关注公众号,发现CV技术之美
0
写在前面
对比学习已被广泛应用于训练基于Transformer的视觉语言模型的视频文本对齐和多模态表示学习等任务。在本文中,作者提出了一种新的token感知级联对比学习(TACo)算法,该算法利用两种技术改进了以往对比学习的缺点。
第一个是通过考虑单词的句法类别(比如:名词、动词、介词)来计算的token感知的对比损失 。这是由于作者观察到,对于视频-文本对,文本中的内容词(如名词和动词)比功能词(如介词,冠词)更容易与视频中的视觉内容对齐。其次,采用级联采样方法生成一组hard negative实例,以有效的进行多模态融合层的损失估计 。
为了验证TACo的有效性,在实验中,作者微调了一组下游任务的预训练模型,包括文本视频检索(YouCook2、MSR-VTT和ActivityNet)、视频动作定位(CrossTask)、视频动作分割(COIN)。
结果表明,与以往的方法相比,本文的模型在不同的实验设置中取得了一致的改进,在YouCook2、MSR-VTT和ActivityNet的三个公共文本视频检索基准数据集上达到了新的SOTA性能。
1
论文和代码地址

TACo: Token-aware Cascade Contrastive Learning for Video-Text Alignment
论文地址:https://arxiv.org/abs/2108.09980
代码地址:未开源
2
Motivation
在视觉语言(VL)研究的背景下,将语言与视频对齐是一个具有挑战性的主题,因为它需要模型来理解视频中呈现的内容、动态和因果关系。受BERT在自然语言处理中的成功启发,研究人员们对将基于Transformer的多模态模型应用于视频文本对齐和表示学习。
这些模型通常使用对比学习,对大量有噪声视频文本对进行预训练,然后再用zero-shot或者finetune的方式使之适用于各种下游任务中,比如text-video retrieval、video action segmentation、video question answering等等。
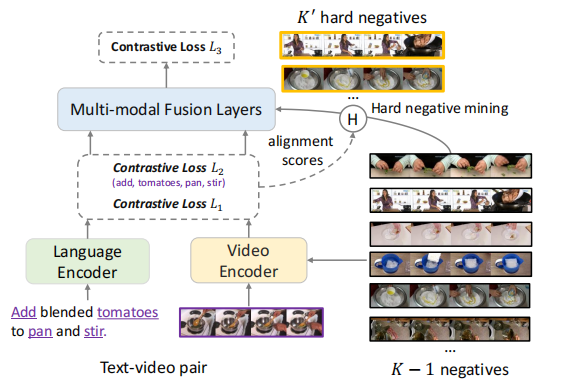
在本文中,作者提出了一种新的对比学习形式,token感知级联对比学习(TACo),以改进大规模预训练和下游特定任务的视频文本对齐。相比于传统的对比学习,TACo主要有两点不同:
第一个是通过考虑单词的句法类来计算的token感知的对比损失 。这是因为给定一个视频及其相应的文本,内容词,如名词和动词,比功能词更有可能与视频中的视觉内容对齐。传统的对比学习通常是在聚合视频和文本中所有帧和所有单词后计算损失(如上图中的损失L1或L3)。
相比之下,token感知的对比损失只使用一个子集计算,这些单词的语法类属于预定义集(例如,名词和动词),这迫使单个单词与视频对齐(即文中的L2损失),比如上图中的施加了特殊注意力的单词就是“add”, “tomatos”,“pan” ,“stir”。
第二种技术是级联采样方法 ,更加有效的训练多模态融合层。考虑一个batch的K个视频文本对。对于每一个视频-文本对,理想的情况是,使用剩余的K−1负视频或文本来计算多模态融合后的对比损失。
然而,考虑到对比损失与多模态融合层耦合时,考虑到其高复杂度
,计算对比损失的成本就会变得很大,其中L是视觉和文本token的总数。解决这一问题的一种方法是使用随机抽样 来选择一小部分负对。
在本文中,作者提出了一种级联采样方法,而不是随机抽样,如图右上方所示(在训练过程中有效地选择一小组非常negative的样本)。它利用了在多模态融合层之前在L1和L2中计算的视频文本对齐分数,更有效地学习多模态融合层,并且没有任何额外的开销。
3
方法
3.1. Framework
如上图所示,TACo的模型结构如上图所示,由三部分组成:
Video encoding module
视频编码模块
,由一系列参数为
的Self-Attention层组成,在这里,输入的视频特征已经使用一些预训练的模型提取,如2D CNN(ResNet)或3D CNN(I3D,S3D)。
给定输入的视频embedding,视频编码器从一个线性层开始,将embedding投影到与自注意层相同的维度d上,一个视频特征就可以表示为
,其中特征数m取决于采样帧率的选择和视频特征提取器。
Language encoding module
语言编码模块
,作者使用预训练的tokenizer和BERT来将输入文本进行token化并提取特征。给定一个句子,首先分别在开头和结尾附加一个“[CLS]”和“[SEP]”。提取特征之后,可以获得一个长度为n的文本特征的序列
。
在这里,作者确保了视频编码器的输出特征维度与语言编码器的输出特征维度相同。在训练过程中,更新语言编码器中的参数
,以适应特定域的文本。
Multi-modal fusion module
多模态融合模块
也是由具有可学习参数
的自注意层组成。它将视频特征
和文本特征
作为输入,然后输出(m+n)长度的特征。
为了帮助模型区分视频和语言token,作者使用一个token类型embedding层来学习两个类型的embedding,并将它们分别添加到视觉和文本token中。与原始的Transformer类似,作者也使用了一个位置embedding层来编码输入序列中的绝对位置。
上述三个组件组成了视频-文本对齐模型,然后用token感知级联对比损失进行训练。
3.2. Contrastive learning: a revisit
给定一组N个视频-文本对
,模型的目标是学习一个最优的评分函数,使得配对的视频和文本
的得分高于所有其他不匹配的对
。从概率的角度来看,将
与
对齐等价于最大化条件概率
,同时最小化所有负对
的概率。其中,
可以表示为:
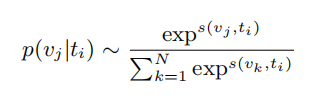
其中,
是v和t之间的对齐分数;分母是所有可能视频的和,用于标准化。在
上加入交叉熵损失,我们可以推导出NCE损失:
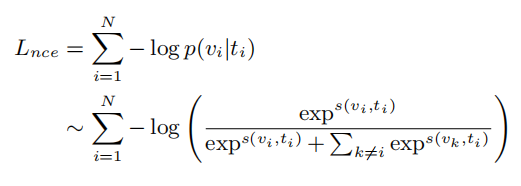
分母需要是数据集中所有视频的和,但这在实践中是很棘手的。因此,通常计算时是在整个数据集采样的K个(K<N)视频文本对上的NCE损失。
理想情况下,能够学习模型的参数
,以最小化上述NCE损失,使
在所有元组
上最大化。
3.3. TACo: our approach
以前使用对比学习的方法有两个问题:首先,损失函数是基于句子级别计算的 (根据[CLS] token或者直接把所有token进行max pool),但是很明显,与功能词相比,内容词(如名词、动词)更有可能与视频中的视觉内容或概念保持一致。
其次,多模态融合层的高计算成本阻碍了大量负样本的使用 ,而这对于对比学习性能的影响是很大的。基于上面两个问题,作者提出了TACo,一种简单而有效的方法来改进对比学习。
给定K个视频文本对
,首先使用视频编码器
和语言编码器
获得一批视频特征和文本特征Y={y_1,...,y_K}∈R^{K×n×d}。
然后平均一个视频中所有的token来得到
,取出每个句子的[cls] token得到
。基于这两个值,就可以得到句子级别的对比学习损失函数了:
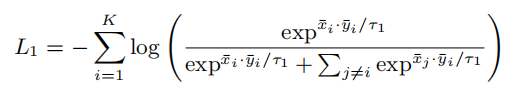
其中,相似度的计算是视频和文本特征之间的点积。基于上面的公式,我们可以使用一个Mini-Batch中的所有K−1负样本来计算损失。通过此方法,优化
和
,以便将视频和文本样本投影到一个对齐的特征空间中。
“[CLS]”token和视频token的平均值忽略了单独token和帧之间的差异,因此可能不会提供将单个token来匹配特定的视觉内容。为了鼓励正确的对齐,除了句子层面损失外,作者还引入了一个token级的对比损失:

是第i个文本中感兴趣的token的索引列表(即 token of interest),
是在第i个文本中第p个token的embedding。
度量视频特征和特定token embedding
之间的相似性。它首先计算
和所有视频token
之间的点积,然后取最大分数作为最终的对齐分数。
根据这两个损失函数,就可以同时计算token级别和sentence级别的对比学习损失函数了。
Token of interest
在token级别的损失函数中,需要判断哪些token包含在
中。在本文中,作者启发式地选择名词和动词作为目标,因为它们在视频中更“具体”。在实践中,同样是名词或动词也具有不同的辨别性。
例如,“人”是一个名词,但信息量比“体操运动员”少。为了反映这一点,作者通过计算不同单词的逆文档频率(IDF),进一步分配具有不同权重的不同单词。较高的IDF意味着它在语料库中更独特,因此在计算token级对比损失时会更重要。
计算损失函数的另一个问题是,由于BERT tokenizer的原因,token通常是一些sub-word。因此,对于所有属于同一单词的token,作者将也分配了相同的权重。
在计算了token感知的对比损失后,然后将来自不同模态的特征传递到多模态融合层,以使它们之间实现更多的交互。与以前的工作相似,取出(m+n)输出的[CLS] token,作为两个模态的综合信息,然后对比损失函数:
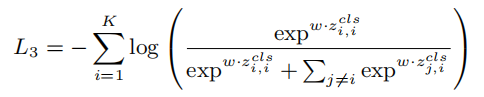
其中z就是特征融合之后的[CLS] token。(这一步的目的是,对应pair融合之后的分数要比不对应的样本融合分数要高,达到对比学习的效果)
但是上面的式子中也有一个问题:由于多模态融合的计算和内存成本很高,我们很难在mini-batch中使用所有的(K−1)负样本。自注意层的
的复杂度使得难以将所有
个pair传递到多模态融合层。
以前的工作通常是随机采样,然而,随机选择负样本可能导致次优学习。因此,作者引入了一种级联采用策略来寻找hard negative,而不是随机negative。
Cascade hard negative sampling
为了解决上面的问题,作者在本文中没有选择随机采样,而是在mini-batch中比较难学的样本对。然而,使用上面的公式计算所有pair的对齐分数,然后选择hard negative是一个“鸡和蛋”的问题。
在本文中,作者根据
和
来选择样本。具体来说,对于每个文本-视频对,我们取
中计算的全局相似性
,通过聚合所有感兴趣token
,来衡量token级别的相似性。
然后,将相似性求和得到给定pair的对齐分数。对于每个文本,选择前
个对齐的负样本视频。然后将得到的
个pair进入多模态融合层。通过这种策略,可以有效地选择hard negative样本。由于多模态融合层有更多的参数来区分正样本和负样本,因此这样的采样策略自然促使了三种对比损失函数之间的合作。
3.4. Objective
本文方法的训练目标是通过最小化上述三个对比损失的组合,找到最优的
:
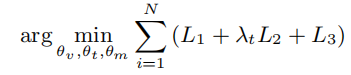
其中,
是token级别损失的权重(默认为0.5)。在推理过程中,通过将三个评分函数的对齐得分相加来进行预测。
4
实验
4.1. Text-video retrieval
4.1.1 Comparing with baselines
Video representations
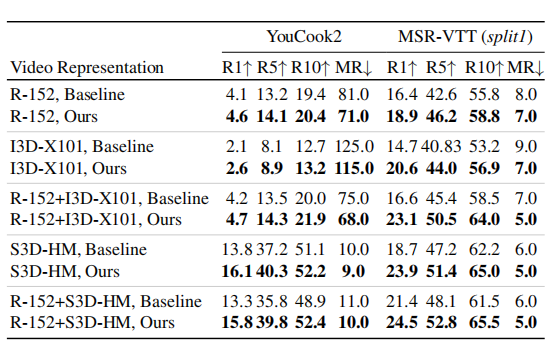
上表展示了不同视频特征下,本文方法和baseline的结果对比,可以看出,本文的方法明显优于baseline方法。
Tokens of Interest
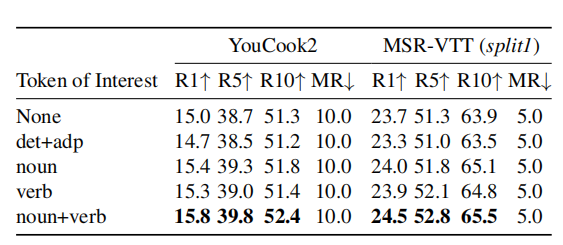
上表展示了不同词作为Tokens of Interest的结果,可以看出,以名词和动词作为Tokens of Interest时结果最好。
4.1.2 Comparing with state-of-the-art
Results on separate datasets
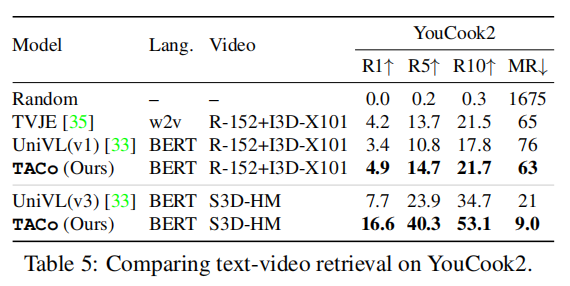

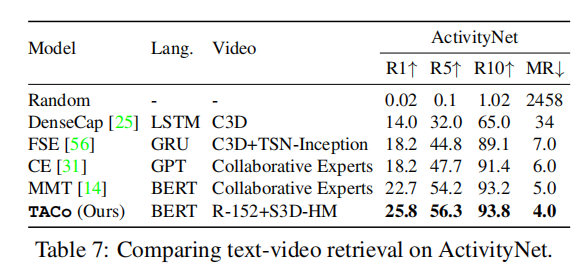
上面三个表格展示了本文方法在三个数据集上和SOTA方法的对比,可以看出,本文的方法在不同数据集上都有性能上的优势。
Zero-shot and finetuned performance
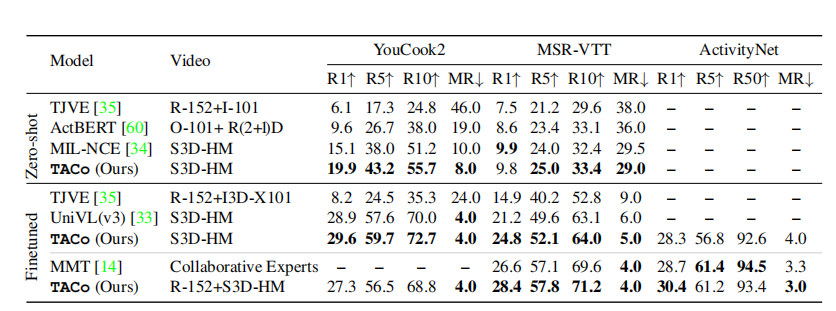
上表展示了zero-shot和finetune下的结果对比(预训练用的数据集是Howto100M)。可以看出TACo有明显的性能优势。
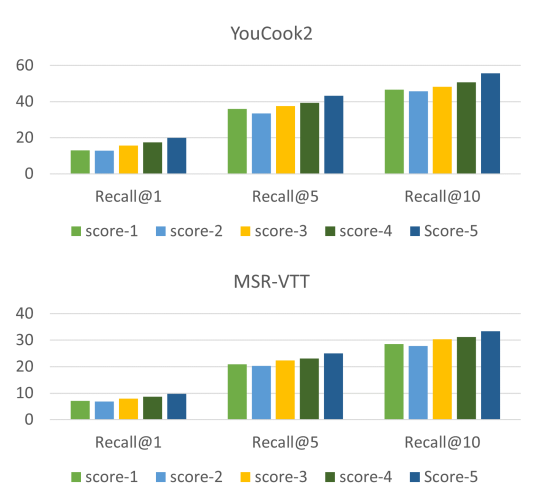
上图展示了当预训练具有不同对比损失的模型时,YouCook2和MSR-VTT上的zero-shot性能。
4.2. Other video-related tasks
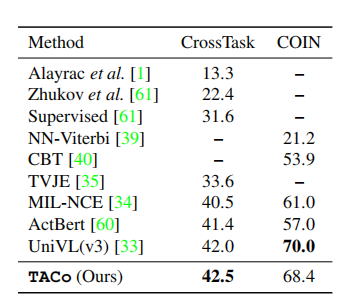
此外,作者还在其他两个任务上验证了本文方法的泛化性,可以看出,本文的方法在其他任务上与其他预训练模型相比,性能也还可以。
5
总结
本文介绍了一种简单而有效的视频-文本对齐的对比学习方法TACo。它旨在解决当前对比学习pipeline中存在的两个问题:多模态融合缺失细粒度对齐 和低效采样 。
在不引入任何额外参数的情况下,本文的方法在各项评估指标下,在三个文本-视频检索基准数据集上,取得了不错的结果。
此外,作者还进一步证明了学习到的特征表示可以有效地转移到其他任务,如action step localization和 action segmentation。
作者介绍
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV
END,入群????备注:CV
