本人实验:利用上篇的“Learning Efficient Convolutional Networks Through Network Slimming论文阅读笔记”方法,成功将算力8.5G的darknet21-yolo模型(9个类别)(map=0.74)裁剪掉到了3.9G(map=0.731),最后利用本文的蒸馏方法(下面代码中的蒸馏方法四),蒸馏之后,小模型(map=0.7413)竟然可以超过大模型,非常nice,最终在产品上线。(模型整体准确度偏低的原因是车外场景比较复杂,还要检测行人、标志牌、夜晚等场景)。很值得推荐给大家。
我在一个半月时间内完成了这篇蒸馏和之前一篇剪枝的实验工作,并成功在阿里巴巴智能座舱算法中部署,也因为这个项目,在阿里巴巴季度考核中评得3.75,小小的成就感。
知识蒸馏概述
知识蒸馏(Knowledge Distilling)是模型压缩的一种方法,是指利用已经训练的一个较复杂的Teacher模型,指导一个较轻量的Student模型训练,从而在减小模型大小和计算资源的同时,尽量保持原Teacher模型的准确率的方法。即用一个复杂网络(teacher network)学到的东西去辅助训练一个简单网络(student network)。
背景
引用知乎相关问题的回答粘贴如下,将KD方法的motivation讲的很清楚。
Knowledge Distill是一种简单弥补分类问题监督信号不足的办法。传统的分类问题,模型的目标是将输入的特征映射到输出空间的一个点上,例如在著名的Imagenet比赛中,就是要将所有可能的输入图片映射到输出空间的1000个点上。这么做的话这1000个点中的每一个点是一个one hot编码的类别信息。这样一个label能提供的监督信息只有log(class)这么多bit。然而在KD中,我们可以使用teacher model对于每个样本输出一个连续的label分布,这样可以利用的监督信息就远比one hot的多了。另外一个角度的理解,大家可以想象如果只有label这样的一个目标的话,那么这个模型的目标就是把训练样本中每一类的样本强制映射到同一个点上,这样其实对于训练很有帮助的类内variance和类间distance就损失掉了。然而使用teacher model的输出可以恢复出这方面的信息。具体的举例就像是paper中讲的, 猫和狗的距离比猫和桌子要近,同时如果一个动物确实长得像猫又像狗,那么它是可以给两类都提供监督。综上所述,KD的核心思想在于”打散”原来压缩到了一个点的监督信息,让student模型的输出尽量match teacher模型的输出分布。其实要达到这个目标其实不一定使用teacher model,在数据标注或者采集的时候本身保留的不确定信息也可以帮助模型的训练。
知识蒸馏方式
据迁移的方法不同可以简单分为基于目标蒸馏(也称为Soft-target蒸馏或Logits方法蒸馏)和基于特征蒸馏的算法两个大的方向
1 目标蒸馏-Logits方法
目标蒸馏方法中最经典的论文就是来自于2015年Hinton发表的一篇神作《Distilling the Knowledge in a Neural Network》。下面以这篇神作为例,讲讲目标蒸馏方法的原理。
在这篇论文中,Hinton将问题限定在分类问题下,分类问题的共同点是模型最后会有一个softmax层,其输出值对应了相应类别的概率值,使用softmax层输出的类别的概率来作为“Soft-target” 。
1.1 Hard-target 和 Soft-target
传统的神经网络训练方法是定义一个损失函数,目标是使预测值尽可能接近于真实值(Hard- target),损失函数就是使神经网络的损失值和尽可能小。这种训练过程是对ground truth求极大似然。在知识蒸馏中,是使用大模型的类别概率作为Soft-target的训练过程。

Hard-target:原始数据集标注的 one-shot 标签,除了正标签为 1,其他负标签都是 0。
Soft-target:Teacher模型softmax层输出的类别概率,每个类别都分配了概率,正标签的概率最高。
知识蒸馏用Teacher模型预测的 Soft-target 来辅助 Hard-target 训练 Student模型的方式为什么有效呢?softmax层的输出,除了正例之外,负标签也带有Teacher模型归纳推理的大量信息,比如某些负标签对应的概率远远大于其他负标签,则代表 Teacher模型在推理时认为该样本与该负标签有一定的相似性。而在传统的训练过程(Hard-target)中,所有负标签都被统一对待。也就是说,知识蒸馏的训练方式使得每个样本给Student模型带来的信息量大于传统的训练方式。
如在MNIST数据集中做手写体数字识别任务,假设某个输入的“2”更加形似"3",softmax的输出值中"3"对应的概率会比其他负标签类别高;而另一个"2"更加形似"7",则这个样本分配给"7"对应的概率会比其他负标签类别高。而这两个“2”是不同的,ground-truth标签也应该不同,这样才能体现类内特征,如果只用ground-truth标签,体现不了类内特征。因此,这两个"2"对应的Hard-target的值是相同的,但是它们的Soft-target却是不同的,由此我们可见Soft-target蕴含着比Hard-target更多的信息(就是包含类内特征和类间特征)。

在使用 Soft-target 训练时,Student模型可以很快学习到 Teacher模型的推理过程;而传统的 Hard-target 的训练方式,所有的负标签都会被平等对待。因此,Soft-target 给 Student模型带来的信息量要大于 Hard-target,并且Soft-target分布的熵相对高时,其Soft-target蕴含的知识就更丰富。
1.2 具体方法
在介绍知识蒸馏方法之前,首先得明白什么是Logits。我们知道,对于一般的分类问题,比如图片分类,输入一张图片后,经过DNN网络各种非线性变换,在网络最后Softmax层之前,会得到这张图片属于各个类别的大小数值 ,某个类别的 数值越大,则模型认为输入图片属于这个类别的可能性就越大。什么是Logits? 这些汇总了网络内部各种信息后,得出的属于各个类别的汇总分值 ,就是Logits,i代表第i个类别, 代表属于第i类的可能性。因为Logits并非概率值,所以一般在Logits数值上会用Softmax函数进行变换,得出的概率值作为最终分类结果概率。Softmax一方面把Logits数值在各类别之间进行概率归一,使得各个类别归属数值满足概率分布;另外一方面,它会放大Logits数值之间的差异,使得Logits得分两极分化,Logits得分高的得到的概率值更偏大一些,而较低的Logits数值,得到的概率值则更小。
神经网络使用 softmax 层来实现 logits 向 probabilities 的转换。原始的softmax函数:
但是直接使用softmax层的输出值作为soft target,这又会带来一个问题: 当softmax输出的概率分布熵相对较小时,负标签的值都很接近0,对损失函数的贡献非常小,小到可以忽略不计。因此"温度"这个变量就派上了用场。下面的公式是加了温度这个变量之后的softmax函数:
其中 是每个类别输出的概率, 是每个类别输出的 logits, 就是温度。当温度 时,这就是标准的 Softmax 公式。 越高,softmax的output probability distribution越趋于平滑,其分布的熵越大,负标签携带的信息会被相对地放大,模型训练将更加关注负标签。

蒸馏过程的目标函数由distill loss(对应Soft-target)和Student loss(对应Hard-target)加权得到。如下所示:
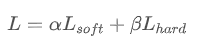
1.对于分类网络来说,原始的softmax函数:
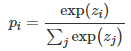
蒸馏通过引入温度因子T来控制每个软目标的重要性,
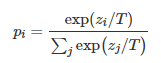
其中,当T=1时,就是普通的softmax变换。这里令T>1,就得到了软化的softmax。(这个很好理解,除以一个比1大的数,相当于被squash了,线性的sqush被指数放大,差距就不会这么大了)。得到的soft target,相比于one-hot的ground truth或softmax的prob输出,这个软化之后的target能够提供更多的类别间和类内信息。

hard loss(ground truth)是和真实标签的loss,一般是交叉熵loss。
soft loss(teacher prediction)一般是kdloss:
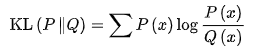
P代码teacher模型的概率分布,Q代表学生模型的概率分布,当P和Q越相近,KL损失值越趋于0.
2 特征蒸馏
另外一种知识蒸馏思路是特征蒸馏方法,Student学习Teacher网络结构中的中间层特征。最早采用这种模式的工作来自于论文《FITNETS:Hints for Thin Deep Nets》,它强迫Student某些中间层的网络响应,要去逼近Teacher对应的中间层的网络响应。这种情况下,Teacher中间特征层的响应,就是传递给Student的知识。一般的方法是计算两个feature map的MSEloss。

YOLOv3检测蒸馏
和分类和分割蒸馏的差异:
由于YOLOv3检测框的位置输出为正无穷到负无穷的连续值,和上面将的分类离散kdloss不同,而且由于yolo是基于anchor的one stage模型,head out中99%都是背景预测。
Object detection at 200 Frames Per Second论文中指出,
直接在Yolo算法中引入distillation loss会有一些问题,因为目前的network distillation算法主要是针对RCNN系列的object detection算法(或者叫two stage系列)。对于two stage的object detection算法而言,其最后送给检测网络的ROI数量是很少的(默认是128个),而且大部分都是包含object的bbox,因此针对这些bbox引入distillation loss不会有太大问题。但是对于Yolo这类one stage算法而言,假设feature map大小是1313,每个grid cell预测5个bbox,那么一共就会生成1313*5=845个bbox,而且大部分都是背景(background)。如果将大量的背景区域传递给student network,就会导致网络不断去回归这些背景区域的坐标以及对这些背景区域做分类,这样训练起来模型很难收敛。因此,作者利用Yolo网络输出的objectness对distillation loss做一定限定,换句话说,只有teacher network的输出objectness较高的bbox才会对student network的最终损失函数产生贡献,这就是objectness scaled distillation。
原来Yolo算法的损失函数,包含3个部分(公式1):1、objectness loss,表示一个bbox是否包含object的损失;2、classification loss,表示一个bbox的分类损失;3、regression loss,表示一个bbox的坐标回归损失。
Yolo损失:回归损失+目标损失+分类损失,核心的算法如下图:

下面贴一下在mmdetection框架下的pytorch蒸馏代码(供参考):
train_distill.py
import argparse
import copy
import os
import os.path as osp
import time
import mmcv
import torch
from mmcv.runner import init_dist
from mmcv.utils import Config, DictAction, get_git_hash
from mmdet import __version__
from mmdet.datasets import build_dataset
from mmdet.models import build_detector
from mmdet.utils import collect_env, get_root_logger
import random
import numpy as np
import torch
from mmcv.parallel import MMDataParallel, MMDistributedDataParallel
from mmcv.runner import IterBasedRunner, build_optimizer
from mmdet.core import DistEvalHook, EvalHook
from mmdet.datasets import build_dataloader, build_dataset
from mmdet.utils import get_root_logger
from mmcv.runner import load_checkpoint
from mmdet.apis import multi_gpu_test, single_gpu_test
from mmcv.runner.checkpoint import save_checkpoint, weights_to_cpu, get_state_dict
from mmdet.models.losses.kd_loss import *
from utils.criterion import CriterionDSN, CriterionCE, CriterionPixelWise,CriterionKD, \
CriterionAdv, CriterionAdvForG, CriterionAdditionalGP, CriterionPairWiseforWholeFeatAfterPool,CriterionIFV
from utils.train_options import TrainOptions
from mmdet.core import get_classes
import torch.optim as optim
import os
CUDA_DEVECE = 1
CUDA_DEVECE_S = 'cuda:1'
def init_detector(config, checkpoint=None, device=CUDA_DEVECE_S):
"""Initialize a detector from config file.
Args:
config (str or :obj:`mmcv.Config`): Config file path or the config
object.
checkpoint (str, optional): Checkpoint path. If left as None, the model
will not load any weights.
Returns:
nn.Module: The constructed detector.
"""
if isinstance(config, str):
config = mmcv.Config.fromfile(config)
elif not isinstance(config, mmcv.Config):
raise TypeError('config must be a filename or Config object, '
f'but got {type(config)}')
config.model.pretrained = None
model = build_detector(config.model, test_cfg=config.test_cfg)
if checkpoint is not None:
map_loc = 'cpu' if device == 'cpu' else None
checkpoint = load_checkpoint(model, checkpoint, map_location=CUDA_DEVECE_S)
if 'CLASSES' in checkpoint['meta']:
model.CLASSES = checkpoint['meta']['CLASSES']
else:
model.CLASSES = get_classes('coco')
model.cfg = config # save the config in the model for convenience
# model = nn.DataParallel(model, device_ids=[0, 1])
model = model.cuda(CUDA_DEVECE)
#model.to(torch.cuda.current_device())
model.to(CUDA_DEVECE)
model.eval()
return model
# def lr_poly(base_lr, iter, max_iter, power=0.9, min_lr=0):
# # return base_lr*((1-float(iter)/max_iter)**(power))
# coeff = (1 - float(iter) / max_iter) ** power
# return (base_lr - min_lr) * coeff + min_lr
# def adjust_learning_rate(base_lr, optimizer, i_iter):
# lr = lr_poly(base_lr, i_iter, cfg.total_iters, cfg.lr_config.power, cfg.lr_config.min_lr)
# optimizer.param_groups[0]['lr'] = lr
# return lr
def lr_poly(base_lr, iter, max_iter, power=0.9, min_lr=0):
# return base_lr*((1-float(iter)/max_iter)**(power))
coeff = (1 - float(iter) / max_iter) ** power
return (base_lr - min_lr) * coeff + min_lr
def adjust_learning_rate(base_lr, optimizer, epoch):
lr = lr_poly(base_lr, epoch, MAX_EPOCH, 0.9, 1e-06)
optimizer.param_groups[0]['lr'] = lr
return lr
args = TrainOptions().initialize()
config='configs/yolov3_multitask/yolov3_tevs2d_darknet21_singlehead_zs_distill.py'
#config=args.config
cfg = Config.fromfile(config)
cfg.gpu_ids = [CUDA_DEVECE]
cfg.seed = None
if args.work_dir:
cfg.work_dir = args.work_dir
# print(cfg)
# print(cfg.pretty_text)
# create work_dir
mmcv.mkdir_or_exist(osp.abspath(cfg.work_dir))
# dump config
# cfg.dump(osp.join(cfg.work_dir, osp.basename(args.config)))
# init the logger before other steps
timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime())
log_file = osp.join(cfg.work_dir, f'{timestamp}.log')
logger = get_root_logger(log_file=log_file, log_level=cfg.log_level)
# init the meta dict to record some important information such as
# environment info and seed, which will be logged
meta = dict()
# log env info
env_info_dict = collect_env()
env_info = '\n'.join([f'{k}: {v}' for k, v in env_info_dict.items()])
dash_line = '-' * 60 + '\n'
logger.info('Environment info:\n' + dash_line + env_info + '\n' +
dash_line)
meta['env_info'] = env_info
# log some basic info
distributed = False
logger.info(f'Distributed training: {distributed}')
logger.info(f'Config:\n{cfg.pretty_text}')
student_model = build_detector(cfg.model, train_cfg=cfg.train_cfg, test_cfg=cfg.test_cfg)
student_model.cuda(CUDA_DEVECE)
checkpoint = load_checkpoint(student_model, cfg.load_from, map_location=CUDA_DEVECE_S)
student_model_paral = MMDataParallel(student_model, device_ids=[CUDA_DEVECE])
#train_dataset = build_dataset(cfg.data.train)
train_dataset = [build_dataset(ds) for ds in cfg.data.train.datasets]
train_data_loader = build_dataloader(
train_dataset[0],
cfg.data.samples_per_gpu, # samples_per_gpu
cfg.data.workers_per_gpu, # workers_per_gpu
len(cfg.gpu_ids),
dist=False,
seed=cfg.seed,
drop_last=False
)
#val_dataset = build_dataset(cfg.data.test)
val_dataset = [build_dataset(ds) for ds in cfg.data.test.datasets]
val_data_loader = build_dataloader(
val_dataset[0],
samples_per_gpu=4,
workers_per_gpu=4,
# workers_per_gpu=S_cfg.data.workers_per_gpu,
dist=False,
shuffle=False,
drop_last=False,
)
G_solver = optim.SGD(
[{'params': filter(lambda p: p.requires_grad, student_model.parameters()), 'initial_lr': cfg.optimizer.lr}],
lr=cfg.optimizer.lr,
momentum=cfg.optimizer.momentum,
weight_decay=cfg.optimizer.weight_decay)
#scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(G_solver, T_0=20, T_mult=1,eta_min=1e-07)
#torch.optim.lr_scheduler.StepLR
teacher_models = init_detector(cfg.teacher_cfg.teacher_config_file, cfg.teacher_cfg.teacher_checkpoint)
criterion_kd = CriterionKD()
criterion_kd1 = CriterionKD(reduction = 'none')
#蒸馏方法一
def distillation_output_kdloss(outs, soft_outs):
lambda_pi = 10
loss_kd = 0
loss_kd = sum(list(map(criterion_kd,outs[0],soft_outs[0])))
return lambda_pi * loss_kd
#蒸馏方法二
def distillation_outputclass_kdloss(outs, soft_outs):
lambda_pi = 1
loss_kd = 0
for index in range(len(outs[0])):
loss_kd += criterion_kd(outs[0][index][:,5:13,:,:],soft_outs[0][index][:,5:13,:,:])
loss_kd += criterion_kd(outs[0][index][:,18:26,:,:],soft_outs[0][index][:,18:26,:,:])
loss_kd += criterion_kd(outs[0][index][:,31:39,:,:],soft_outs[0][index][:,31:39,:,:])
loss_kd = lambda_pi * loss_kd
return loss_kd
#蒸馏方法三
def distillation_outputclass_mulobjectness_kdloss(outs, soft_outs):
lambda_pi = 1
loss_kd = 0
for index in range(len(outs[0])): # scale index
for anchor_index in range(3): # anchor index
loss_temp = criterion_kd1(outs[0][index][:,5+anchor_index*13:13+anchor_index*13,:,:],soft_outs[0][index][:,5+anchor_index*13:13+anchor_index*13,:,:])
loss_objectness = torch.sigmoid(soft_outs[0][index][:,4+anchor_index*13,:,:].unsqueeze(1)).ge(cfg.test_cfg.conf_thr*10)
objectness_num = loss_objectness.sum()
loss_temp_a = loss_objectness.repeat(1,8,1,1) * loss_temp
loss_temp_a = loss_temp_a.sum()/objectness_num
loss_kd += loss_temp_a
loss_kd = lambda_pi * loss_kd
return loss_kd
#蒸馏方法四
def distillation_output_MSEloss(outs, soft_outs):
lambda_pi = 10
loss_distillation = 0
# pi = []
# t_pi = []
t_lcls , t_lbox, t_lobj = 0, 0, 0
DboxLoss = nn.MSELoss(reduction="none")
DclsLoss = nn.MSELoss(reduction="none")
DobjLoss = nn.MSELoss(reduction="none")
for index in range(len(outs[0])):
num_grid_h = outs[0][index].size(2)
num_grid_w = outs[0][index].size(3)
pi = outs[0][index].view(-1,3,13,num_grid_h,num_grid_w).permute(0, 1, 3, 4, 2).contiguous()
t_pi = soft_outs[0][index].view(-1,3,13,num_grid_h,num_grid_w).permute(0, 1, 3, 4, 2).contiguous()
t_obj_scale = t_pi[..., 4].sigmoid()
# BBox
b_obj_scale = t_obj_scale.unsqueeze(-1).repeat(1, 1, 1, 1, 4)
t_lbox += torch.mean(DboxLoss(pi[..., :4], t_pi[..., :4]) * b_obj_scale)
# Class
c_obj_scale = t_obj_scale.unsqueeze(-1).repeat(1, 1, 1, 1, 8)
t_lcls += torch.mean(DclsLoss(pi[..., 5:], t_pi[..., 5:]) * c_obj_scale)
#objectness
t_lobj += torch.mean(DobjLoss(pi[..., 4], t_pi[..., 4]) * t_obj_scale)
loss_distillation = t_lbox + t_lcls + t_lobj
loss_distillation = lambda_pi * loss_distillation
return loss_distillation
#蒸馏方法五
def distillation_feature_MSEloss(s_f, t_f):
loss_func1 = nn.MSELoss(reduction="mean")
loss_func2 = nn.MSELoss(reduction="mean")
loss_func3 = nn.MSELoss(reduction="mean")
feature_loss = 0
dl_1 , dl_2, dl_3 = 0, 0, 0
dl_1 += loss_func1(s_f[0], t_f[0])
dl_2 += loss_func2(s_f[1], t_f[1])
dl_3 += loss_func3(s_f[2], t_f[2])
feature_loss += (dl_1 + dl_2 + dl_3) * 2
return feature_loss
# train
MAX_EPOCH = 100
# 以epoch为周期,在每个epoch中会有多个iteration的训练,在每一个iteration中训练模型
for epoch in range(MAX_EPOCH):
student_model.train()
for i, data in enumerate(train_data_loader):
info_text = ''
info_text += 'epoch:[{:5d}] /step:[{:5d}] G_lr:[{:.6f}]'.format(epoch+1, i, G_solver.param_groups[-1]['lr'])
G_loss = 0
img = data['img'].data
img_metas = data['img_metas'].data # img_metas = [1,batchsize]
gt_bboxes = data['gt_bboxes'].data # gt_bboxes = [1, batchsize, boxnums, 4]
gt_labels = data['gt_labels'].data # gt_labels = [1, batchsize, boxnums]
img = img[0].cuda(CUDA_DEVECE)
#gt_bboxes = torch.Tensor([(gt_bbox.cpu().detach().numpy()) for gt_bbox in gt_bboxes[0]]).cuda(3)
#gt_bboxes = torch.Tensor(gt_bboxes)[0].cuda(3)
#gt_labels = torch.Tensor(gt_labels)[0].cuda(3)
preds_S = [0, 0, 0]
x = student_model.extract_feat(img)
outs = student_model.bbox_head(x)
loss_inputs = outs + (gt_bboxes[0], gt_labels[0], img_metas[0])
losses = student_model.bbox_head.loss(*loss_inputs, gt_bboxes_ignore=None)
#losses = model.forward_train(img,img_metas[0],gt_bboxes[0],gt_labels[0])
G_loss = sum(_value for _key, _value in losses.items() if 'loss' in _key)
info_text += ' gt_loss:{:.6f} '.format(G_loss)
with torch.no_grad():
soft_x = teacher_models.extract_feat(img)
soft_outs = teacher_models.bbox_head(soft_x) #dim =N*(class+1+4)*h*w
#soft_target = teacher_models(return_loss=False,rescale=True,img=[img],img_metas=[img_metas[0]]) #this is correct
soft_output_loss =distillation_outputclass_mulobjectness_kdloss(outs, soft_outs)
G_loss += soft_output_loss
info_text += ' soft_loss:[{:.6f}] '.format(soft_output_loss)
# soft_feature_loss = distillation_feature_MSEloss(x,soft_x)
# G_loss += soft_feature_loss
# info_text += ' soft_loss:[{:.6f}] '.format(soft_feature_loss)
info_text += ' G_loss:[{:.6f}] '.format(G_loss)
if i % 40 == 0:
logger.info(info_text)
# backward
lr_g = adjust_learning_rate(cfg.optimizer.lr, G_solver, epoch)
G_solver.zero_grad()
G_loss.backward()
G_solver.step()
if epoch % 4 == 0 and epoch != -1:
outputs = single_gpu_test(student_model_paral, val_data_loader, show=False, out_dir=None)
kwargs = {}
eval_results = val_dataset[0].evaluate(outputs, metric='mAP', **kwargs)
#mAP = eval_results['{}_mAP'.format(epoch)]
mAP = eval_results['mAP']
# {'mIoU': 0.4836061652681801, 'mAcc': 0.5740488995020039, 'aAcc': 0.9015018912774634}
logger.info('Epoch(val) [{:d}] mAP: {:.4f},'.format(
epoch+1, eval_results['mAP']))
filename = 'epoch_{:d}.pth'.format(epoch + 1) # epoch_20000.pth
filepath = os.path.join(cfg.work_dir, filename)
save_checkpoint(student_model, filepath, optimizer=None, meta=None)
yolov3_tevs2d_darknet21_singlehead_zs_distill.py
input_size = (512, 192)
num_classes = 8
model = dict(
type='YoloNet_BM',
# pretrained='./work_dirs/det_hrwu_3branch.pth',
backbone=dict(type='DarkNetPrunning21',
in_channels=(3, 26, 44, 84, 80, 26),
out_channels=(26, 44, 84, 80, 26, 52), #(32, 64, 128, 256, 512, 1024),
mid_channels=(26, 52, 104, 104, 122, 130, 26), #(32, 64, 128, 128, 256, 256, 512),
freeze=False),
neck=dict(
type='YoloNeckPrunning',
in_channels=[52, 512, 256],
route_channels=[52, 26, 80], #[1024, 512, 256],
out_channels=[
# [172, 80, 48, 512, 360, 360], [180, 180, 180, 180, 180], [90, 90, 90, 90, 92]
(512, 512, 512, 512, 512, 512),
(256, 256, 256, 256, 256),
(128, 128, 128, 128, 128)
],
Upsample_mode='deconv',
Upsample_reduced=True,
spp_enable=True,
freeze=False),
bbox_head=dict(
type='YoloHead_BM',
num_classes=num_classes,
in_channels=[512, 256, 128],
out_channels=[512, 256, 128],
strides=[32, 16, 8],
anchor_base_sizes=[[[24.0, 18.0], [43.0, 32.0], [98.0, 75.0]],
[[10.0, 7.0], [17.0, 9.0], [12.0, 15.0]],
[[3.0, 7.0], [6.0, 5.0], [5.0, 11.0]]],
scale_x_y=2.0)
)
train_cfg = dict(
one_hot_smoother=0.01,
ignore_thresh=0.7,
xy_use_logit=False,
balance_conf=False,
IOU_loss=True,
syncBN=False,
RandomShape=True,
EMA=False,
multi_anchor=True,
anchor_iou_thresh=0.5,
cross_grid=True,
debug=False)
test_cfg = dict(
nms_pre=1000,
min_bbox_size=0,
score_thr=0.05,
conf_thr=0.005,
nms=dict(type='nms', iou_thr=0.45),
max_per_img=100)
dataset_type = 'DDPDataset'
data_root = '/mnt/sdb/dataset/BMDD/Target/'
name = '512X192'
x = 1
work_dir = './work_dirs/tevs2d_8155_distill_512X192_kdloss_7222test'
img_norm_cfg = dict(mean=[0, 0, 0], std=[255.0, 255.0, 255.0], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile', to_float32=True),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='UserSettingCrop', rightbottom=(1920, 860), lefttop=(0, 140)),
dict(type='PhotoMetricDistortion'),
dict(type='Expand', mean=[0, 0, 0], to_rgb=True, ratio_range=(1, 2)),
dict(
type='MinIoURandomCrop',
min_ious=(0.4, 0.5, 0.6, 0.7, 0.8, 0.9),
min_crop_size=0.3),
dict(type='Resize', img_scale=[(448, 160), (768, 288)], keep_ratio=False),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='Normalize',
mean=[0, 0, 0],
std=[255.0, 255.0, 255.0],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(
type='Collect',
keys=['img', 'gt_bboxes', 'gt_labels'],
meta_keys=[
'filename', 'ori_shape', 'img_shape', 'pad_shape', 'scale_factor',
'flip', 'flip_direction', 'img_norm_cfg'
])
]
test_pipeline = [
dict(type='LoadImageFromFile', to_float32=True),
dict(
type='MultiScaleFlipAug',
img_scale=(512, 192),
flip=False,
transforms=[
dict(
type='UserSettingCrop',
rightbottom=(1920, 860),
lefttop=(0, 140)),
dict(type='Resize', keep_ratio=False),
dict(
type='Normalize',
mean=[0, 0, 0],
std=[255.0, 255.0, 255.0],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(
type='Collect',
keys=['img'],
meta_keys=[
'filename', 'ori_shape', 'img_shape', 'pad_shape',
'scale_factor', 'img_norm_cfg', 'crop_lefttop',
'crop_rightbottom'
])
])
]
data = dict(
samples_per_gpu=64,
workers_per_gpu=8,
train=dict(
datasets=[dict(
type='DDPDataset',
ann_file=data_root+'train_8.txt',
img_prefix=None,
num_classes=num_classes,
pipeline=[
dict(type='LoadImageFromFile', to_float32=True),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='UserSettingCrop',
rightbottom=(1920, 860),
lefttop=(0, 140)),
dict(type='PhotoMetricDistortion'),
dict(
type='Expand', mean=[0, 0, 0], to_rgb=True,
ratio_range=(1, 2)),
dict(
type='MinIoURandomCrop',
min_ious=(0.4, 0.5, 0.6, 0.7, 0.8, 0.9),
min_crop_size=0.3),
dict(
type='Resize',
img_scale=[(448, 160), (768, 288)],
keep_ratio=False),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='Normalize',
mean=[0, 0, 0],
std=[255.0, 255.0, 255.0],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(
type='Collect',
keys=['img', 'gt_bboxes', 'gt_labels'],
meta_keys=[
'filename', 'ori_shape', 'img_shape', 'pad_shape',
'scale_factor', 'flip', 'flip_direction', 'img_norm_cfg'
])
])
],
intervals=[1]
),
val=dict(
datasets=[dict(
type='DDPDataset',
ann_file=data_root+'test_8.txt',
img_prefix=None,
num_classes=num_classes,
pipeline=[
dict(type='LoadImageFromFile', to_float32=True),
dict(
type='MultiScaleFlipAug',
img_scale=(512, 192),
flip=False,
transforms=[
dict(
type='UserSettingCrop',
rightbottom=(1920, 860),
lefttop=(0, 140)),
dict(type='Resize', keep_ratio=False),
dict(
type='Normalize',
mean=[0, 0, 0],
std=[255.0, 255.0, 255.0],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(
type='Collect',
keys=['img'],
meta_keys=[
'filename', 'ori_shape', 'img_shape', 'pad_shape',
'scale_factor', 'img_norm_cfg', 'crop_lefttop',
'crop_rightbottom'
])
]
)
]
)]
),
test=dict(
datasets=[dict(
type='DDPDataset',
ann_file=data_root+'test_8.txt',
img_prefix=None,
num_classes=num_classes,
pipeline=[
dict(type='LoadImageFromFile', to_float32=True),
dict(
type='MultiScaleFlipAug',
img_scale=(512, 192),
flip=False,
transforms=[
dict(
type='UserSettingCrop',
rightbottom=(1920, 860),
lefttop=(0, 140)),
dict(type='Resize', keep_ratio=False),
dict(
type='Normalize',
mean=[0, 0, 0],
std=[255.0, 255.0, 255.0],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(
type='Collect',
keys=['img'],
meta_keys=[
'filename', 'ori_shape', 'img_shape', 'pad_shape',
'scale_factor', 'img_norm_cfg', 'crop_lefttop',
'crop_rightbottom'
])
]
)
]
)]
)
)
optimizer = dict(type='SGD', lr=1e-3, momentum=0.9, weight_decay=0.0005)
optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))
# optimizer_config = dict(type='MTOptimizerHook',
# # mtl_cfg = dict(type='DWA', T=5, alpha=0.9),
# bn_sparse_cfg=dict(type='BNSparse',
# sr_flag=True, s=0.001,
# prune_keys=['backbone\..*\.conv1\..*',
# 'backbone\..*\.conv2\..*',
# 'backbone\..*\.conv\..*',
# #'neck\.detect[1-3]\.conv[1-5]\..*'
# ],
# ignore_names=[],
# steps=10,
# log_dir=work_dir+'/bn_weights'),
# grad_clip=dict(max_norm=35, norm_type=2))
lr_config = dict(
policy='CosineAnnealing',
min_lr=1e-07,
warmup='linear',
warmup_iters=20,
warmup_ratio=0.1)
checkpoint_config = dict(interval=5)
log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
total_epochs = 180
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = '/home/szhang/project/git/mmdetection-dev/work_dirs/tevs2d_8155_bn_opt_512X192_sparse_0.7_epoch88_3.94G/epoch_152.pth'
resume_from = None
workflow = [('train', 1)]
checkpoint = work_dir + '/latest.pth'
evaluation = [
dict(interval=5),
]
gpu_ids = range(0, 4)
teacher_cfg = dict(
teacher_config_file='/home/szhang/project/git/mmdetection-dev/configs/nanodet/darknet21_mAP74/yolov3_darknet21_reduceNeck_Head_class8.py',
teacher_checkpoint ='/home/szhang/project/git/mmdetection-dev/configs/nanodet/darknet21_mAP74/yolov3_darknet21_reduceNeck_Head_class8_74.1mAP.pth',
)