深度学习面临的非常严重的一个问题就是过拟合(overfitting)。通过一些正则化的方法,可以消除过拟合,从而使我们的模型能够得到更好的效果。
1. 什么是正则化
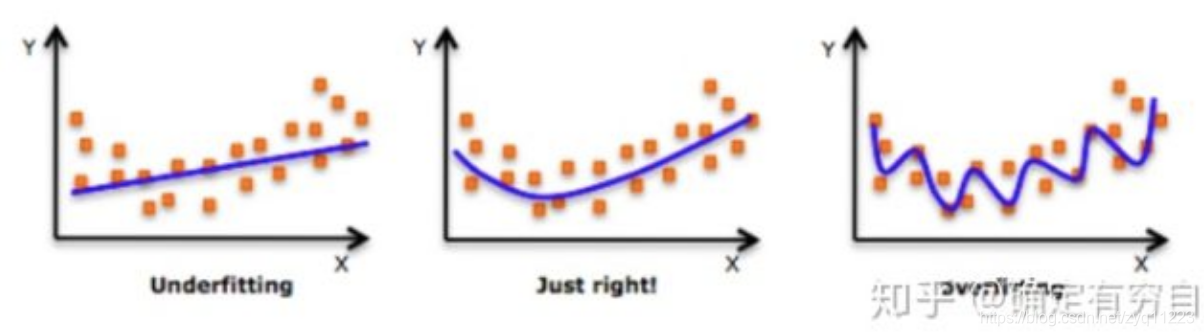
这张图,我想接触过机器学习的朋友们应该都看了很多遍了吧。
我们先从回归的角度来看待上图。假设坐标系内有一系列的点,我们希望通过一个函数来拟合出一条线,使得这条线能尽可能的贴近这些点,从而可以用这条线(也就是我们得到的模型)来表示坐标系中的点。上图中从左往右的情况依次为欠拟合,拟合的刚刚好,以及过拟合。
欠拟合:表示模型的参数过于简单(比如,你用一个一次函数的模型公式去拟合一个二次函数,出来的效果肯定是非常差的),无法很好的反应坐标系中点的分布情况。
拟合的刚刚好:这个是最理想的情况,我们所拟合出来的模型,基本上能够反应样本的分布情况,并且不会受到样本的误差的影响。
过拟合:表示我们拟合出的模型,能够非常完美的模拟样本的分布,但是,也把样本的误差等一系列因素都拟合了进去。这种情况一般会导致模型在训练集上效果很好,一旦转移到测试集,效果就会下降很多。因为模型在训练集上发生了过拟合,导致模型的泛化能力大大下降。

如上图所示,当发生或拟合的时候,样本在训练集上的损失error还可以持续下降,但是在测试集上的error却增加了,表示模型更差了。这就是因为模型发生了过拟合,导致其泛化能力下降,最终的结果就是虽然训练集上效果越来越好,但是在测试集上反而效果越来越差了。
为什么会有过拟合的产生,就是因为深度学习的模型中,参数实在太多,模型实在太复杂了。这么多的参数和这么庞大的模型,有的时候可以非常完美的拟合出符合训练集的模型,但是这种过分贴近训练集的模型,反而在测试集上效果太差。
这个时候,就需要用一些手段防止模型的过拟合,这个时候,正则化就派上用处了。
2. L1和L2正则化
L1正则化和L2正则化非常类似,所以就放在一起说。这两个正则化的方法,就是在损失函数中添加一项,来防止过拟合。
添加上正则化项以后,模型的参数的数值就会变小,通常来讲,模型中的参数的数值越小,模型越趋向于简单,所以,可以通过这种方式防止过拟合。
L2正则化为:
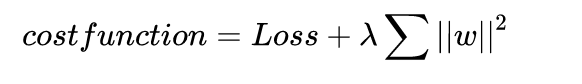
这里的
λ
\lambda
λ 是一个超参数,需要人为的指定,通过控制
λ
\lambda
λ 的大小,可以控制前面的损失项和正则化项所占的比例。通过加入这个L2正则化项,会使得模型中的参数的数值趋近于0.(但不是0)
L1正则化为:
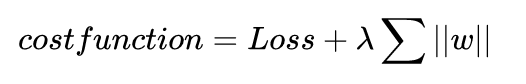
在这个公式中,我们直接用权值的绝对值来对模型进行惩罚,使得模型不要太拟合于训练集。和L2不同的是,此时的权值很可能最终会是0。当我们想要压缩模型的时候,采用L1正则化非常的合适。否则,其他情况我们通常更多的使用L2.
3. Dropout
dropout,说白了就是让一些参数失效。具体我们举例说明。假设一个神经网络模型结构如下图所示:

在训练的每次循环中,我们随机的将一些参数进行隐藏,说白了就是将这些参数的值置为0。此时的网络,可能就如下图所示

此时的网络,相比于最初的网络,就显得没有那么复杂了,从而可以减少过拟合的发生。dropout的细节是,在训练网络的过程中(检测阶段是没有dropout这个过程中,检测阶段所有神经元都参与计算),每一次的训练,都随机的选取一部分点,将这些点的值置为0。
由于在每次的训练过程中,被隐藏的点都不一样,所以,我们也可以看成dropout使得该网络从一个网络变成了多个网络的累加。因为每一次训练,都隐藏了不同的权值,相当于都是一个新的网络。通过多次训练,相当于将不同的网络进行了叠加。
一般来讲,叠加而成的组合网络,一般优于单一网络,因为组合网络能够捕捉到更多的随机因素。同样的,采用了dropout以后,网络的性能一般也比没有使用dropout的网络要好。
4. data augmentation(数据增强)
之所以会发生过拟合,是因为模型的参数太多,可以用于训练的数据太少,所以除了更改模型的一些性质之外,也可以尝试增加训练数据的数量。
以计算机视觉中的图像分类举例,如下图所示

假设我的训练数据中,只有一张猫的图片,如上图左侧所示。但是,我们可以通过翻转,裁切,旋转,平移甚至高斯模糊等各种手段,用这一张图片生成很多张猫的图片,如上图右边所示。这些生成的图片,和原图片同属于一个类别,通过这种方法,可以大大的提高数据量,从而也可以防止过拟合。
5. early stopping(早点停止?我也不知道该怎么翻译,反正大家理解意思就好)

在训练的过程中,可以将训练集的一部分分出来,作为验证集,然后在训练过程中,同时观察error在训集上和验证集上的大小,如上图所示。当发现训练集上error在持续减小,但是验证集上的error不再减小反而增大的时候,就表示该模型可能对训练集发生了过拟合,这个时候,就可以停止训练了。
在验证集error最小的时候停止训练,从而可以得到一个最好的效果。
参考:
https://zhuanlan.zhihu.com/p/44363288
https://www.jiqizhixin.com/articles/2017-12-20