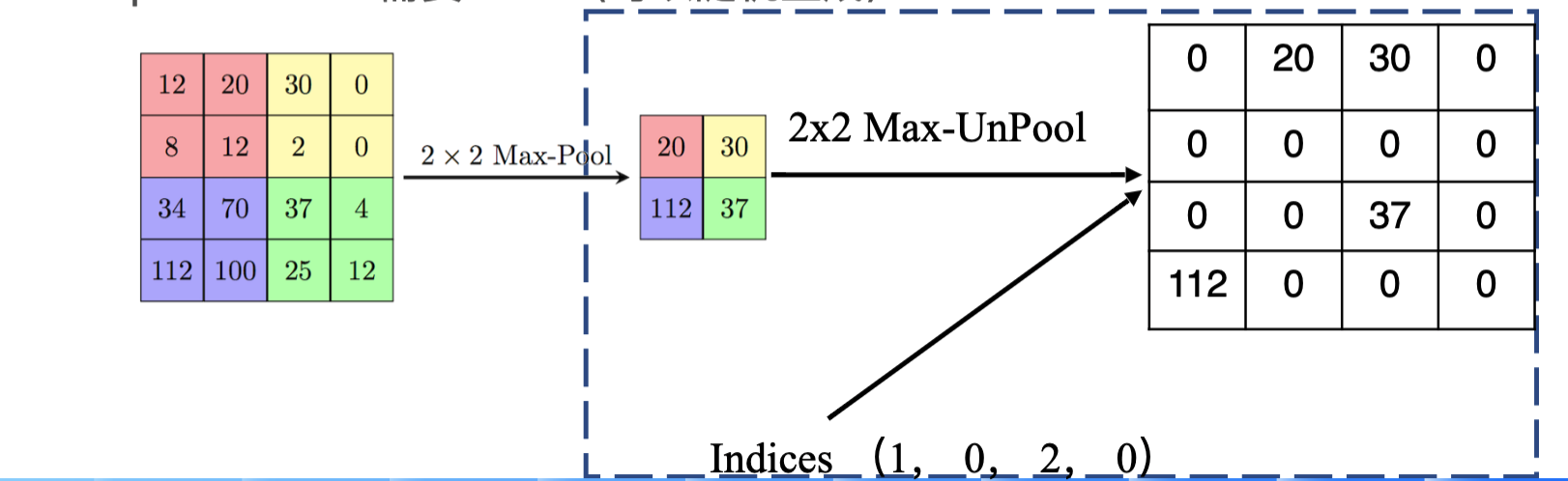
2.反池化
这个一般用的比较少,因为需要记录池化时的索引号,如果没有记录也可以随机生成索引号。这个实现比较简单,过程如下图:
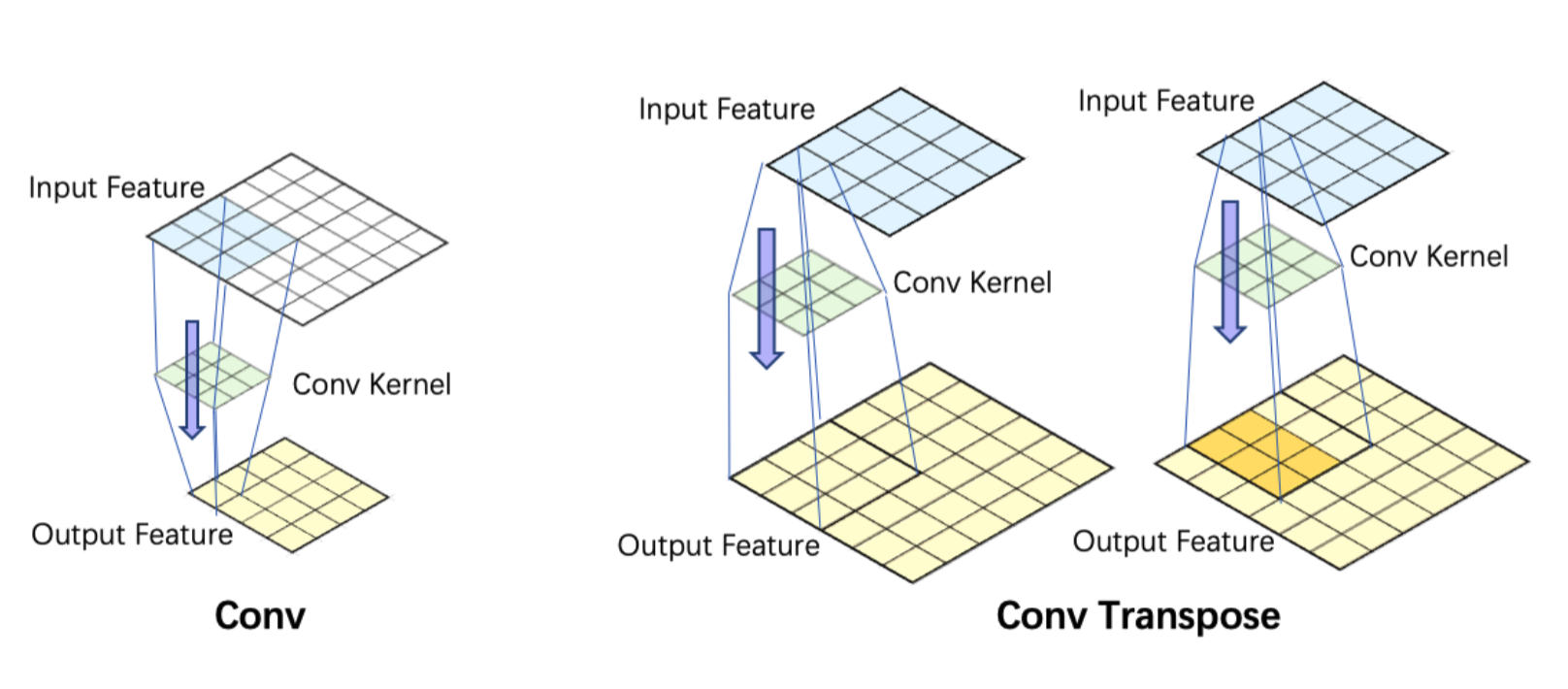
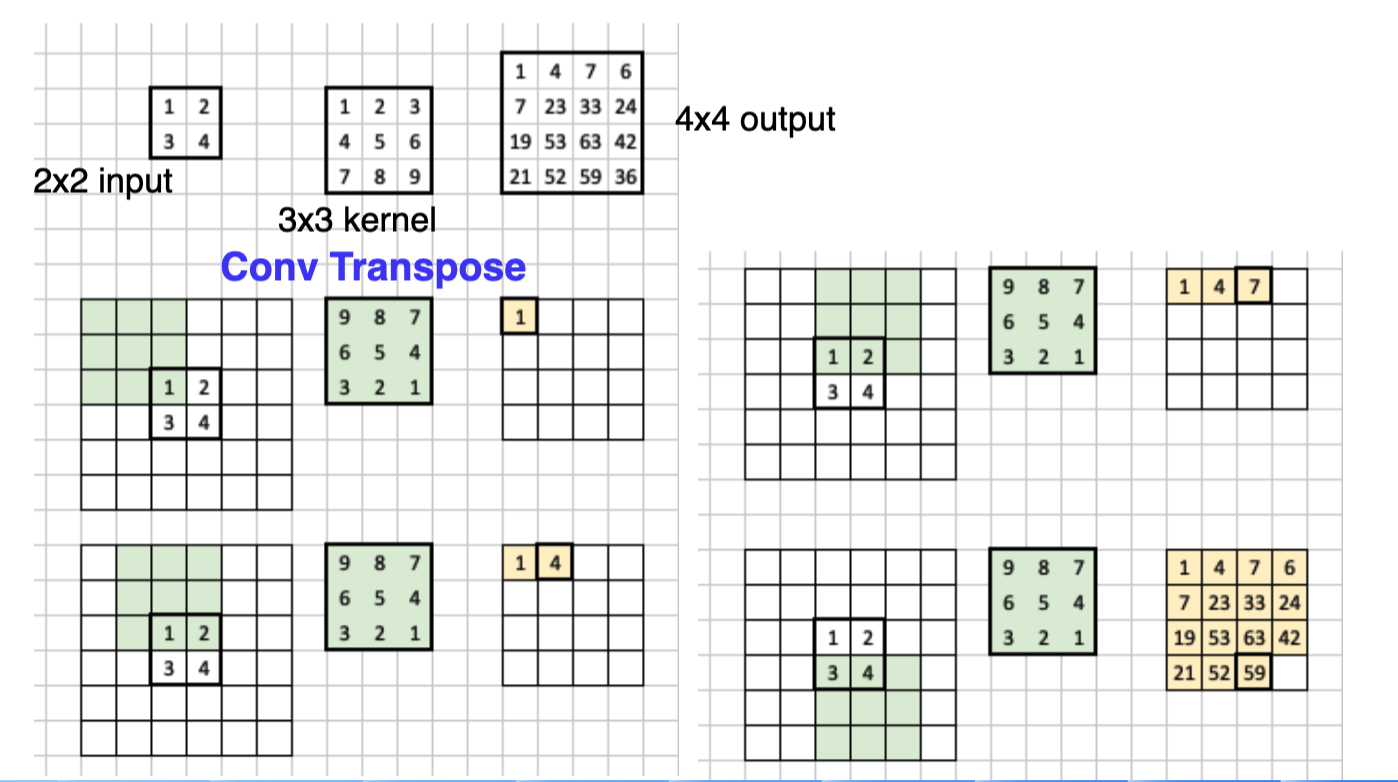
3.转置卷积(也叫反卷积)
正常的卷积操作,是将图像越卷越小,而转置卷积则是将卷积核进行选择180度,然后对图像进行padding之后进行卷积操作,最后得到一个大尺寸的特征图,具体操作如下。
paddleseg套件中的FCN网络架构如下:
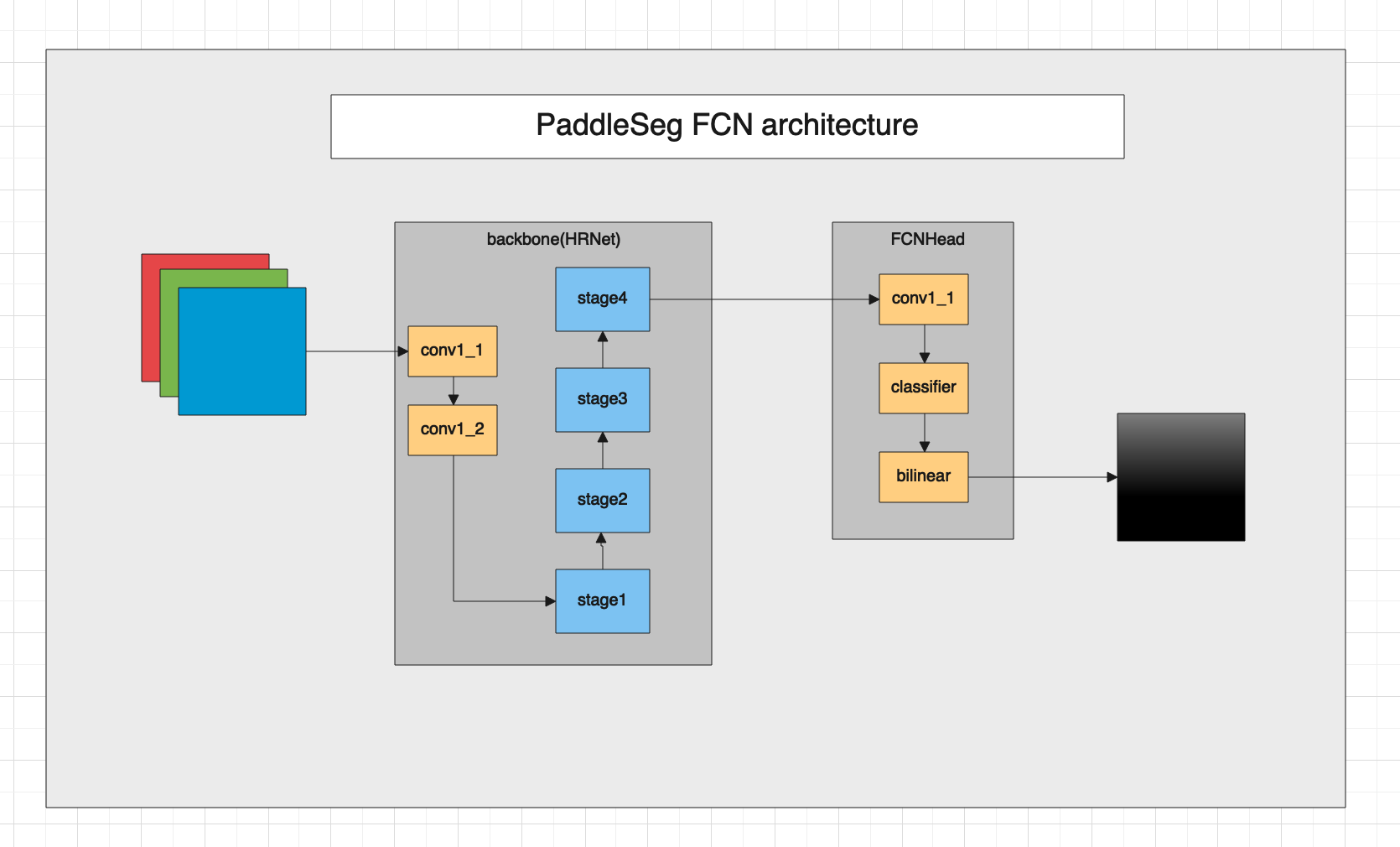
下面我们来看下FCN的代码,FCN定义在paddleseg/models/fcn.py文件中。
在FCN文件中有个FCNHead的类,它是FCN网络的最终输出模块,首先我们先看看它的实现代码以及解读。
class FCNHead(nn.Layer):
def __init__(self,
num_classes,
backbone_indices=(-1, ),
backbone_channels=(270, ),
channels=None):
super(FCNHead, self).__init__()
#类别数
self.num_classes = num_classes
#使用backbone返回特征列表的索引号,backbone可以将不同block的特征图组成一个列表返回。
self.backbone_indices = backbone_indices
#backbone返回特征图的通道数
if channels is None:
channels = backbone_channels[0]
#定义一个卷积核为1x1,带有BN层,激活函数为Relu的卷积层。
self.conv_1 = layers.ConvBNReLU(
in_channels=backbone_channels[0],
out_channels=channels,
kernel_size=1,
padding='same',
stride=1)
#定义一个卷积核为1x1的卷积层,输出通道为分类数,作为分类器。
self.cls = nn.Conv2D(
in_channels=channels,
out_channels=self.num_classes,
kernel_size=1,
stride=1,
padding=0)
self.init_weight()
#正向传播函数,在动态图模型中,重写该函数,将前向运算过程写在这里面。
def forward(self, feat_list):
logit_list = []
#使用backbone_inices中的索引号,取出backbone返回的特征图
x = feat_list[self.backbone_indices[0]]
#进行1x1卷积运算
x = self.conv_1(x)
#经过分类器,得到通道数为分类数量的特征图。
logit = self.cls(x)
#为了兼容返回多个特征图的backbone,这里即使只有一个logit也放在一个列表当中返回。
logit_list.append(logit)
return logit_list
#初始化参数
def init_weight(self):
for layer in self.sublayers():
if isinstance(layer, nn.Conv2D):
param_init.normal_init(layer.weight, std=0.001)
elif isinstance(layer, (nn.BatchNorm, nn.SyncBatchNorm)):
param_init.constant_init(layer.weight, value=1.0)
param_init.constant_init(layer.bias, value=0.0)
下面来看一下FCN的模型,代码如下:
class FCN(nn.Layer):
def __init__(self,
num_classes, #类别数目
backbone, #主干网络对象
backbone_indices=(-1, ), #主干网络输出特征图的id
channels=None, #通道数
align_corners=False, #对特征图进行缩放的参数
pretrained=None): #预训练模型的url或者路径
super(FCN, self).__init__()
#保存backbone模型
self.backbone = backbone
#根据backbone的索引号,获取backbone中的特征图的通道数。
backbone_channels = [
backbone.feat_channels[i] for i in backbone_indices
]
#定义一个head.
self.head = FCNHead(num_classes, backbone_indices, backbone_channels,
channels)
#保存上采样参数。
self.align_corners = align_corners
self.pretrained = pretrained
#初始化参数
self.init_weight()
def forward(self, x):
#将输入图片送backbone运算,得到特征图列表,在FCN中,只有一个特征图。
feat_list = self.backbone(x)
#将特征图送入head进行运算得到通道数为类别数的特征图。
logit_list = self.head(feat_list)
#对特征图进行上采样,得到与输入图像尺寸一致的分割图,这里每一个像素都自己的分类,通道数与分类数一致。
return [
F.interpolate(
logit,
x.shape[2:],
mode='bilinear',
align_corners=self.align_corners) for logit in logit_list
]
#初始化参数
def init_weight(self):
if self.pretrained is not None:
utils.load_entire_model(self, self.pretrained)
下面我们介绍一下主干网络HRNet的结构,HRNet可以分为4个部分,首先我们看一下第一部分的结架构图。

HRNet网络的第二部分架构图如下。
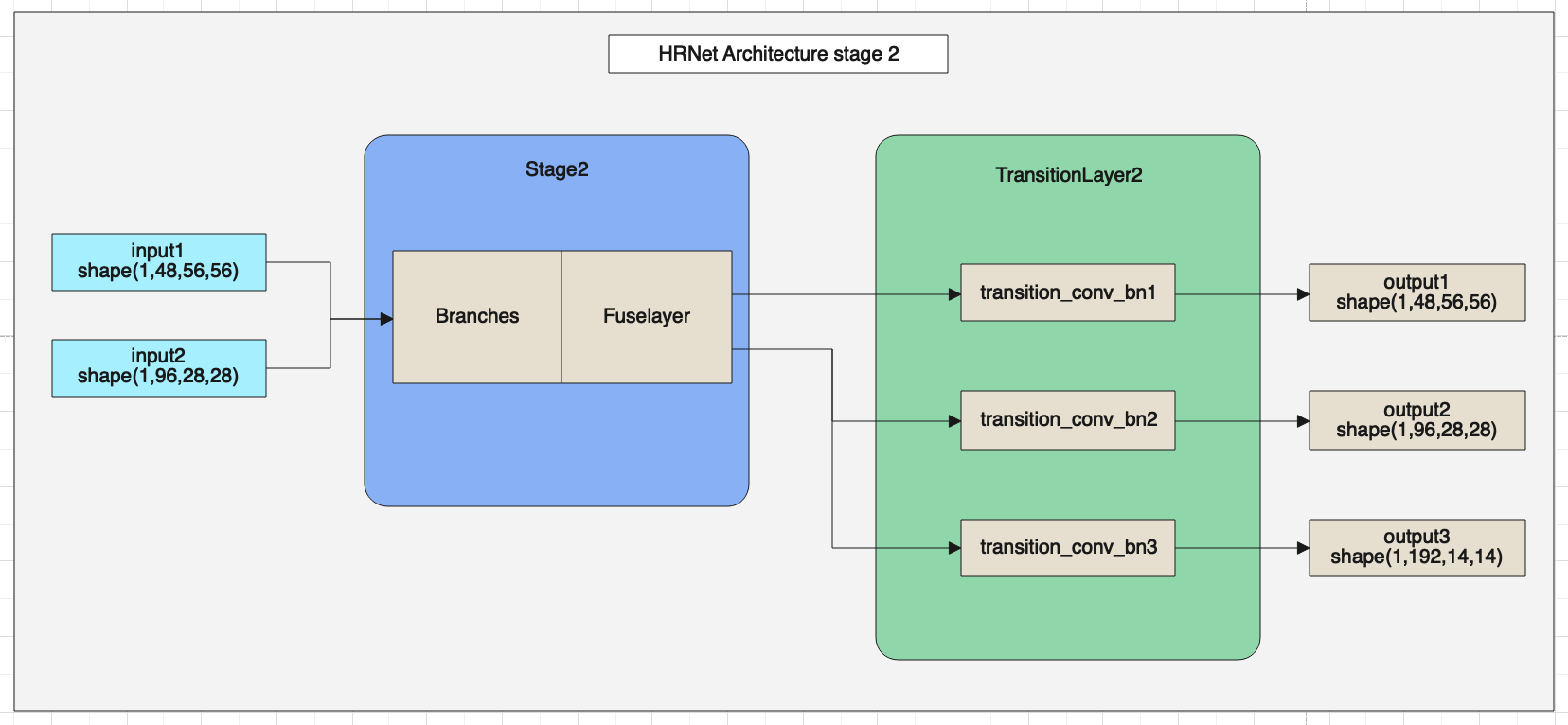
HRNet网络的第三部分架构图如下。

HRNet网络的第四部分架构图如下。
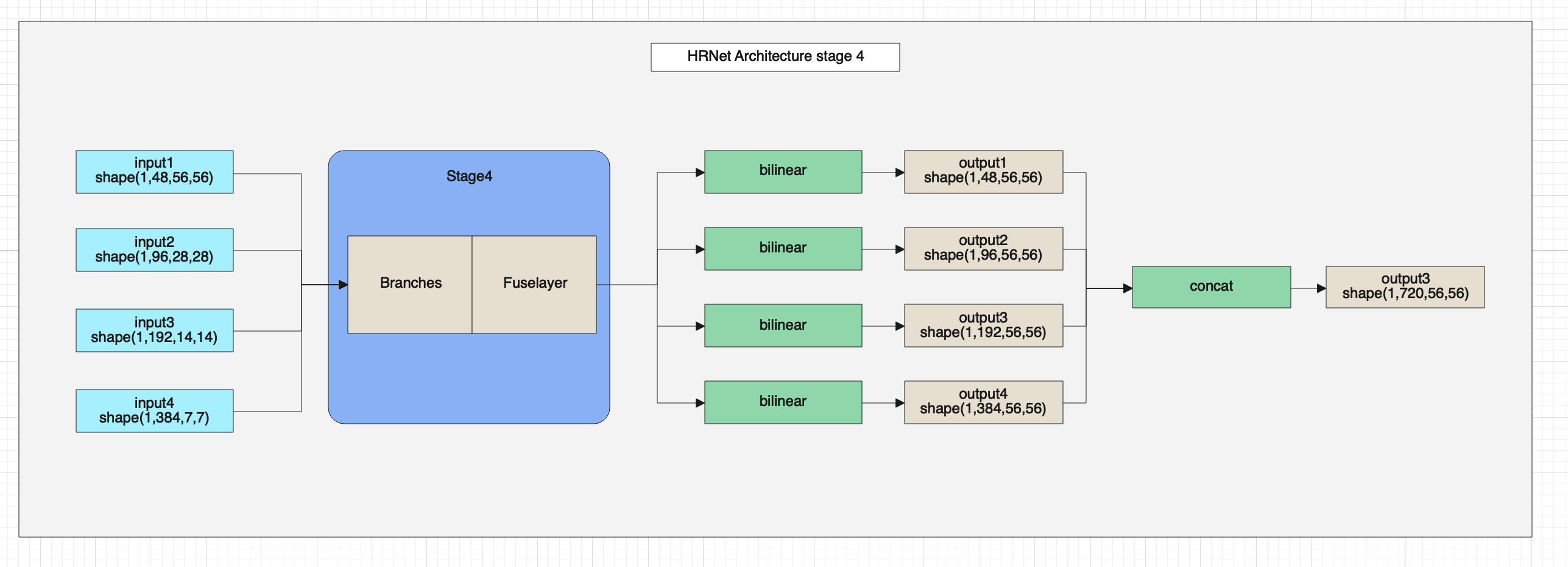
HRNet的网络整体架构如上图所示,在图中可以看出HRNet由BottleneckBlock、Branches和FuseLayer构成,下面我们详细介绍一下这三个模块的架构与代码。
首先我们看一下BottlenneckBlock的架构图:
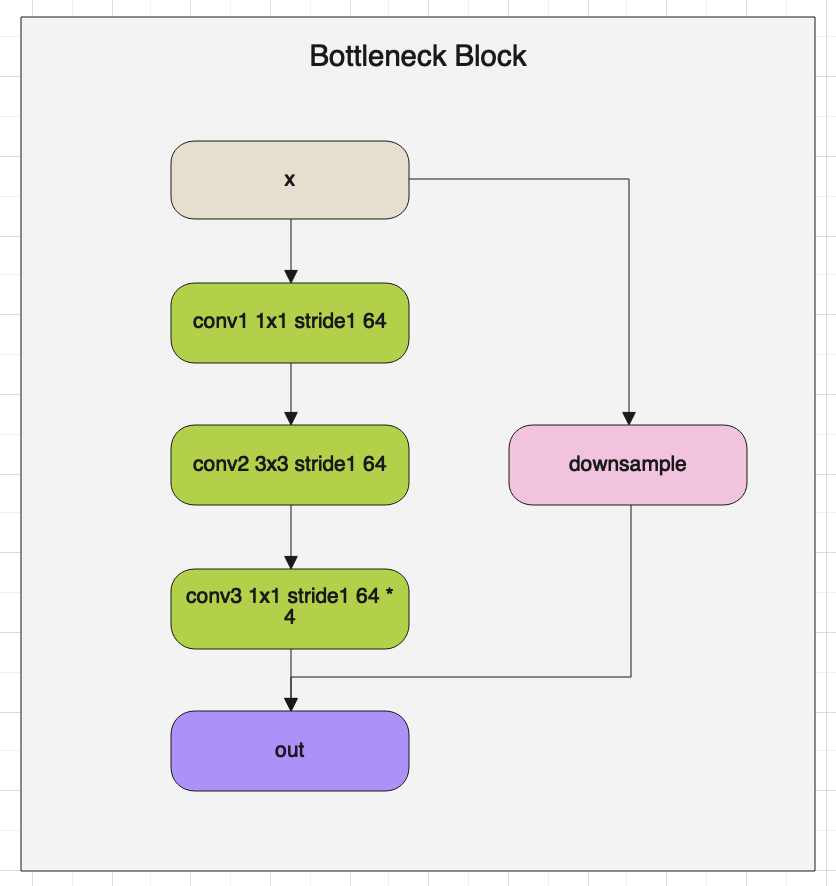
BottlenneckBlock就像名字一样,将特征图通道数固定到某一个值后,然后在放大,使通道数像一个瓶颈一样,上面细下面宽。
下面解读一下BottlenneckBlock的源代码:
class BottleneckBlock(nn.Layer):
def __init__(self,
num_channels,#输入通道数
num_filters, #卷积核数量
has_se, #是否使用SELayer
stride=1, #卷积核步长
downsample=False, #是否开启下采样
name=None): #参数名称
super(BottleneckBlock, self).__init__()
self.has_se = has_se
self.downsample = downsample
#定义卷积,将特征图的通道数设置为num_filters
self.conv1 = layers.ConvBNReLU(
in_channels=num_channels,
out_channels=num_filters,
kernel_size=1,
padding='same',
bias_attr=False)
#定义第二层卷积,将特征图的通道数设置为num_filters,这里kernel_size不同。
self.conv2 = layers.ConvBNReLU(
in_channels=num_filters,
out_channels=num_filters,
kernel_size=3,
stride=stride,
padding='same',
bias_attr=False)
#定义1x1卷积,放大特征图的通道数量
self.conv3 = layers.ConvBN(
in_channels=num_filters,
out_channels=num_filters * 4,
kernel_size=1,
padding='same',
bias_attr=False)
#一般第一个bottleneck Block需要做一个下采样。
if self.downsample:
self.conv_down = layers.ConvBN(
in_channels=num_channels,
out_channels=num_filters * 4,
kernel_size=1,
padding='same',
bias_attr=False)
if self.has_se:
self.se = SELayer(
num_channels=num_filters * 4,
num_filters=num_filters * 4,
reduction_ratio=16,
name=name + '_fc')
def forward(self, x):
#按顺序进行前向计算
residual = x
conv1 = self.conv1(x)
conv2 = self.conv2(conv1)
conv3 = self.conv3(conv2)
if self.downsample:
residual = self.conv_down(x)
if self.has_se:
conv3 = self.se(conv3)
#与残差相加
y = conv3 + residual
y = F.relu(y)
return y
在每个stage之前都有个TransitionLayer,该层主要是从输入的特征图列表中,取出尺寸最小的特征图进行下采样,增加一个特征图分支。
TransitionLayer架构图可参考HRNet的总体架构图。
TransitionLayer层的代码解读如下:
class TransitionLayer(nn.Layer):
def __init__(self, in_channels, out_channels, name=None):
super(TransitionLayer, self).__init__()
#由于经过TransitionLayer会多出一路分支,所以一般num_out比num_in要大
num_in = len(in_channels)
num_out = len(out_channels)
self.conv_bn_func_list = []
#需要num_out个特征图作为输出,使用循环创建num_out个输出。
for i in range(num_out):
residual = None
#在i小于等于输入的特征图数量时,可以直接做一个3x3的卷积作为输出。
if i < num_in:
if in_channels[i] != out_channels[i]:
residual = self.add_sublayer(
"transition_{}_layer_{}".format(name, i + 1),
layers.ConvBNReLU(
in_channels=in_channels[i],
out_channels=out_channels[i],
kernel_size=3,
padding='same',
bias_attr=False))
#在i大于输入特征图数量时,需要新创建一个特征图,这里使用stride=2的卷积下采样一个特征图作为输出。
else:
residual = self.add_sublayer(
"transition_{}_layer_{}".format(name, i + 1),
layers.ConvBNReLU(
in_channels=in_channels[-1],
out_channels=out_channels[i],
kernel_size=3,
stride=2,
padding='same',
bias_attr=False))
self.conv_bn_func_list.append(residual)
def forward(self, x):
outs = []
#对输入的特征图进行卷积运算。
for idx, conv_bn_func in enumerate(self.conv_bn_func_list):
if conv_bn_func is None:
outs.append(x[idx])
else:
if idx < len(x):
#对原有的输入特征图进行卷积操作,并加入输出列表。
outs.append(conv_bn_func(x[idx]))
else:
#新建一个特征图,使用输入特征图中尺寸最小,使用卷积进行下采样生成新的特征图,加入到输出列表中。
outs.append(conv_bn_func(x[-1]))
return outs
在Stage层中会用到两个层一个是Branches,另外一个是FuseLayers。
首先我们先来看一下Branches,它的架构图如下:
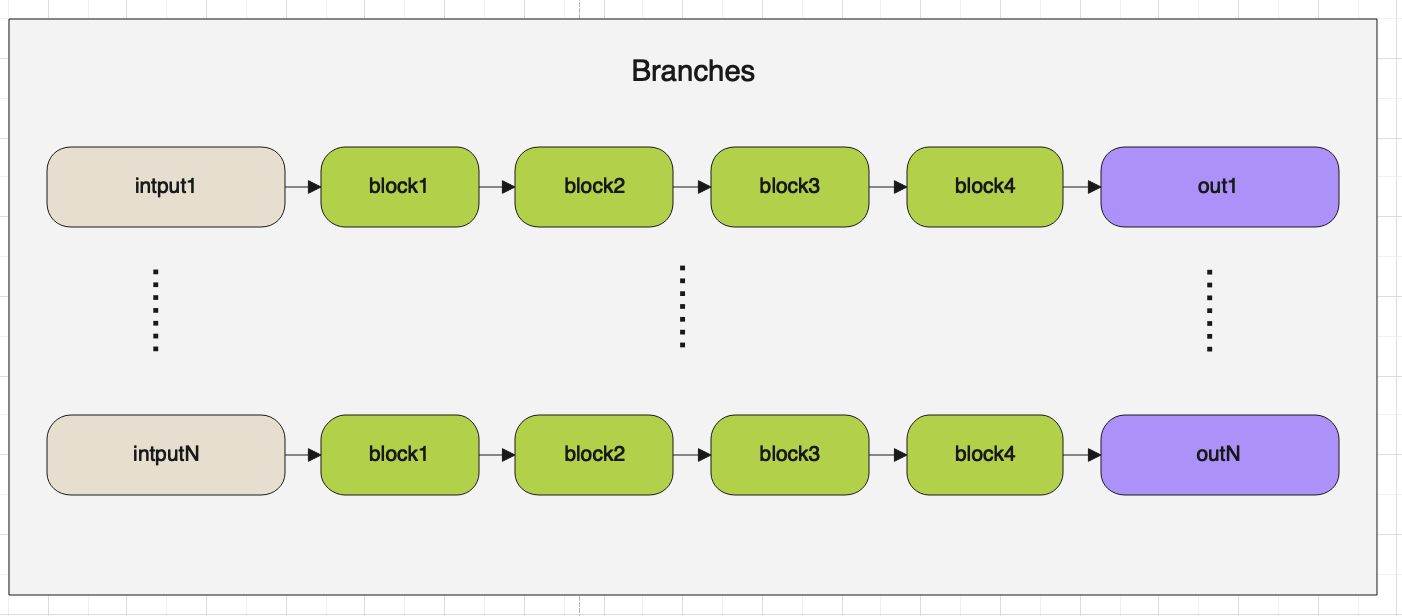
Branches的代码如下:
class Branches(nn.Layer):
def __init__(self,
num_blocks, #block数量
in_channels, #输入通道数
out_channels, #输出通道数
has_se=False,
name=None):
super(Branches, self).__init__()
self.basic_block_list = []
#经过TransitionLayer后,会被分成不同分辨率和通道数的多路特征图,这里根据特征的路数,分别进行卷积操作。
#每一路都有自己的block list。
for i in range(len(out_channels)):
self.basic_block_list.append([])
for j in range(num_blocks[i]):
in_ch = in_channels[i] if j == 0 else out_channels[i]
basic_block_func = self.add_sublayer(
"bb_{}_branch_layer_{}_{}".format(name, i + 1, j + 1),
BasicBlock(
num_channels=in_ch,
num_filters=out_channels[i],
has_se=has_se,
name=name + '_branch_layer_' + str(i + 1) + '_' +
str(j + 1)))
self.basic_block_list[i].append(basic_block_func)
def forward(self, x):
outs = []
#遍历输入的多路特征图,执行每一路各自的卷积运算。
for idx, input in enumerate(x):
conv = input
for basic_block_func in self.basic_block_list[idx]:
conv = basic_block_func(conv)
outs.append(conv)
return outs
经过Branches模块卷积运算后,就进入了FuseLayers。FuseLayers的主要作用是将不同尺度的特征图进行融合。按顺序从特征图列表中取出一个特征图,
然后与其他特征图比较,遇到尺寸比自己小的特征图,则将小特征图进行上采样,然后与自己相加。遇到尺寸比自己大的特征图,则使用stride=2的卷积对
特征图进行下采样,然后与自己相加。
FuseLayer的架构图如下:
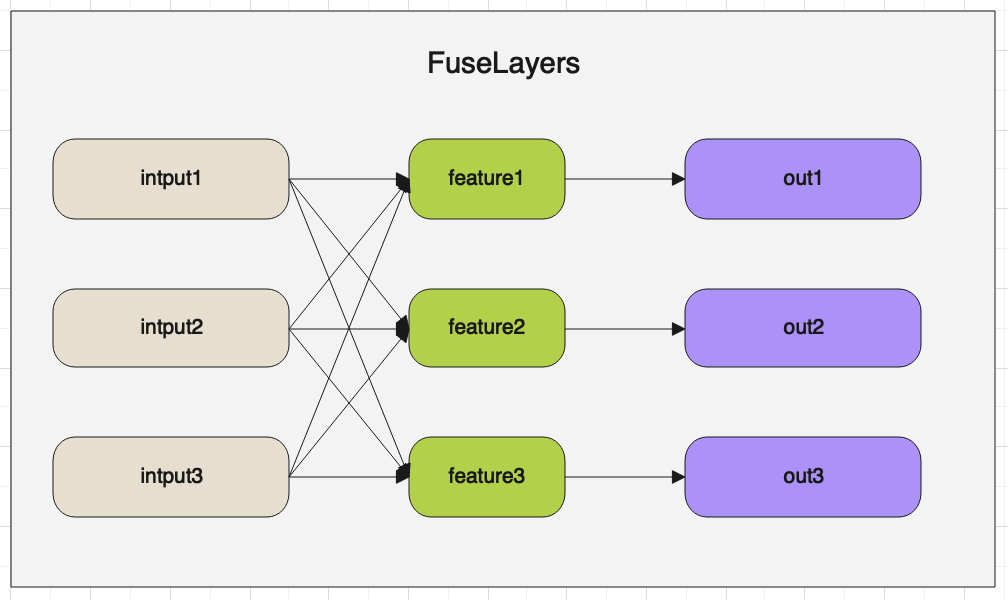
下面解读FuseLayer的代码:
class FuseLayers(nn.Layer):
def __init__(self,
in_channels,
out_channels,
multi_scale_output=True,
name=None,
align_corners=False):
super(FuseLayers, self).__init__()
self._actual_ch = len(in_channels) if multi_scale_output else 1
self._in_channels = in_channels
self.align_corners = align_corners
self.residual_func_list = []
#使用for循环遍历特征图列表
for i in range(self._actual_ch):
#双重循环,进行特征图比较,下标值大的特征图的尺寸小。
for j in range(len(in_channels)):
#遇到下标大的特征图,则说明特征图尺寸小,此处添加一个1x1卷积,进行通道数的统一。
if j > i:
residual_func = self.add_sublayer(
"residual_{}_layer_{}_{}".format(name, i + 1, j + 1),
layers.ConvBN(
in_channels=in_channels[j],
out_channels=out_channels[i],
kernel_size=1,
padding='same',
bias_attr=False))
self.residual_func_list.append(residual_func)
#遇到下标小的特征图,则说明特征图尺寸大,则需要进行创建stride=2的卷积进行1/2的下采样。
elif j < i:
pre_num_filters = in_channels[j]
#因为遇到的j下标特征图可能是当前特征图的2、4、8倍,所以需要使用循环创建多个卷积进行下采样。
for k in range(i - j):
if k == i - j - 1:
residual_func = self.add_sublayer(
"residual_{}_layer_{}_{}_{}".format(
name, i + 1, j + 1, k + 1),
layers.ConvBN(
in_channels=pre_num_filters,
out_channels=out_channels[i],
kernel_size=3,
stride=2,
padding='same',
bias_attr=False))
pre_num_filters = out_channels[i]
else:
residual_func = self.add_sublayer(
"residual_{}_layer_{}_{}_{}".format(
name, i + 1, j + 1, k + 1),
layers.ConvBNReLU(
in_channels=pre_num_filters,
out_channels=out_channels[j],
kernel_size=3,
stride=2,
padding='same',
bias_attr=False))
pre_num_filters = out_channels[j]
self.residual_func_list.append(residual_func)
def forward(self, x):
outs = []
residual_func_idx = 0
for i in range(self._actual_ch):
residual = x[i]
residual_shape = residual.shape[-2:]
for j in range(len(self._in_channels)):
if j > i:
#对特征图进行上采样
y = self.residual_func_list[residual_func_idx](x[j])
residual_func_idx += 1
y = F.interpolate(
y,
residual_shape,
mode='bilinear',
align_corners=self.align_corners)
#与当前i下标的特征图进行融合
residual = residual + y
elif j < i:
y = x[j]
#对特征图进行下采样
for k in range(i - j):
y = self.residual_func_list[residual_func_idx](y)
residual_func_idx += 1
#与当前i下标的特征图进行融合
residual = residual + y
#对特征图进行relu运算
residual = F.relu(residual)
#将特征图添加到输出列表。
outs.append(residual)
return outs
以上就是backbone为HRNet的FCN的模型解读。
PaddleSeg仓库地址:https://github.com/PaddlePaddle/PaddleSeg