理解变分自编码器
introduction
在近几年这些深度生成模型中,有两个主要的系列脱颖而出,特别值得关注。它们分别是生成对抗网络(GANs)和变分编码器(VAEs)。
VAE是一个自动编码器,其编码的分布在训练期间被正则化,以确保其潜空间具有良好的属性,使我们能够产生一些新的数据。此外,“variational” 一词来自于统计学中的正则化和变量推理方法(variational inference)之间的密切关系。
如果说最后两句话很好地概括了VAE的概念,那么它们也会引起很多问题。
- 什么是自动编码器autoencoder?
- 什么是潜空间,为什么要对其进行正则化?
- 如何从VAEs生成新的数据?
- VAEs和variational inference之间的联系是什么?
在第一节中,我们将回顾一些关于降维和自动编码器的重要概念,这些概念对于理解VAE是很有用的。然后,在第二节,我们将说明为什么自动编码器不能用来生成新的数据,并将介绍变异自动编码器,它是自动编码器的正则化版本,使生成过程成为可能。最后,在最后一节中,我们将基于变异推理,对VAEs进行更多的数学介绍。
降维方法: PCA and Autoencoders
降维架构
首先,我们把encoder称为从 "旧特征 "表示中产生 "新特征 "表示的过程(通过选择或提取),decoder则是相反的过程。降维可以解释为数据压缩,其中encode压缩数据(从初始空间到编码空间,也称为潜空间),而decoder则解压它们。当然,根据初始数据分布、潜空间维度和编码器的定义,这种压缩可能是有损失的,也就是说,在编码过程中,一部分信息会丢失,在解码时无法恢复。

降维方法的主要目的是在一个给定的系列中找到最佳的编码器/解码器对。换句话说,我们要寻找的是保持最大信息量的一对,因此,在decode时具有最小的重建误差。如果我们分别表示E和D是我们所考虑的编码器和解码器系列,那么降维问题可以写为:
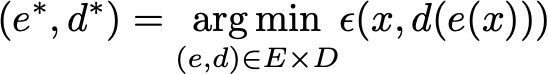
定义了输入数据
x
x
x和编码-解码数据
d
(
e
(
x
)
)
d(e(x))
d(e(x))之间的重建误差度。最后注意,在下文中,我们将表示N为数据的数量,
n
d
n_d
nd为初始空间的维度,
n
e
n_e
ne为缩小(编码)空间的维度。
PCA
原理:
利用线性组合,用少数代表性较强的新指标代替原先多数的原始指标,PCA并没有选择一些特性然后丢弃其余。相反,它创建一些新特性,结果这些新特性能够很好地总结我们想要研究的对象。
如何评价PCA产生的新指标含有的信息量?
正常情况下,n个指标线性组合后会产生n个新的指标,那么我们如何选取这n个新指标?关键的选择标准就是信息量,可以想象,如果新指标所包含的原始x的信息越多,那么用该新指标进行评价,就会越接近真实的情况。
解决方法:研究表明,信息可用新指标的方差来看,方差越大,包含原始信息越多。因为一个线性变化,它的方差越大,数据越离散,代表新指标里的每个原始xi分的越开,数据越具有代表性。
而衡量一个新指标的方差大小可以根据原始指标的协方差矩阵的特征值来判断。


故我们只需求出协方差矩阵的特征值即可,再利用特征值λ也可以反解出系数矩阵Ai。
化为降维框架为:

问题1:什么是自动编码器autoencoder

从直观上看,整个自编码器架构(编码器+解码器)为数据创造了一个漏斗,确保只有信息的主要结构部分可以通过并被重构。从总体框架来看,通过梯度下降在这些网络的参数上寻找使重建误差最小的编码器和解码器。
PCA和Autoencoders之间的关系
我们首先假设我们的编码器和解码器架构都只有一层且没有激活函数(线性自动编码器)。这样的编码器和解码器就是简单的线性变换,可以用矩阵来表示。在这种情况下,我们可以看到Autoencoders与PCA的明显联系,就像PCA一样,我们正在寻找最佳的线性子空间来投射数据,并在投射时尽可能地减少信息损失。用PCA得到的编码和解码矩阵自然地定义了一种可以通过梯度下降达到的解决方案之一。事实上,可以同时用几个基础来描述同一个最佳子空间,因此,几个编码器-解码器对可以给出最佳的重建误差。此外,与PCA相反,对于线性autoencoders来说,最终得到的新特征不一定是独立的(神经网络中没有正交性约束)。
现在,让我们假设编码器和解码器都是深度的、非线性的。在这种情况下,架构越复杂,自编码器就越能进行高维度的降维,同时保持低的重建损失。直观地说,如果我们的编码器和解码器有足够的自由度(数据量),我们可以将任何数据维度降低到1。事实上,一个具有 "无限能力 "的编码器理论上可以将我们的N个初始数据点编码为1、2、3、…直至N(或更普遍地,作为实轴上的N个整数),且解码器可以没有损失的进行反向解码。

然而,我们应该记住两件事。首先,在没有重建损失的情况下进行重要的降维往往是有代价的:潜空间中会缺乏可解释和可利用的结构(缺乏规则性)。第二,大多数时候,降维的最终目的不仅仅是减少数据的维度,而是在减少维度的同时,还要保留数据信息的主要部分。由于这两个原因,潜空间的维度和自编码器的 “深度”(定义压缩的程度和质量)必须根据降维的最终目的进行仔细控制和调整。
Variational Autoencoders
自动编码器在内容生成上的局限性
“自动编码器和内容生成之间有什么联系?”,一旦自动编码器被训练出来,我们就有了一个编码器和一个解码器,但仍然没有真正的方法来产生任何新的内容。乍一看,我们可能会认为,如果潜空间足够规则(在训练过程中被编码器很好地 "组织 "起来),我们可以从潜空间中随机抽取一个点,并对其进行解码以获得一个新的内容。然后,解码器将或多或少地像GANS一样行事。

我们可以通过解码从潜空间中随机抽出的点来生成新的数据。生成的数据的质量和相关性取决于潜空间的规则性。
然而,正如我们在上一节所讨论的,自动编码器的潜空间的正则化是一个难题,它取决于初始空间中的数据分布、潜空间的维度和编码器的结构。因此,要先验地确保编码器将以一种与我们刚才描述的生成过程相适应的方式去组织潜空间对形式是相当困难的。
问题2: 什么是潜空间,为什么要对其进行正则化?
为了说明为什么要对潜空间进行正则化,我们考虑一下前一章给出的例子,其中我们描述了一个强大的编码器和解码器,足以将任何N个初始训练数据放到实轴上(每个数据点被编码为一个实值),并在没有任何重建损失的情况下对它们进行解码。在这种情况下,自动编码器的高自由度(N-1)使得在没有信息损失的情况下进行编码和解码成为可能(尽管潜空间的维度很低),这导致了严重的过拟合,意味着潜空间的其他的点一旦被选中解码就会产生无意义的内容。如果这个一维的例子是模型自动选择的,那么我们可以知道,自动编码器的潜空间规则性问题要比这更普遍,值得特别关注。

不规则的潜空间使我们无法使用自动编码器来生成新内容。
这种缺乏结构的数据进入潜空间是非常正常的。事实上,在自动编码器被训练的任务中,没有任何东西可以强制得到这样的组织:自动编码器只被训练成以尽可能少的损失进行编码和解码,是不会管潜空间是如何组织的。因此,如果我们不注意架构的定义,那么在训练过程中,网络自然会利用任何过拟合的可能性来尽可能地实现其任务…除非我们明确地对其进行正则化处理。
Definition of variational autoencoders
为了能够将我们的自动编码器的解码器用于生成目的,我们必须确保潜伏空间足够规则。
获得这种规则性的一个可能的解决方案是在训练过程中引入明确的规则化。因此,正如我们在这篇文章的介绍中所提到的,变异自动编码器可以被定义为一个训练是有规律的自动编码器,以避免过拟合,并确保潜伏空间具有良好的特性,从而使生成过程得以进行。
就像标准的自动编码器一样,变异自动编码器是一个由编码器和解码器组成的结构,它被训练成最小化解码后数据和初始数据之间的重建误差。为了引入潜空间的一些规则化,我们对编码-解码过程进行了轻微的修改:我们不是将输入编码为一个单一的点,而是将其编码为潜空间的分布。然后,模型被训练如下:
- 输入被编码为潜空间的分布
- 从潜空间中抽出一个点,该点来自于该分布中。
- 对采样点进行解码并计算出重构误差
- 重构误差通过网络进行反向传播。

在实践中,编码分布通常选择为正态分布,这样就可以训练编码器来学习高斯分布的平均值和协方差矩阵。之所以将输入
x
x
x编码为具有一定方差的分布,而不是单点,是因为它可以非常自然地表达潜空间正则化:编码器返回的分布被强制要求接近于标准正态分布。我们将在下一小节中看到,我们通过这种方式确保潜空间的局部和全局正则化(局部是由于方差控制,全局是由平均值控制)。
因此,训练VAE时最小化的损失函数是由一个 “重建项”(在最后一层)和一个 “正则项”(在潜伏层)组成的,前者倾向于使编码-解码方案的性能尽可能好,后者倾向于通过使编码器返回的分布接近于标准正态分布来规范潜空间的组织。该正则化项表示为返回的分布与标准高斯分布之间的KL散度,并将在下一节进一步论证。我们可以注意到,两个高斯分布之间的KL散度有一个简化的形式,可以直接用这两个分布的平均值和协方差矩阵来表示。



Intuitions about the regularisation
为了使生成过程成为可能,人们期望从潜伏空间中获得的规律性可以通过两个主要属性来表达:连续性(潜伏空间中两个相近的点一旦被解码就不应该得到两个完全不同的内容)和完整性(对于一个选定的分布,从潜伏空间采样的一个点一旦被解码就应该得到 "有意义的 "内容)。
若VAE仅仅将输入编码为分布而不是简单的点,并不足以确保连续性和完整性。如果没有一个定义明确的正则化项,模型可以学会 "忽略 "返回分布的事实(返回之前举例的一条直线)为了使其重构误差最小化,其行为就会与经典的自动编码器一样(导致过度拟合),它会返回具有微小方差的分布或直接返回平均值的分布。
因此,为了避免这些影响,我们必须对编码器返回的分布的协方差矩阵和平均值进行正则化。在实践中,这种正则化是通过强制要求分布接近标准正态分布(居中和缩小)来实现的。这样,我们就要求协方差矩阵接近于同一性,以防止分布相同,同时要求平均值接近于0,以防止编码后的分布彼此之间相差太远。

有了这个正则化项,我们就可以防止模型在潜空间中对数据进行远距离编码,并尽可能地鼓励返回的分布 “重叠”,从而满足预期的连续性和完整性条件。当然,对于任何正则化项来说,这都是以训练数据上较高的重构误差为代价的。然而,重重构误差和KL散度之间的权衡是可以调整的,我们将在下一节看到平衡的表达是如何从我们的正式推导中自然产生的。
在结束本小节时,我们可以看到,通过正则化获得的连续性和完整性倾向于在潜空间编码的信息上创造一个 “梯度”。例如,潜空间的一个点位于两个来自不同训练样本的编码分布的平均值之间,它应该被解码为介于给出第一个分布的数据和给出第二个分布的数据之间的东西,因为它可能在两种情况下都被自动编码器采样了。