从图中可以看到,径向基神经网络的激活函数是以输入向量和权值向量之间的距离作为自变量的。即输入隐藏层的数据为输入变量
X
⃗
=
[
x
1
,
x
2
,
…
,
x
m
]
\vec X=[x_1,x_2,\dots,x_m]
X=[x1,x2,…,xm]与权值向量
W
⃗
=
[
w
1
,
w
2
,
…
,
w
m
]
\vec W=[w_1,w_2,\dots,w_m]
W=[w1,w2,…,wm]的距离,一般取
∣
∣
d
i
s
t
∣
∣
=
∑
i
=
1
m
(
x
i
−
w
i
)
2
||dist||=\sqrt{\sum_{i=1}^m{(x_i-wi)^2}}
∣∣dist∣∣=∑i=1m(xi−wi)2。图中的b为阈值,当
∣
∣
d
i
s
t
∣
∣
||dist||
∣∣dist∣∣的值小于b时,将不会激活神经网络,用于调节神经网络的灵敏度;而权值向量
W
⃗
\vec W
W就是我们找到的数据中心。
隐藏层的激活函数一般取高斯函数:
f
(
x
)
=
e
−
1
2
σ
2
x
2
f(x)=e^{- \frac 1{2\sigma^2}x^2}
f(x)=e−2σ21x2,其中
σ
\sigma
σ为 高斯函数的方差,是一个常数。隐藏层每个节点的输出就是输入的
∣
∣
d
i
s
t
∣
∣
||dist||
∣∣dist∣∣通过激活函数变换后的函数值。
至于输出y,由于这个模型只有一输出,隐藏层也只有一个结点,因此
y
=
e
−
1
2
σ
2
∣
∣
d
i
s
t
∣
∣
2
y=e^{- \frac 1{2\sigma^2}||dist||^2}
y=e−2σ21∣∣dist∣∣2
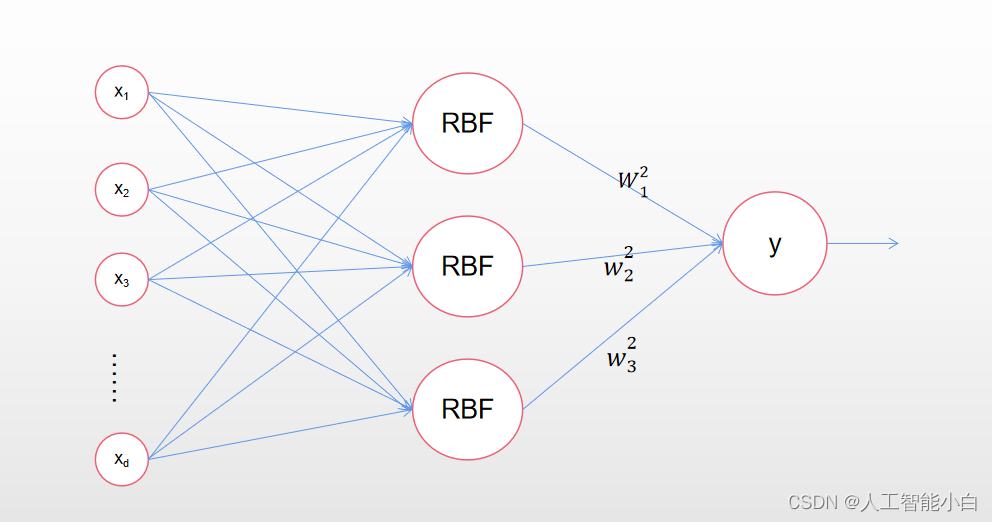
对于更为复杂一点的径向基神经网络,其隐藏层具有多个结点,其结构如下所示: 此时隐藏层有多个向输出层的输出,而输出层的输出则是隐藏层输出的线性加权平均,为了区别输入层的权值向量,我们用
w
i
2
w^2_i
wi2表示第i个隐藏层结点的权值,于是输出层的输出为
y
=
o
u
t
p
u
t
(
∑
i
=
1
n
w
i
2
R
B
F
(
X
⃗
,
W
⃗
i
)
)
y=output(\sum_{i=1}^nw^2_iRBF(\vec X,\vec W_i))
y=output(∑i=1nwi2RBF(X,Wi)),
W
⃗
i
\vec W_i
Wi为第i个隐藏层结点的中心点向量,output()函数则需要根据不同的场景使用不同的函数,例如二分分类我们则可以使用sign()函数。 更为一般的神经网络结构则是隐藏层输出层都含有多个结点的结构,原理与上面的简单结构相差不大,这里就不在介绍。
RBF神经网络算法步骤
RBF神经网络学习算法需要求解的参数有三个:基函数的中心向量
W
⃗
\vec W
W、方差
σ
\sigma
σ以及隐含层到输出层的权值。根据选取的径向基函数中心的方法不同,RBF神经网络有不同的学习方式。下面将介绍自组织选取中心的RBF神经网络学习法。该方法由两个阶段组成:一是自组织学习阶段,此阶段为无导师学习过程,求解隐藏层基函数的中心向量与方差;二是有导师学习阶段,此阶段求解隐藏层到输出层之间的权值。
我们以高斯函数作为径向基神经网络的激活函数,则激活函数可以表示为:
R
(
X
⃗
p
−
W
⃗
i
)
=
e
−
∣
∣
X
⃗
p
−
W
⃗
i
∣
∣
2
2
σ
2
R(\vec X^p-\vec W^i)=e^{-\frac {||\vec X^p-\vec W^i||^2}{2\sigma^2}}
R(Xp−Wi)=e−2σ2∣∣Xp−Wi∣∣2
w
i
为高斯函数中心
∣
∣
x
i
−
w
i
∣
∣
为欧式范数
σ
为高斯函数方差
X
⃗
p
=
[
x
1
p
,
x
2
p
,
…
,
x
m
p
]
为第
p
个输入样本
W
⃗
i
=
[
w
1
i
,
w
2
i
,
…
,
w
m
i
]
为第
i
个隐藏层结点径向基函数的中心向量
p
=
1
,
2
,
…
,
P
,
P
为样本总数
w_i为高斯函数中心\\||x_i-w_i||为欧式范数\\\sigma为高斯函数方差\\\vec X^p=[x^p_1,x^p_2,\dots,x^p_m]为第p个输入样本\\\vec W^i=[w^i_1,w^i_2,\dots,w_m^i]为第i个隐藏层结点径向基函数的中心向量\\p=1,2,\dots,P,P为样本总数
wi为高斯函数中心∣∣xi−wi∣∣为欧式范数σ为高斯函数方差Xp=[x1p,x2p,…,xmp]为第p个输入样本Wi=[w1i,w2i,…,wmi]为第i个隐藏层结点径向基函数的中心向量p=1,2,…,P,P为样本总数
径向神经网络的输出为:
y
j
=
∑
i
=
1
h
w
i
j
2
e
−
∣
∣
X
⃗
p
−
W
⃗
i
∣
∣
2
2
σ
2
y_j=\sum_{i=1}^hw^2_{ij}e^{-\frac {||\vec X^p-\vec W^i||^2}{2\sigma^2}}
yj=∑i=1hwij2e−2σ2∣∣Xp−Wi∣∣2
w
i
j
2
为隐藏层第
i
个结点到输出层第
j
个结点的权值
i
=
1
,
2
,
…
,
h
为隐含层节点数
y
j
为神经网络的第
j
个输出结点的实际输出。
w^2_{ij}为隐藏层第i个结点到输出层第j个结点的权值\\i=1,2,\dots,h为隐含层节点数\\y_j为神经网络的第j个输出结点的实际输出。
wij2为隐藏层第i个结点到输出层第j个结点的权值i=1,2,…,h为隐含层节点数yj为神经网络的第j个输出结点的实际输出。 算法得具体步骤如下: 步骤1:基于K-均值聚类方法求取基函数中心:
网络初始化:随机选取h个训练样本作为聚类中心
c
i
(
i
=
1
,
2
,
…
,
h
)
c_i(i=1,2,\dots,h)
ci(i=1,2,…,h);
将输入的训练样本集合按最近邻规则分组:即按照样本
X
⃗
p
\vec X^p
Xp与已选择得聚类中心之间的欧氏距离将样本分配到不同的集合
ϱ
i
(
i
=
1
,
2
,
…
,
h
)
中
\varrho_i(i=1,2,\dots,h)中
ϱi(i=1,2,…,h)中;
重新调整聚类中心:计算各个集合中训练样本得平均值,将这些均值作为新的聚类中心,如果新的聚类中心不在发生变化,则所得到的
c
i
c_i
ci即为神经网络的最终的基函数中心
W
i
W^i
Wi,否则返回2进行下一轮中心求解。 步骤二:求解方差
σ
\sigma
σ: 高斯函数的方差计算公式如下:
σ
=
W
m
a
x
2
h
\sigma=\frac {W_{max}}{\sqrt{2h}}
σ=2hWmax
W
m
a
x
为选取的聚类中心之间的最大距离,
h
为隐藏层结点个数
W_{max}为选取的聚类中心之间的最大距离,h为隐藏层结点个数
Wmax为选取的聚类中心之间的最大距离,h为隐藏层结点个数 步骤3:计算隐藏层和输出层之间的权值:
w
i
j
=
e
h
c
m
a
x
2
∣
∣
X
⃗
p
−
W
⃗
i
∣
∣
2
,
i
=
1
,
2
,
…
,
h
;
p
=
1
,
2
,
…
,
P
w_{ij}=e^{\frac h{c^2_{max}}||\vec X^p-\vec W^i||^2},i=1,2,\dots,h;p=1,2,\dots,P
wij=ecmax2h∣∣Xp−Wi∣∣2,i=1,2,…,h;p=1,2,…,P 从上式中我们可以看出j=p,即输入样本数目等于输出结果数目。