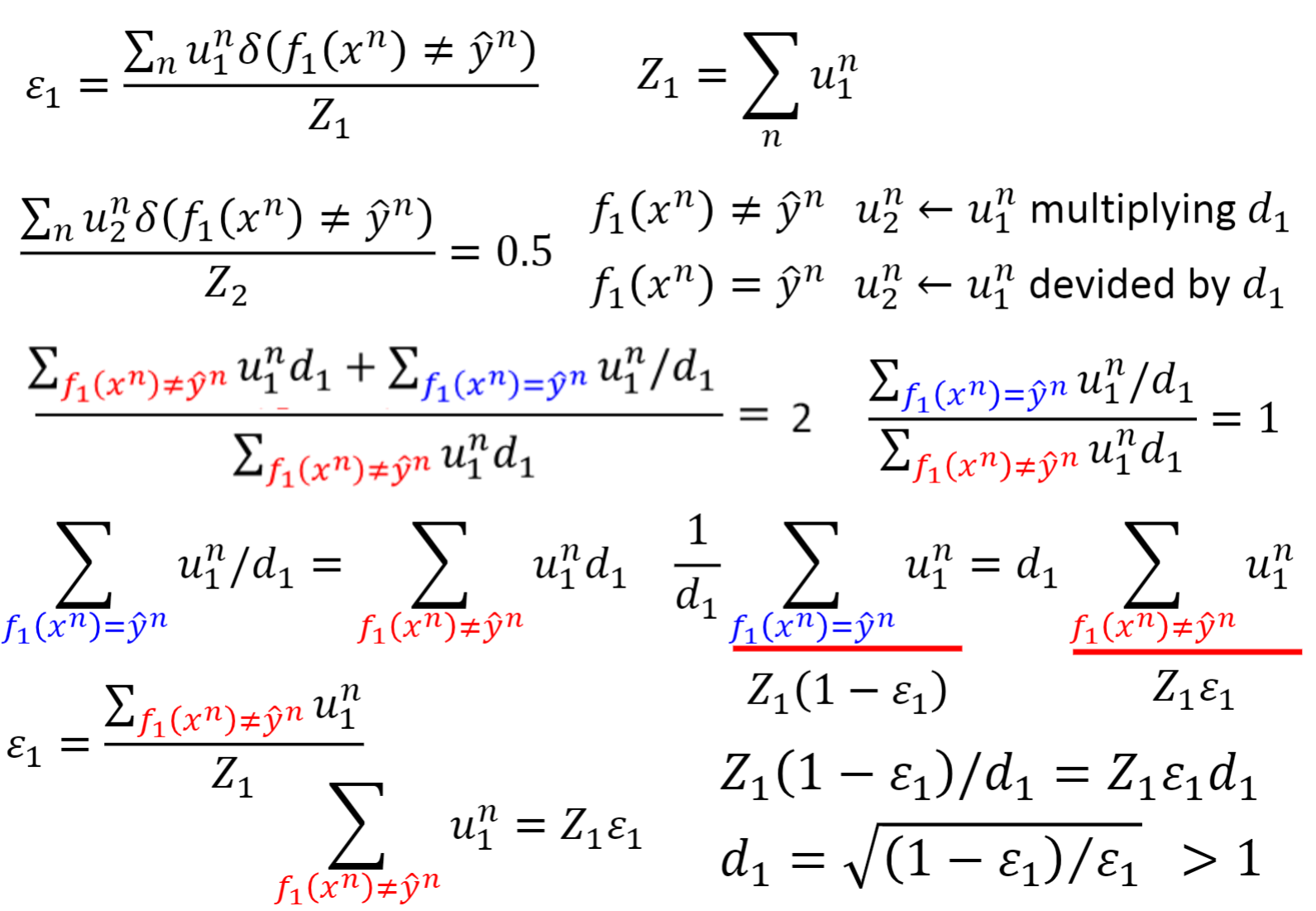Python
Java
PHP
IOS
Android
Nodejs
JavaScript
Html5
Windows
Ubuntu
Linux
5.1-集成学习
2023-11-15
文章目录
集成框架(Framework of Ensemble)
一、 Ensemble: Bagging
1.1 决策树(Decision Tree)
1.2 随机森林(Random Forest)
二、Ensemble: Boosting
2.1 寻找不同的分类器
2.2 Adaboost
2.3 数学推导
2.4 边界(Margin)
2.5 Gradient Boosting
三、Ensemble: Stacking
集成框架(Framework of Ensemble)
一、 Ensemble: Bagging
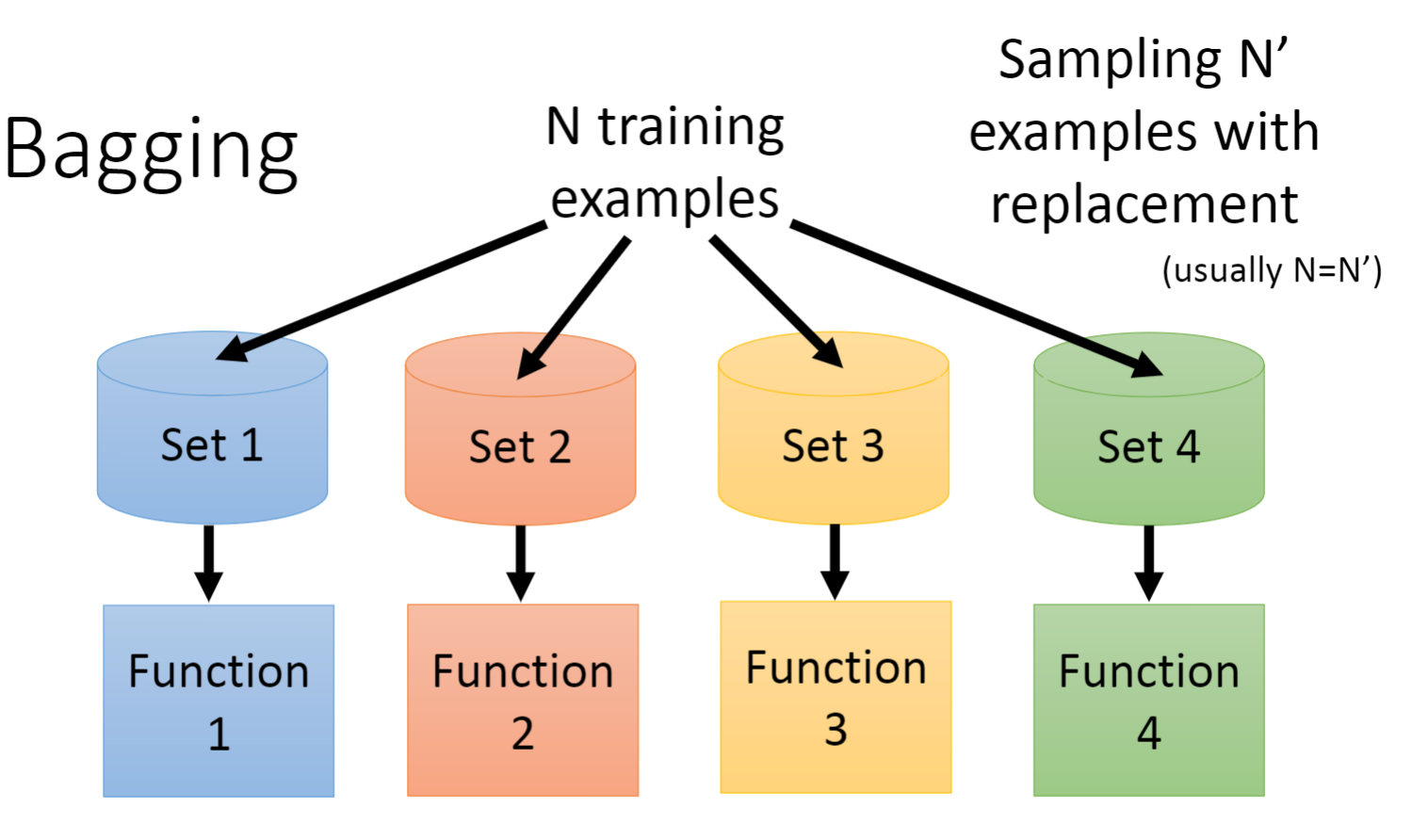
Bagging做的事情就是创造出不同的数据集,再用不同的数据集各自训练一个复杂的模型,虽然每一个模型单独拿出来看方差(Variance)都很大,但把所有的模型集合起来求平均之后,就会得到一个方差很小,偏置值也很小的理想模型。
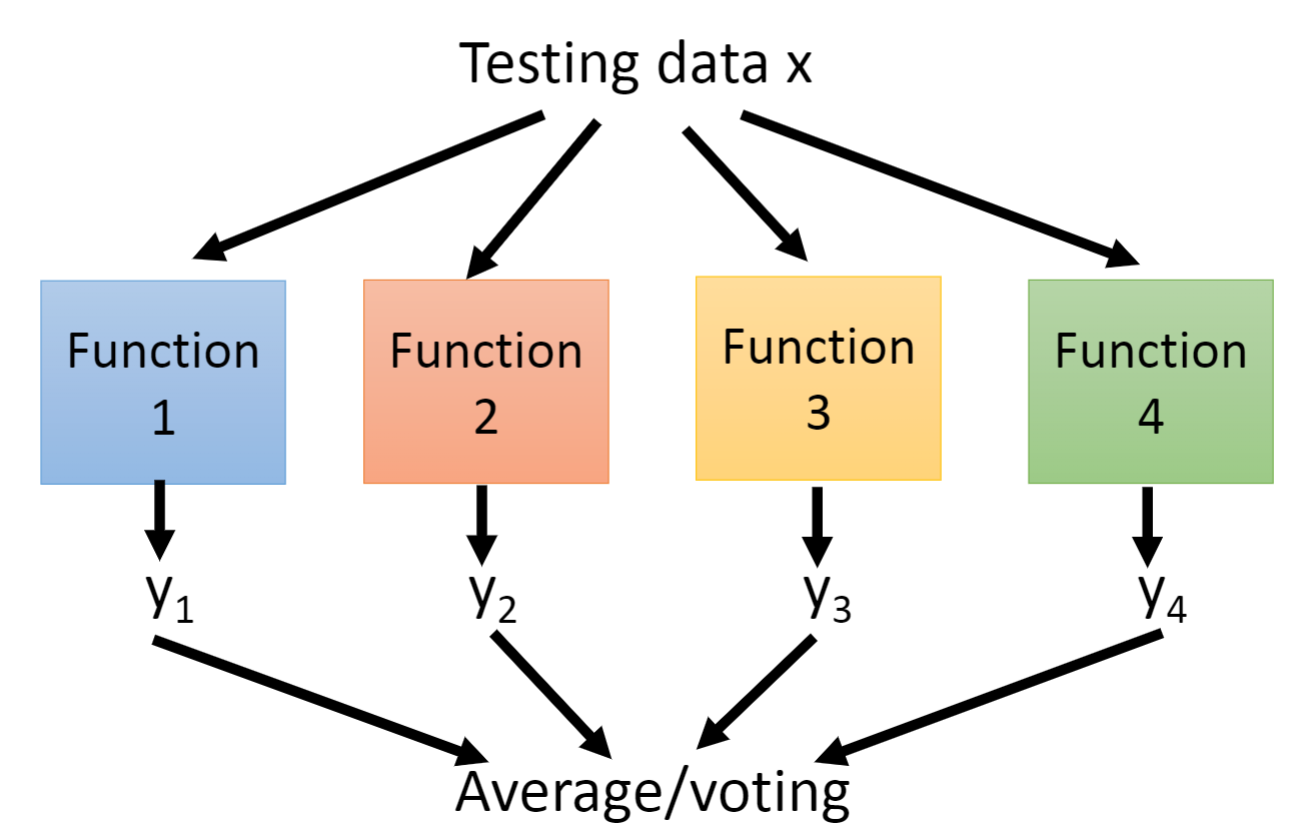
第一件事就是创造出不同的数据集,首先我们对原数据集进行随机抽样得到多个不一样的数据集。如果是回归问题,我们就采用平均(Average)的方法,如果是分类的问题,我们就采取投票(Average)的方法。
那什么时候做Bagging呢?只有在你的模型很复杂,担心他过拟合时才做Bagging,因为做Bagging的目的就是为了降低Variance。
1.1 决策树(Decision Tree)
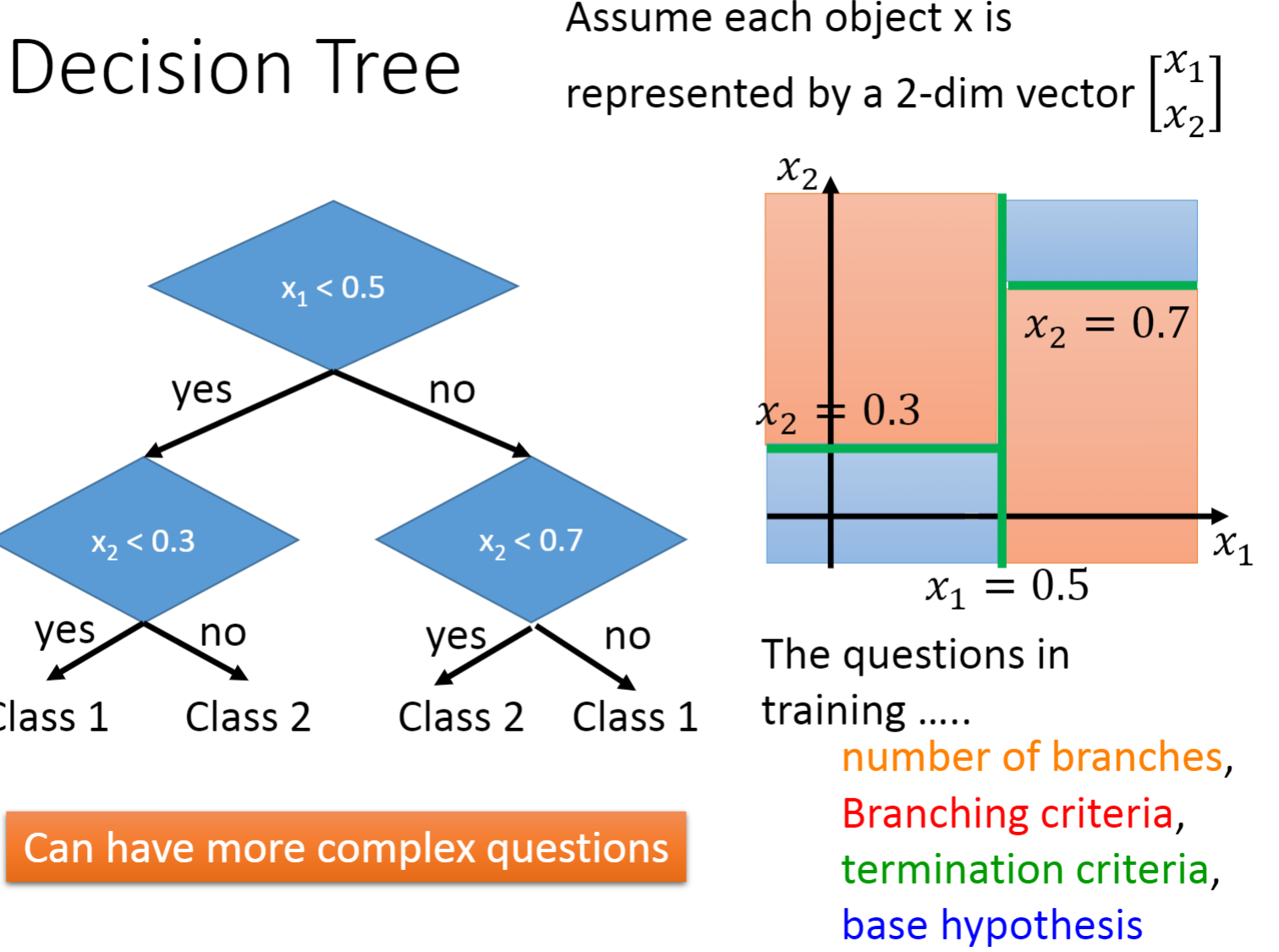
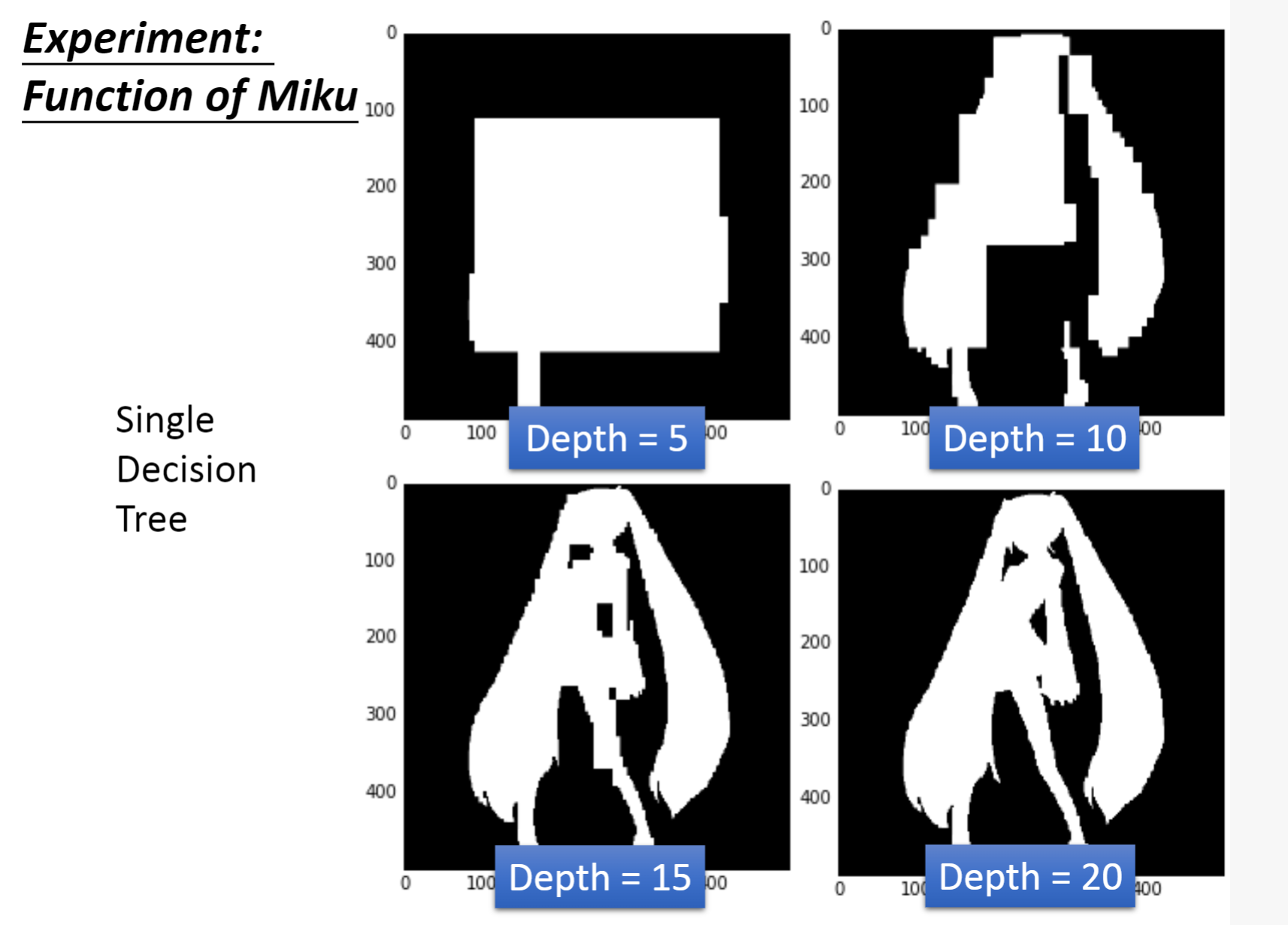
决策树就是一个非常需要做Bagging的方法,因为它十分容易过拟合。随机森林就是决策树做Bagging后的版本。
做决策树需要注意的地方:
需要多少分支
要用什么样的标准来做分支
什么时候停止分支…
右图是决策树的一个示例,只要深度够深,我们就可以将错误率降到0
1.2 随机森林(Random Forest)
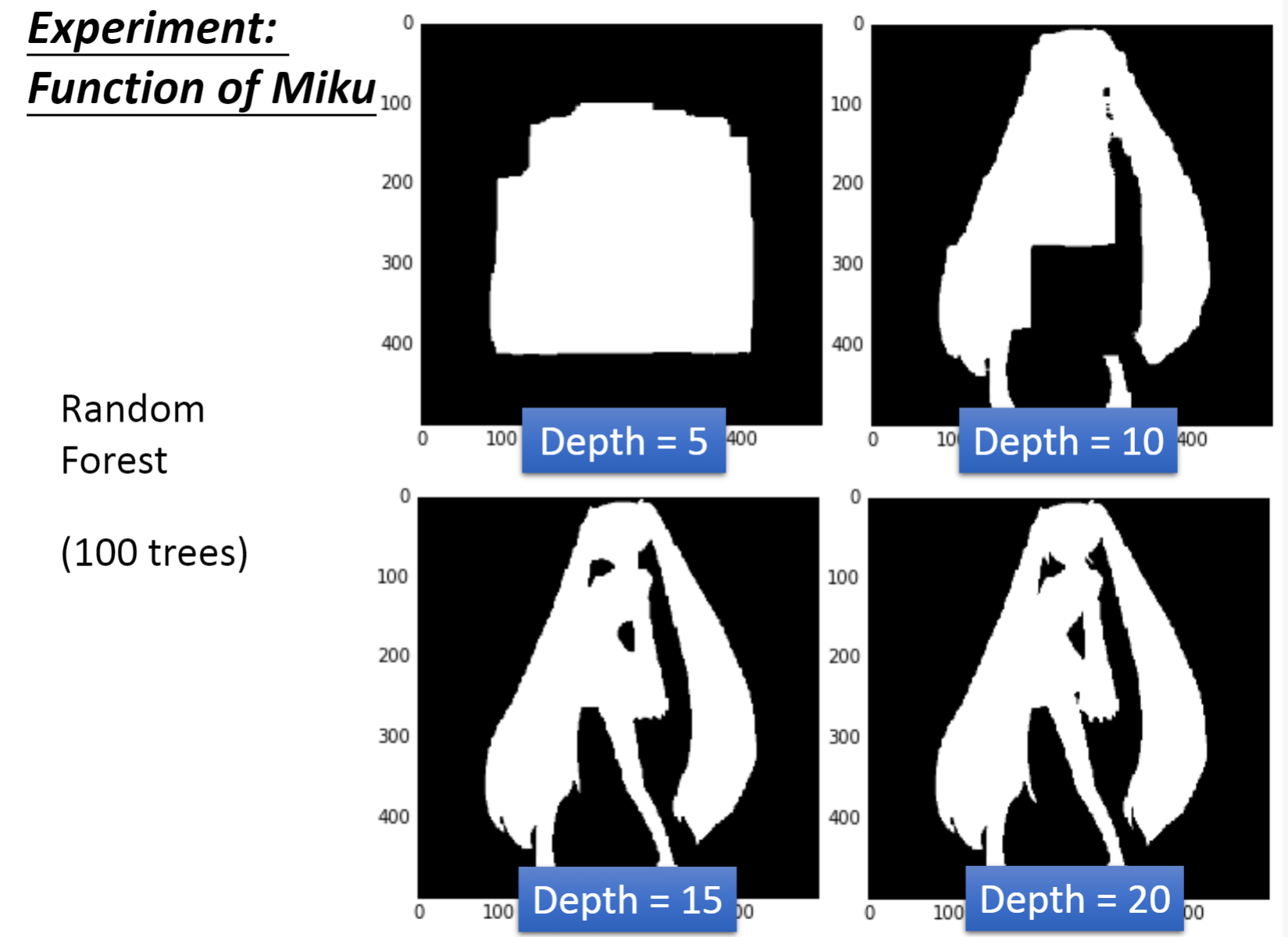
做随机森林时光采取随机采样是不够的,还要在每次产生决策树的分支时都随机决定哪些特征是不能用的。这样才能保证即使用的是同一个数据集里产生出来的决策树也是不一样的,最后将所有的决策树集合起来就得到随机森林。
out-of-bag:如果使用bagging的方法,那么我们可以不用将数据集切分成训练集和验证集,但是一样有验证的效果。如左图表格,f
2
和f
4
并没有看到过x
1
这笔数据,那么我们就可以拿x
1
这笔数据来验证我们的模型f
2
和f
4
,最终计算4个模型的平均误差。
二、Ensemble: Boosting
Bagging是应用在一些很强的模型上来解决过拟合的问题,而Boosting是应用在一些很弱的模型上来解决欠拟合的问题。
2.1 寻找不同的分类器
boosting的原理是首先找到第一个分类器f
1
(x),然后找到一个与f
1
(x)互补的分类器f
2
(x),也就是f
2
(x)与f
1
(x)的相似度要尽可能的低,接下来找到一个与f
2
(x)互补的分类器f
3
(x),就这样一直找下去,我们会得到一个分类器的集合,将他们线性组合起来就得到了我们最终的分类器。
找分类器这件事是有顺序的,必须找到前一个才能开始找下一个,不能并行执行。
右图介绍了如何通过给每一笔数据集一个权重u
n
来训练生成不同的分类器,其评估函数loss相比普通的loss也只是多乘上了一个权重u
n
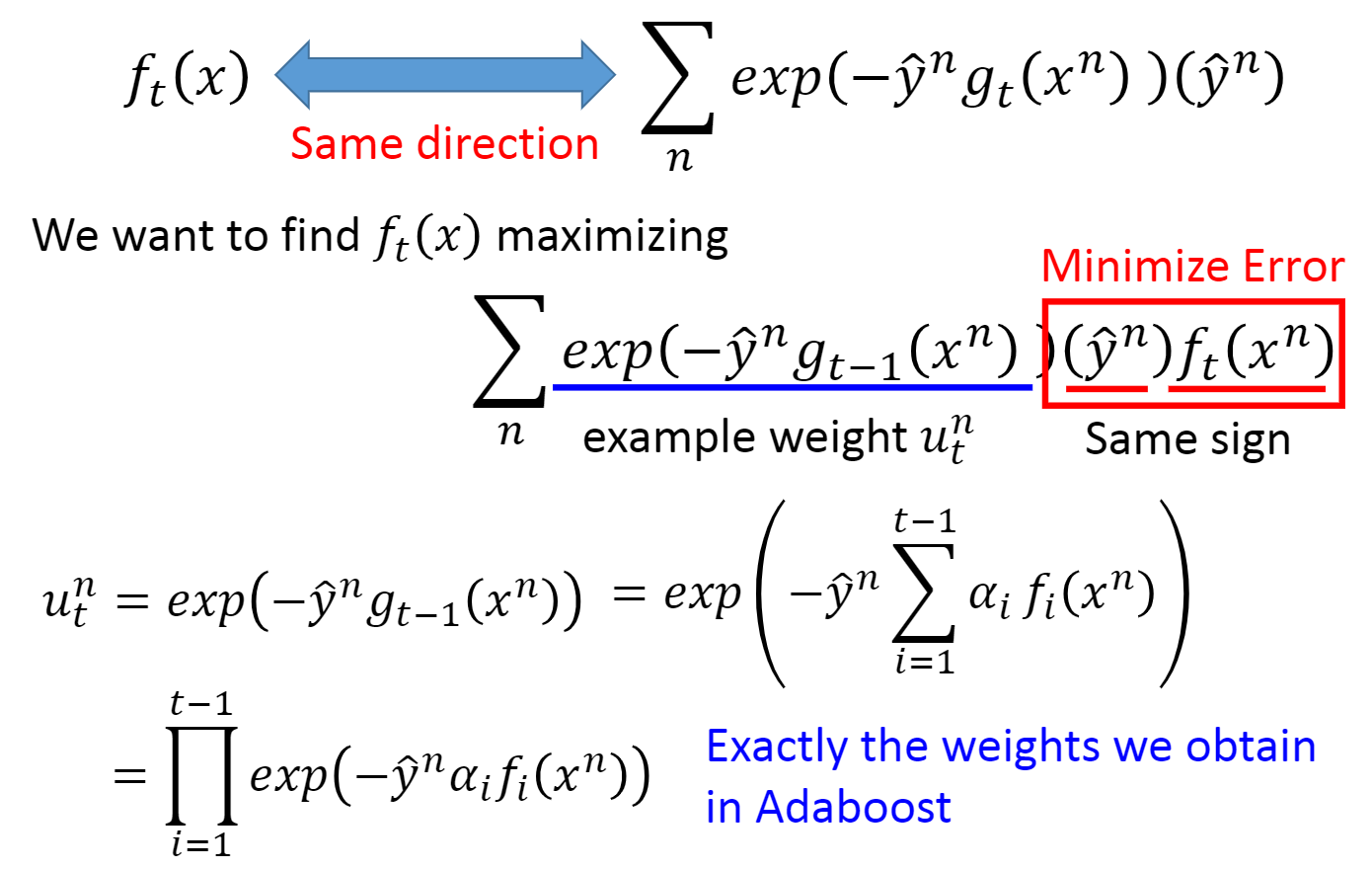
2.2 Adaboost
如左图,首先调整训练集的权重u
n
,找到一组训练集让f
1
(x)的正确率只有50%,再用这笔训练集去训练生成f
2
(x)。
具体原理如右图,就是让模型f
1
(x)在权重一样的训练集上进行训练,训练结束后降低回答正确的训练集权重u
1
,u
3
,u
4
,提高回答错误的训练集权重u
2
,这样就可以找到一组训练集让f
1
(x)的正确率只有50%
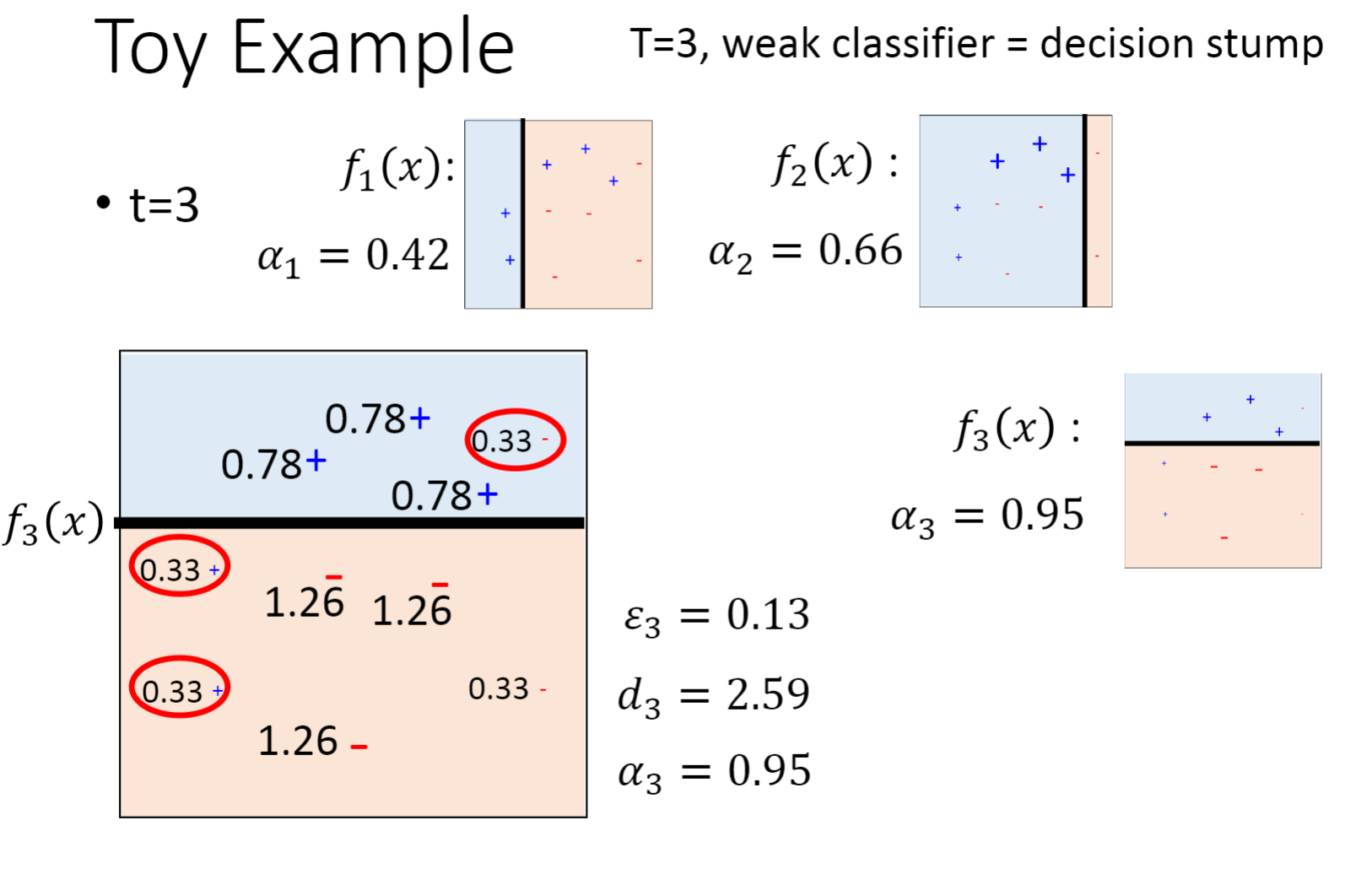
下面是Adaboost的算法推导过程
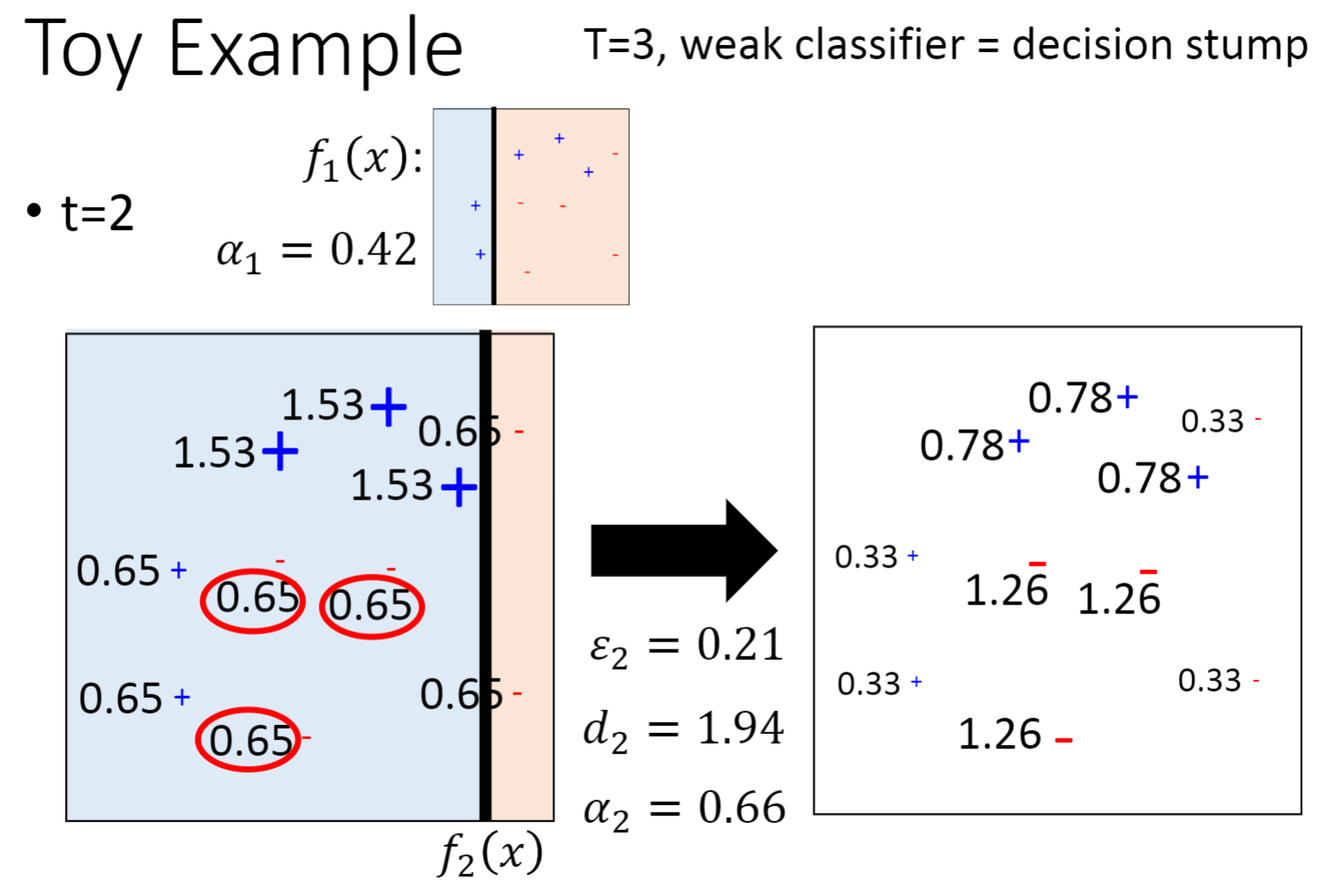
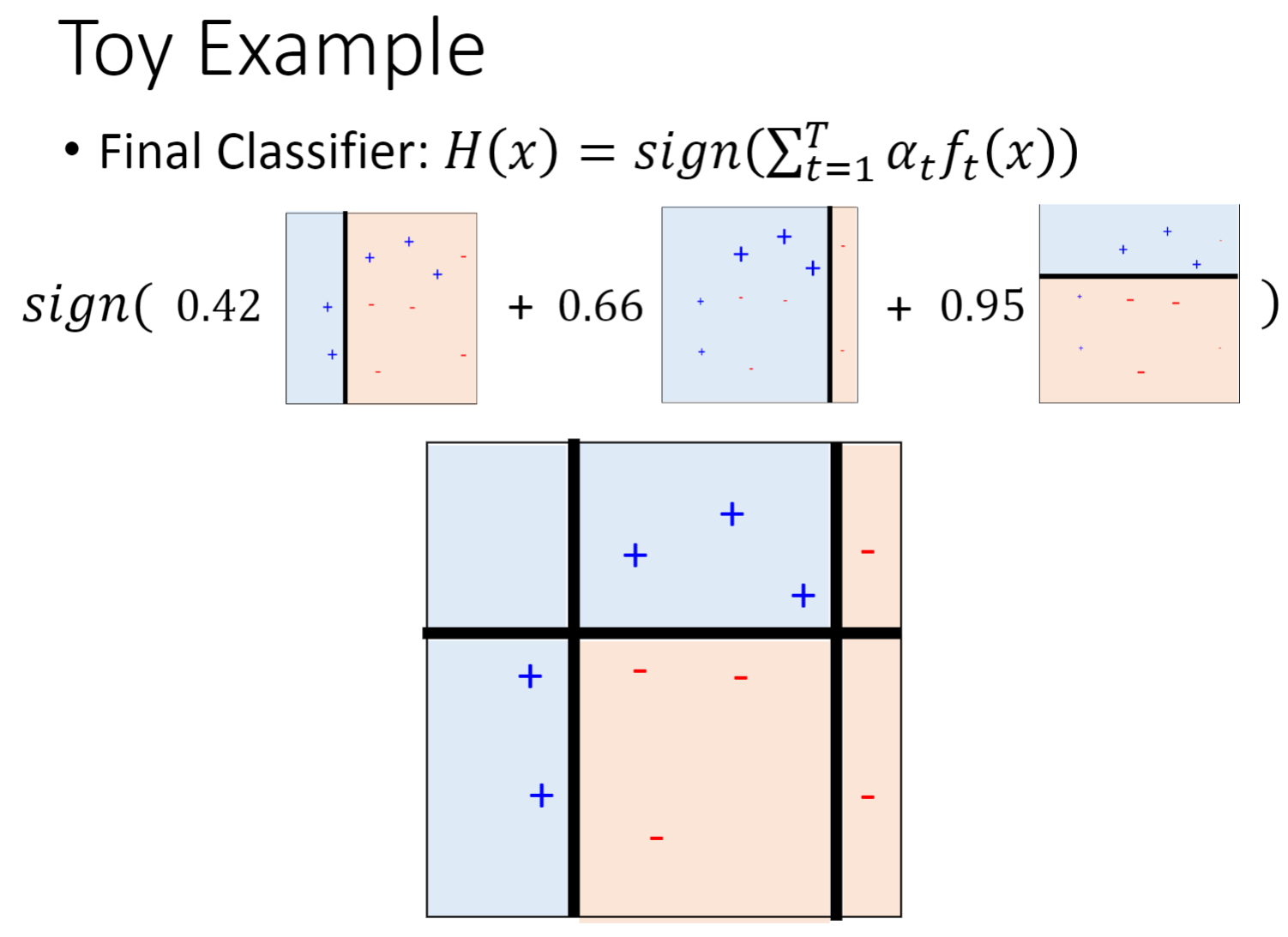
下面是通过Adaboost找到三个较弱的分类器,最终组成一个强大的分类器的过程。
2.3 数学推导
α t \alpha_t
α
t
代表每个分类器的权重,一共有
f 1 . . . f t f_1...f_t
f
1
...
f
t
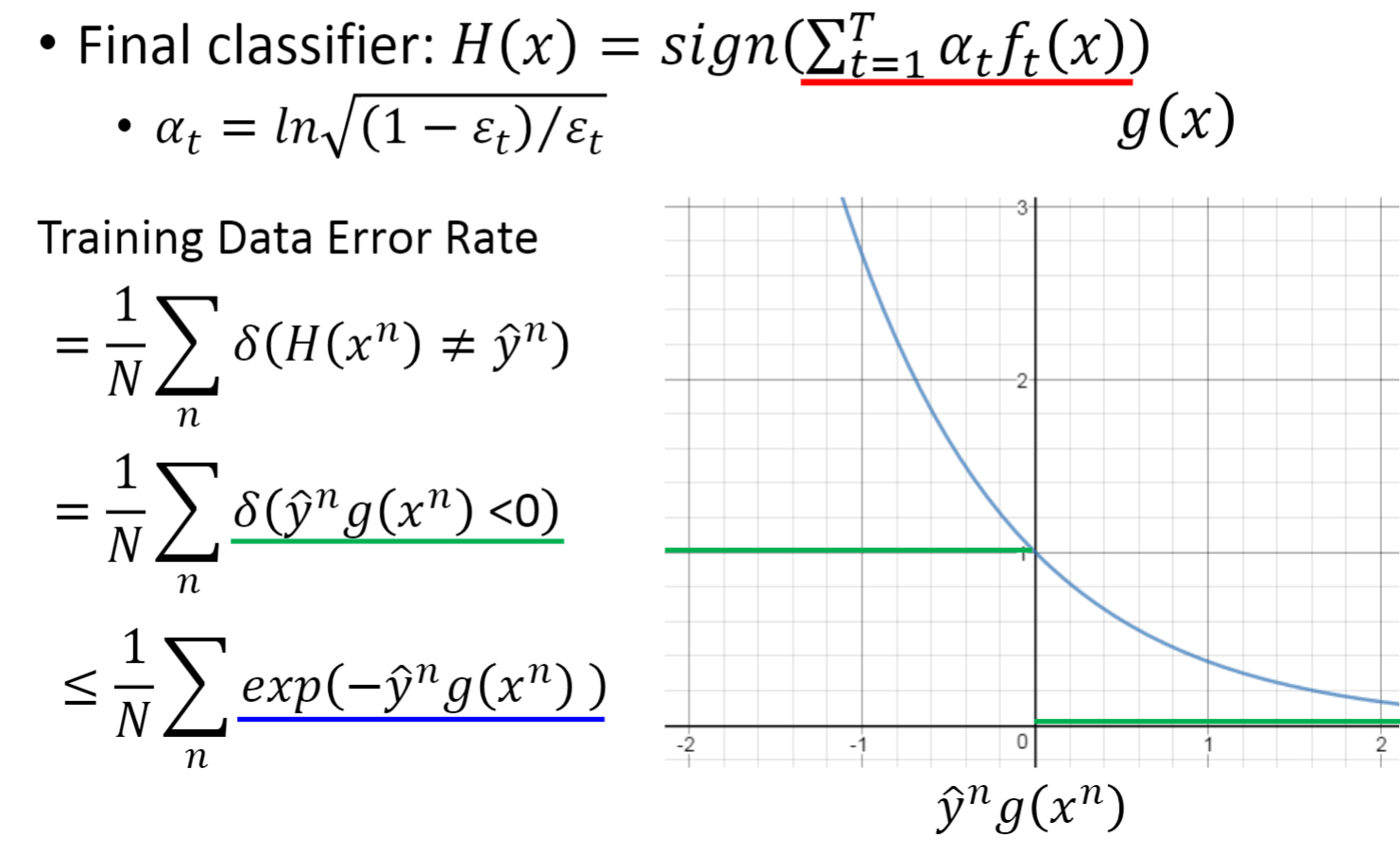
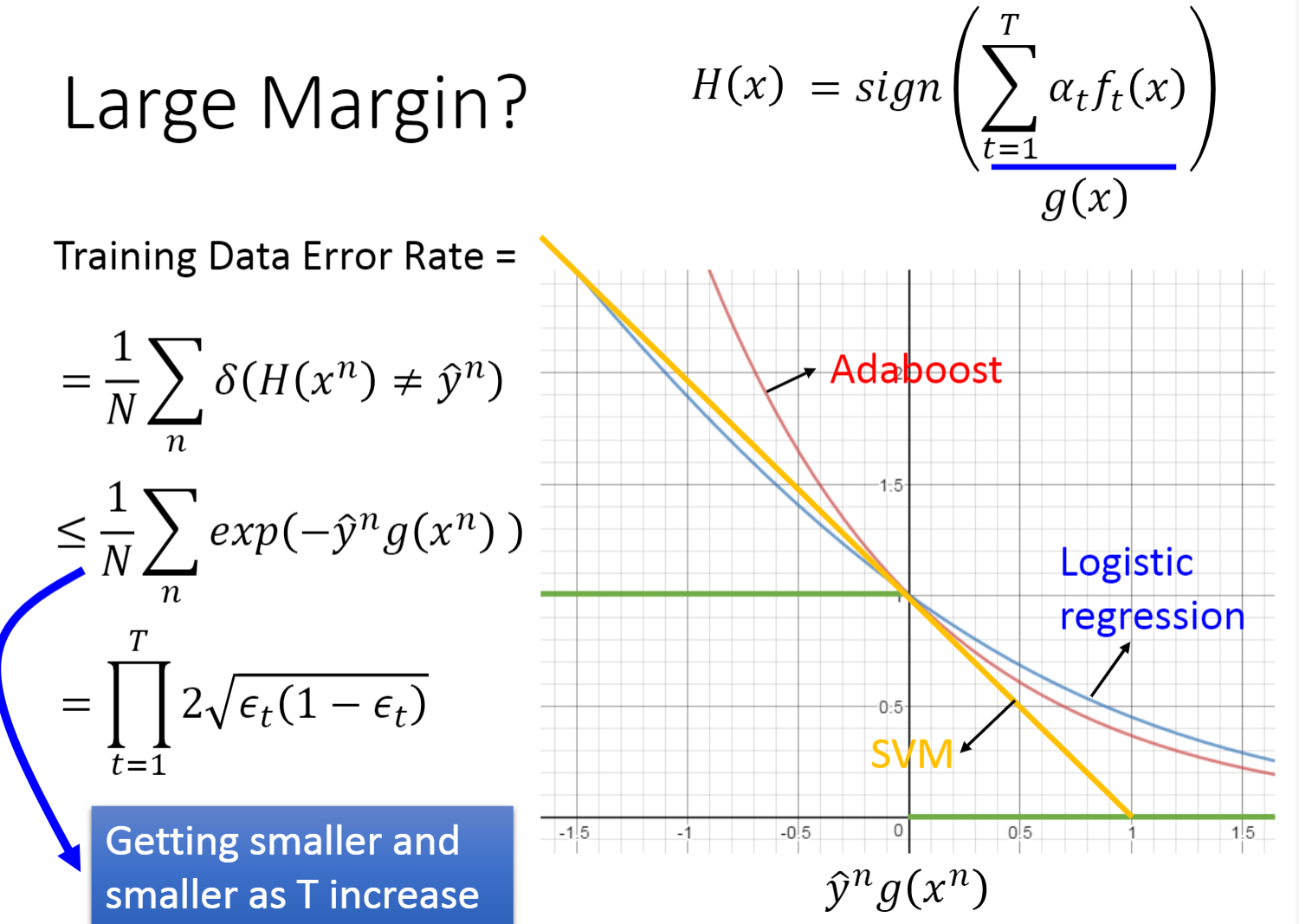
共计 t 个分类器,随着 T 数量的增加,我们的误差会变得越来越小。
2.4 边界(Margin)
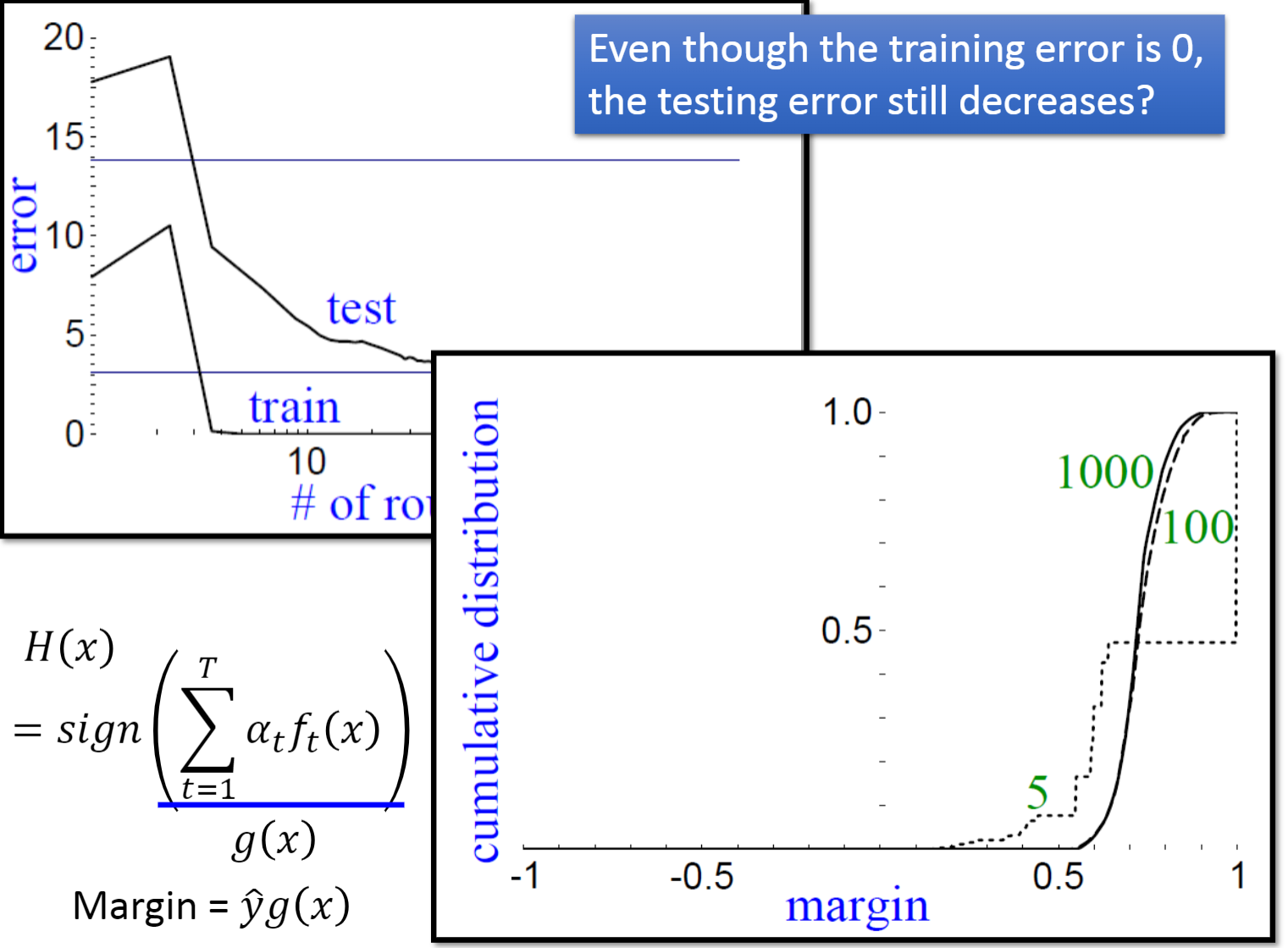
根据左图可以很清晰的看到Margin的表达式,以及分类器的数量越多,Margin越大,在测试集上的表现越好。
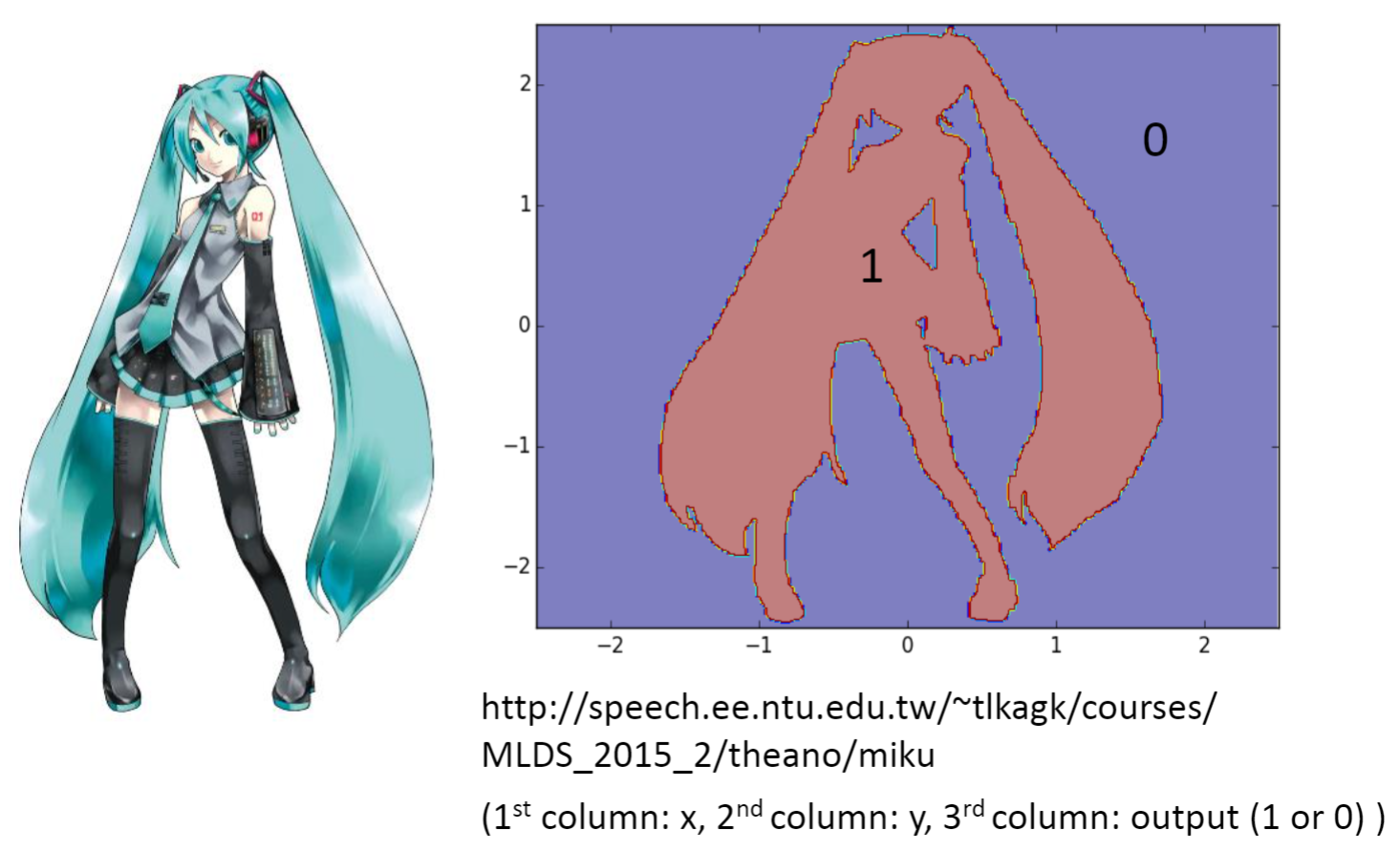
下图是Adaboost+决策树的表现,树的深度为5,当树的数量达到100时,就可以很好的绘制出初音的轮廓了。这是之前使用Bagging,随机森林都无法做到的事情。
2.5 Gradient Boosting
下面是Boosting的一般表达式 g
t
(x) 的求解过程,根据最后一张图的结论可以看出Adaboost整件事情也是在做梯度下降,只是求梯度的不是一个参数,而是一个函数 g(x) 。并且 Adaboost的目标函数可以任意更改。
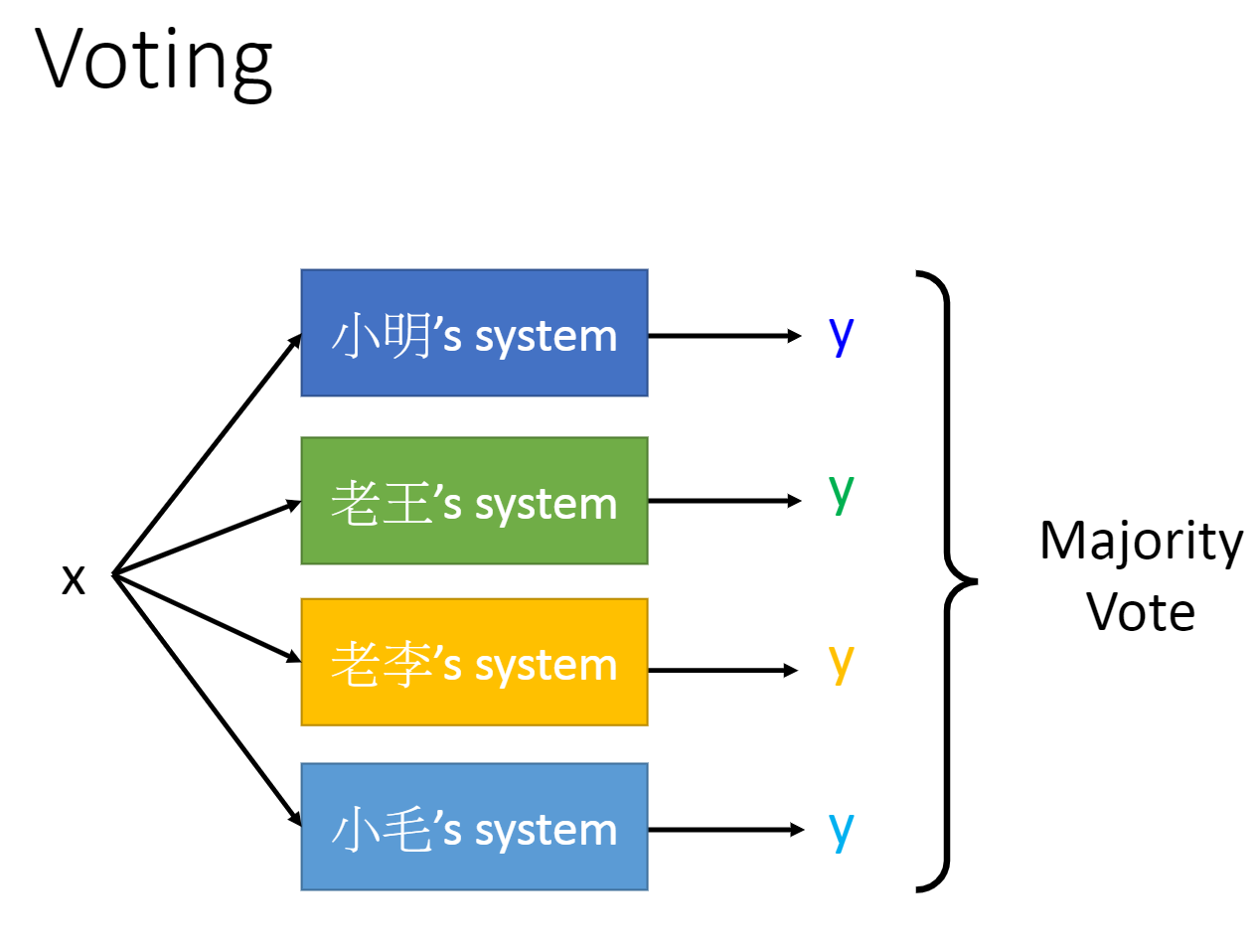
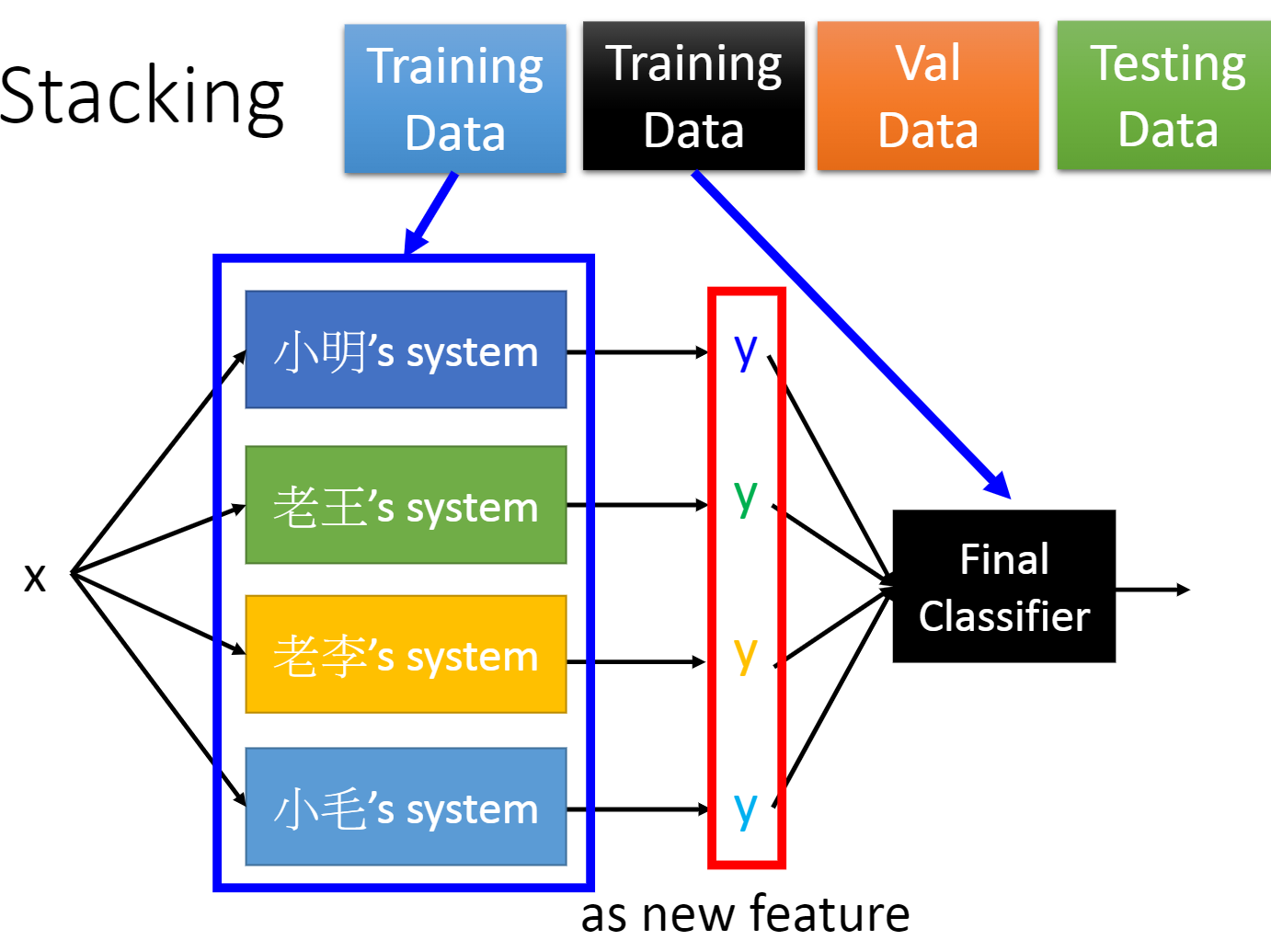
三、Ensemble: Stacking
将大家做的模型都组合起来,这就需要一个最终的分类器为大家的模型赋予不同的权重,为了防止小明等人的模型是过拟合而获得较高的权重,就需要准备两笔训练集。一笔用来训练小明等人的模型,一笔用来训练最终的分类器。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)
CH4李宏毅机器学习
集成学习
机器学习
决策树
5.1-集成学习 的相关文章
neo4j下载安装配置步骤
目录 一 介绍 简介 Neo4j和JDK版本对应 二 下载 官网下载 直接获取 三 解压缩安装 四 配置环境变量 五 启动测试 一 介绍 简介 Neo4j是一款高性能的图数据库 专门用于存储和处理图形数据 它采用节点 关系和属性的图形结构
linux安装服务器步骤,Linux服务器的安装配置流程
不积跬步无以至千里 贴士 因为是装在Ubuntu系统上 其中有几个常用的命令告诉大家 下面在操作中你也会见到如下等命令 sudo gedit 文件目录对某个文件进行编辑和vi命令差不多 因为好多系统文件是只读的 可通过此方式来进行编辑修改
随机推荐
k8s六
参考资料 从Docker到Kubernetes进阶 阳明 这里写目录标题 一 StatefulSet的设计原理 二 有状态服务的拓扑状态 三 有状态服务的存储状态 四 使用StatefulSet控制器部署ES集群 1 创建无头服务 2 部署
华为云云耀云服务器L实例评测|在Docker环境下部署Mysql数据库
华为云云耀云服务器L实例评测 在Docker环境下部署Mysql数据库 一 前言 1 1 云耀云服务器L实例简介 1 2 Mysql数据库简介 二 本次实践介绍 2 1 本次实践简介 2 2 本次环境规划 三 购买云耀云服务器L实例 3 1
vagrant加virtualbox轻松搭建k8s集群脚本
文章目录 环境准备 配置k8s节点 环境准备 windows 电脑上使用vagrant 加 virtualbox 搭建k8s 集群 不熟悉vagrant 与 virtualbox 的可以查看这篇文章 使用VirtualBox和Vagrant
由ValueError: not enough values to unpack (expected 2, got 1)报错说开去
一 背景 今日做了一个文本分类任务 在更换对应的语料库的时候 处理完的语料报了个如题的错误 究其原因 这里用到了一个split t 作为content和label的分割 也就是在语料库中使用 t作为语料库中句子和标签的分隔符 但是在我写下
基于Pytorch框架的ResNet:MNIST数据集手写数字识别
Debug经验总结 一 常规ResBlock的输出尺寸与输入尺寸相同 否则需要进行尺寸变换 二 在数据集较大时设置num work进行多线程处理 可以很大提高训练效率 三 较复杂的网络在搭建前可以先用草图计算每个输出位置的矩阵尺寸 减少De
C++ opencv 识别火焰 (代码)
brief 火焰识别
Java中anyMatch()、allMatch()、noneMatch()用法详解
说明 anyMatch 匹配到任何一个元素和指定的元素相等 返回 true allMatch 匹配到全部元素和指定的元素相等 返回 true noneMatch 与 allMatch 效果相反 验证 一 anyMatch 1 正常匹配 多元
解决mac下每次git pull/push都需要输入密码的问题
首先本身项目是走ssh克隆下来的 之前也配置过密钥 按理来说不应该出现这样的问题 在日常开发过程中突然需要我输入密码 小朋友你是否有很多问号 在经过多方面资料查找与解决方案尝试后终于找到了原因 背后的黑手是系统升级了 在升级为macOS c
Mysql-提示java.sql.SQLException: Cannot convert value '0000-00-00 00:00:00' from column 7 to TIMESTAMP...
在Mysql数据库中使用DATETIME类型来存储时间 使用JDBC中读取这个字段的时候 应该使用 ResultSet getTimestamp 这样会得到一个java sql Timestamp类型的数据 在这里既不能使用 ResultS
Shader学习笔记:BRDF简单概述
这篇文章写于一年多以前的一次课程作业 这次作为一个 存货 给放出来 仅仅只是针对代码和一些要点进行简单叙述 如果想听完整的版本 请搜索毛星云大神的博客或者书籍 关于基本的物理渲染公式 网络上的博客和典籍已经多如牛毛了 这里只是自己在之前整理
统计学习之方差分析
零 案例说明 为了检验某小学六年级教学质量的差异 从该小学六年级的三个班级中分别选取一定数量的学生 分成三个组 三个样本 对他们期末考试的平均分进行统计分析 如果实验显示每个每组的均值相同 即三个班期末考试的成绩差异不大 则表明该小学六年级
chatgpt赋能python:Python题目搜索软件:提升你的编程水平
Python题目搜索软件 提升你的编程水平 对于那些喜欢编程的人来说 学习Python是一个非常不错的选择 但是 学习Python的难度并不小 需要大量的时间和精力 一个好的学习方式是通过完成Python编程题目来加深对该编程语言的理解 但
firebug 调试ajax,Jquery使用Firefox FireBug插件调试Ajax步骤讲解
首先 我们用一个示例来说明JQuery的Ajax调用过程 实现的一个功能是 点击确认支付按钮之后 实现余额支付的功能 1 首先在php页面将相关需要调用的函数绑定到按钮上 function pay btn bind click ABC ba
qq引流有哪些模式? QQ引流的几种方法
现在做QQ营销的方法真的是太多了 花样百出 什么招式都有的 QQ作为我们常用的交流工具 用于营销也是无可厚非的事情 现在做互联网的 永远离不开两个话题 就是 流量 和 变现 缺少其中一个 你所做的所有事情就完全没有任何意义 1 QQ空间引流
Mysql 多表关联查询
文章目录 1 Mysql中表之间的关系 1 1 多表关系 1 2 外键约束 2 多表联合查询 2 1 交叉连接查询 笛卡尔积 2 2 内连接查询 inner join 2 3 外连接查询 2 3 1 左连接 2 3 2 右连接 2 3 4
【接口测试 】Day3-Postman高级用法1(附项目实战)
目录 课程大纲 昨日回顾 今日目标 Postman高级用法1 一 用例管理 二 Postman断言 三 环境变量与全局变量 四 请求前置脚本 了解 五 Postman关联 重点 课程大纲 接口测试 Day1 接口测试基础 附项目实战 小慌慌
父页面调用easyui datagrid
opener tt datagrid insertRow index 0 row name name
关于kerberos使用keytab安全认证连接hive票据过期的问题及解决方法。
关于kerberos使用keytab安全认证连接hive票据过期的问题及解决方法 问题描述 解决方法 问题描述 本人在使用HiveStreaming的过程中 使用kerberos keytab进行安全验证 程序会保持长期连接 hive jd
动手强化学习(六):DQN 算法
动手强化学习 六 DQN 算法 1 简介 2 CartPole 环境 3 DQN 3 1 经验回放 3 2 目标网络 4 DQN 代码实践 5 以图像为输入的 DQN 算法 6 小结 文章转于 伯禹学习平台 动手学强化学习 强推 本文所有代
5.1-集成学习
文章目录 集成框架 Framework of Ensemble 一 Ensemble Bagging 1 1 决策树 Decision Tree 1 2 随机森林 Random Forest 二 Ensemble Boosting 2 1
热门标签
Cunity开发
临时文件
Java题目保存
回文素数
NOI刷题
爬虫基础篇
bpmnjs
摘要
NoSQL精粹
阿里面试
数理统计R语言
碎碎叨叨
maven项目
计算机是仿生学
build出错
GirHub
Devops开发
upup
图像匹配图像分析
sharedlock
C mutex
大学胡乱写的水文
token会被截取吗
闲杂
桌面灯条
viewpost
获取高度