Git之前一直听说没有自己操作过,偶尔写完程序的时候想起要不放到GitHub上,然后看到操作也不简单呢。然后还是不想放弃,听了【莫烦Python】Git 代码版本管理教程听了一遍没动手,就放到一边了。看面经他们说一般需要把你的作品放到这个上面让面试官看,想到这个还是要操作一下的。去面试,面试官小哥哥问道了这个,不会。所以都是要学的,快点开始吧
确实不难的,加油吧,记录方便交流以及复习
结合视频和文档学习起来事半功倍,发了狂神讲的不错,会讲解原理让你更容易懂,我看其他的好多直接让你进行操作
为什么要用Git?
版本控制
版本控制(Revision control)是一种在开发的过程中用于管理我们对文件、目录或工程等内容的修改历史,方便查看更改历史记录,备份以便恢复以前的版本的软件工程技术。
-
实现跨区域多人协同开发
-
追踪和记载一个或者多个文件的历史记录
-
组织和保护你的源代码和文档
-
统计工作量
-
并行开发、提高开发效率
-
跟踪记录整个软件的开发过程
-
减轻开发人员的负担,节省时间,同时降低人为错误
简单说就是用于管理多人协同开发项目的技术。
没有进行版本控制或者版本控制本身缺乏正确的流程管理,在软件开发过程中将会引入很多问题,如软件代码的一致性、软件内容的冗余、软件过程的事物性、软件开发过程中的并发性、软件源代码的安全性,以及软件的整合等问题。
无论是工作还是学习,或者是自己做笔记,都经历过这样一个阶段!我们就迫切需要一个版本控制工具!

主流的版本控制器
-
Git
-
SVN(Subversion)
-
CVS(Concurrent Versions System)
-
VSS(Micorosoft Visual SourceSafe)
-
TFS(Team Foundation Server)
-
Visual Studio Online
版本控制产品非常的多(Perforce、Rational ClearCase、RCS(GNU Revision Control System)、Serena Dimention、SVK、BitKeeper、Monotone、Bazaar、Mercurial、SourceGear Vault),现在影响力最大且使用最广泛的是Git与SVN
Git与SVN
Git 与 SVN 区别点:
-
1、Git 是分布式的,SVN 不是:这是 Git 和其它非分布式的版本控制系统,例如 SVN,CVS 等,最核心的区别。
-
2、Git 把内容按元数据方式存储,而 SVN 是按文件:所有的资源控制系统都是把文件的元信息隐藏在一个类似 .svn、.cvs 等的文件夹里。
-
3、Git 分支和 SVN 的分支不同:分支在 SVN 中一点都不特别,其实它就是版本库中的另外一个目录。
-
4、Git 没有一个全局的版本号,而 SVN 有:目前为止这是跟 SVN 相比 Git 缺少的最大的一个特征。
-
5、Git 的内容完整性要优于 SVN:Git 的内容存储使用的是 SHA-1 哈希算法。这能确保代码内容的完整性,确保在遇到磁盘故障和网络问题时降低对版本库的破坏。
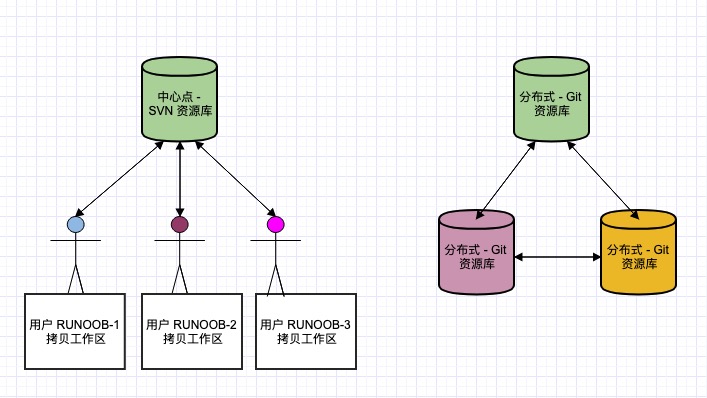
Git是什么
Git 是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。
Git 是 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。
Git 与常用的版本控制工具 CVS, Subversion 等不同,它采用了分布式版本库的方式,不必服务器端软件支持。
Git安装配置
Windows 平台上安装
在 Windows 平台上安装 Git 同样轻松,有个叫做 msysGit 的项目提供了安装包,可以到 GitHub 的页面上下载 exe 安装文件并运行:
安装包下载地址:https://gitforwindows.org/
官网慢,可以用国内的镜像:https://npm.taobao.org/mirrors/git-for-windows/。
在 Mac 平台上安装 Git 最容易的当属使用图形化的 Git 安装工具,下载地址为:
http://sourceforge.net/projects/git-osx-installer/

完成安装之后,就可以使用命令行的 git 工具(已经自带了 ssh 客户端)了,另外还有一个图形界面的 Git 项目管理工具。
在开始菜单里找到"Git"->"Git Bash",会弹出 Git 命令窗口,你可以在该窗口进行 Git 操作。
Git CMD:Windows风格的命令行
Git GUI:图形界面的Git,不建议初学者使用,尽量先熟悉常用命令
Git配置
Git 提供了一个叫做 git config 的工具,专门用来配置或读取相应的工作环境变量。
这些环境变量,决定了 Git 在各个环节的具体工作方式和行为。这些变量可以存放在以下三个不同的地方:
/etc/gitconfig 文件:系统中对所有用户都普遍适用的配置。若使用 git config 时用 --system 选项,读写的就是这个文件。~/.gitconfig 文件:用户目录下的配置文件只适用于该用户。若使用 git config 时用 --global 选项,读写的就是这个文件。- 当前项目的 Git 目录中的配置文件(也就是工作目录中的
.git/config 文件):这里的配置仅仅针对当前项目有效。每一个级别的配置都会覆盖上层的相同配置,所以 .git/config 里的配置会覆盖 /etc/gitconfig 中的同名变量。
在 Windows 系统上,Git 会找寻用户主目录下的 .gitconfig 文件。主目录即 $HOME 变量指定的目录,一般都是 C:\Documents and Settings\$USER。
此外,Git 还会尝试找寻 /etc/gitconfig 文件,只不过看当初 Git 装在什么目录,就以此作为根目录来定位。
设置用户名与邮箱(用户标识,必要)
当你安装Git后首先要做的事情是设置你的用户名称和e-mail地址。这是非常重要的,因为每次Git提交都会使用该信息。它被永远的嵌入到了你的提交中:
git config --global user.name " " #名称git config --global user.email xx@qq.com #邮箱
只需要做一次这个设置,如果你传递了--global 选项,因为Git将总是会使用该信息来处理你在系统中所做的一切操作。如果你希望在一个特定的项目中使用不同的名称或e-mail地址,你可以在该项目中运行该命令而不要--global选项。总之--global为全局配置,不加为某个项目的特定配置。
查看配置
要检查已有的配置信息,可以使用 git config --list 命令

查看系统config git config --system --list查看当前用户(global)配置 git config --global --list
也可以直接查阅某个环境变量的设定,只要把特定的名字跟在后面即可
$ git config user.name
$ git config -e # 针对当前仓库
$ git config -e --global # 针对系统上所有仓库
Git的工作流程原理:
1、克隆文件和新建文件为工作目录;
2、在原有文件上添加或修改文件
3、将需要进行版本管理的文件放入暂存区域;
4、将暂存区域的文件提交到git仓库。
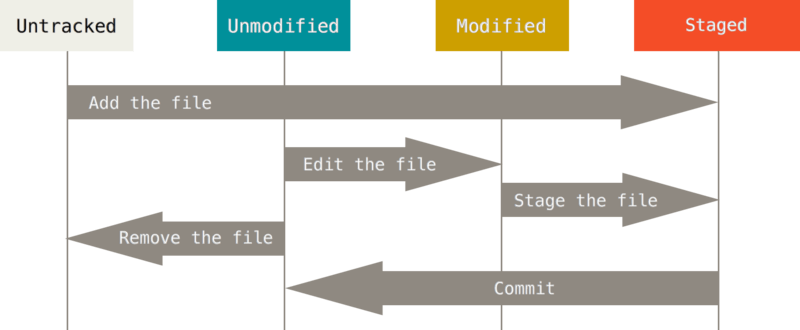
创建工作目录与常用指令
工作区(WorkSpace)一般就是你希望Git帮助你管理的文件夹,可以是你项目的目录,也可以是一个空目录,建议不要有中文。日常使用只要记住下图6个命令:

常用命令如下
Git 创建仓库
git init
该命令执行完后会在当前目录生成一个 .git 目录。.git 默认是隐藏的,可以用 ls -a 命令查看,或者打开你文件查看的隐藏

使用我们指定目录作为Git仓库。git init 目录名
git clone <仓库> <本地目录>
eg:克隆以下项目命令为
git clone https://github.com/13163203690/renlian.git

执行该命令后,会在当前目录下创建一个名为grit的目录,其中包含一个 .git 的目录,用于保存下载下来的所有版本记录。
提交与修改
提交日志
远程操作
测试案例
@LAPTOP-AICI60HO MINGW64 /e/pystudy/Gitcode (master)
$ touch readme #新建文件
@LAPTOP-AICI60HO MINGW64 /e/pystudy/Gitcode (master)
$ git add readme
@LAPTOP-AICI60HO MINGW64 /e/pystudy/Gitcode (master)
$ git commit -m '第一次提交'
[master (root-commit) 1777957] 第一次提交
2 files changed, 0 insertions(+), 0 deletions(-)
create mode 100644 a.txt
create mode 100644 readme
Git 分支管理
# 列出所有本地分支
git branch
# 列出所有远程分支
git branch -r
# 新建一个分支,但依然停留在当前分支
git branch [branch-name]
# 新建一个分支,并切换到该分支
git checkout -b [branch]
# 合并指定分支到当前分支
$ git merge [branch]
# 删除分支
$ git branch -d [branch-name]
# 删除远程分支
$ git push origin --delete [branch-name]
$ git branch -dr [remote/branch]
Git 查看提交历史
git log #查看历史提交记录。
git blame <file> #以列表形式查看指定文件的历史修改记录。
$ git log --oneline #来查看历史记录的简洁的版本。
Git 远程仓库(Github)

添加远程库
要添加一个新的远程仓库,可以指定一个简单的名字,以便将来引用,命令格式如下:
git remote add [shortname] [url]
配置Git验证信息:使用以下命令生成 SSH Key:
$ ssh-keygen -t rsa -C "your_email@youremail.com"
后面的your_email@youremail.com改为你在github上注册的邮箱,之后会要求确认路径和输入密码,我们这使用默认的一路回车就行。成功的话会在生成.ssh文件夹,进去,打开id_rsa.pub,复制里面的key。

回到github上,进入 Account Settings(账户配置),左边选择SSH Keys,Add SSH Key,title随便填,粘贴在你电脑上生成的key。

为了验证是否成功,输入以下命令:
ssh -T git@github.com
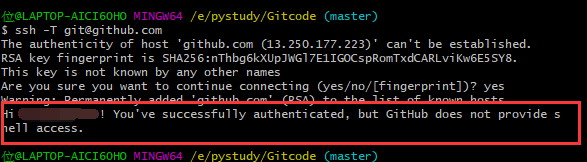 你可以开始创建远程库了
你可以开始创建远程库了

以上信息告诉我们可以从这个仓库克隆出新的仓库,也可以把本地仓库的内容推送到GitHub仓库。
现在,我们根据 GitHub 的提示,在本地的仓库下运行命令:
echo "# scraping-test" >> README.md #创建README.md文件并写入内容
git init #初始化
git add README.md #添加文件
git commit -m "first commit" #提交并备注信息
git branch -M main
#提交到GitHub
git remote add origin https://github.com/13163203690/scraping-test.git
git push -u origin main
不过GitHub感觉是真的不稳定,经常无法访问不知道是不是只有我这样

gitee码云
国外GitHub比较慢就可以使用国内的 Git 托管服务
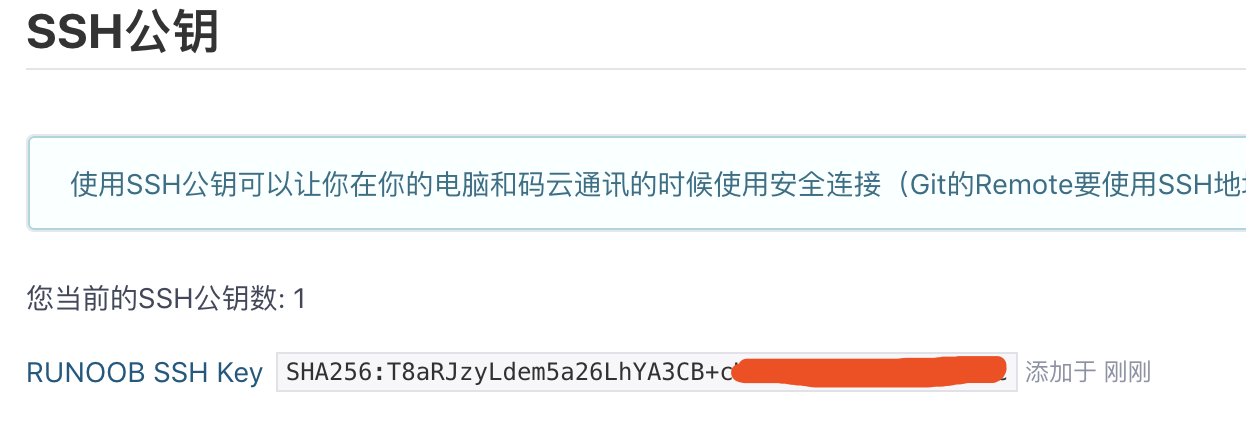
1、我们先在 Gitee 上注册账号并登录后,然后上传自己的 SSH 公钥。
我们在 Git Github 章节已经生成了自己的 SSH 公钥,所以我们只需要将用户主目录下的 ~/.ssh/id_rsa.pub 文件的内容粘贴 Gitee 上。
选择右上角用户头像 -> 设置,然后选择 "SSH公钥",填写一个便于识别的标题,然后把用户主目录下的 .ssh/id_rsa.pub 文件的内容粘贴进去
成功添加后如下图所示:
接下来我们创建一个项目。
点击右上角的 + 号,新建仓库:

然后添加仓库信息:
详见
Git Gitee | 菜鸟教程 (runoob.com)
忽略文件
有些时候我们不想把某些文件纳入版本控制中,比如数据库文件,临时文件,设计文件等
在主目录下建立".gitignore"文件,此文件有如下规则:
-
忽略文件中的空行或以井号(#)开始的行将会被忽略。
-
可以使用Linux通配符。例如:星号(*)代表任意多个字符,问号(?)代表一个字符,方括号([abc])代表可选字符范围,大括号({string1,string2,...})代表可选的字符串等。
-
如果名称的最前面有一个感叹号(!),表示例外规则,将不被忽略。
-
如果名称的最前面是一个路径分隔符(/),表示要忽略的文件在此目录下,而子目录中的文件不忽略。
-
如果名称的最后面是一个路径分隔符(/),表示要忽略的是此目录下该名称的子目录,而非文件(默认文件或目录都忽略)。
#为注释*.txt #忽略所有 .txt结尾的文件,这样的话上传就不会被选中!!lib.txt #但lib.txt除外/temp #仅忽略项目根目录下的TODO文件,不包括其它目录tempbuild/ #忽略build/目录下的所有文件doc/*.txt #会忽略 doc/notes.txt 但不包括 doc/server/arch.txt
如果不懂Linux的同学可以看
参考学习链接:
视频同步笔记:狂神聊Git (qq.com)
狂神的视频讲的不错https://www.bilibili.com/video/BV1FE411P7B3
【莫烦Python】Git 代码版本管理教程_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
Git学习专栏_TechArtisan6的博客-CSDN博客
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)