前言:当遇到批量读取大量遥感数据进行运算的时候,如果不进行分段读取操作的话,电脑内存可能面临着不够使用的情况,所以我们要进行分段读取数据然后进行运算,运算结束之后把这段数据保存成tif文件。
1 分段读取数据
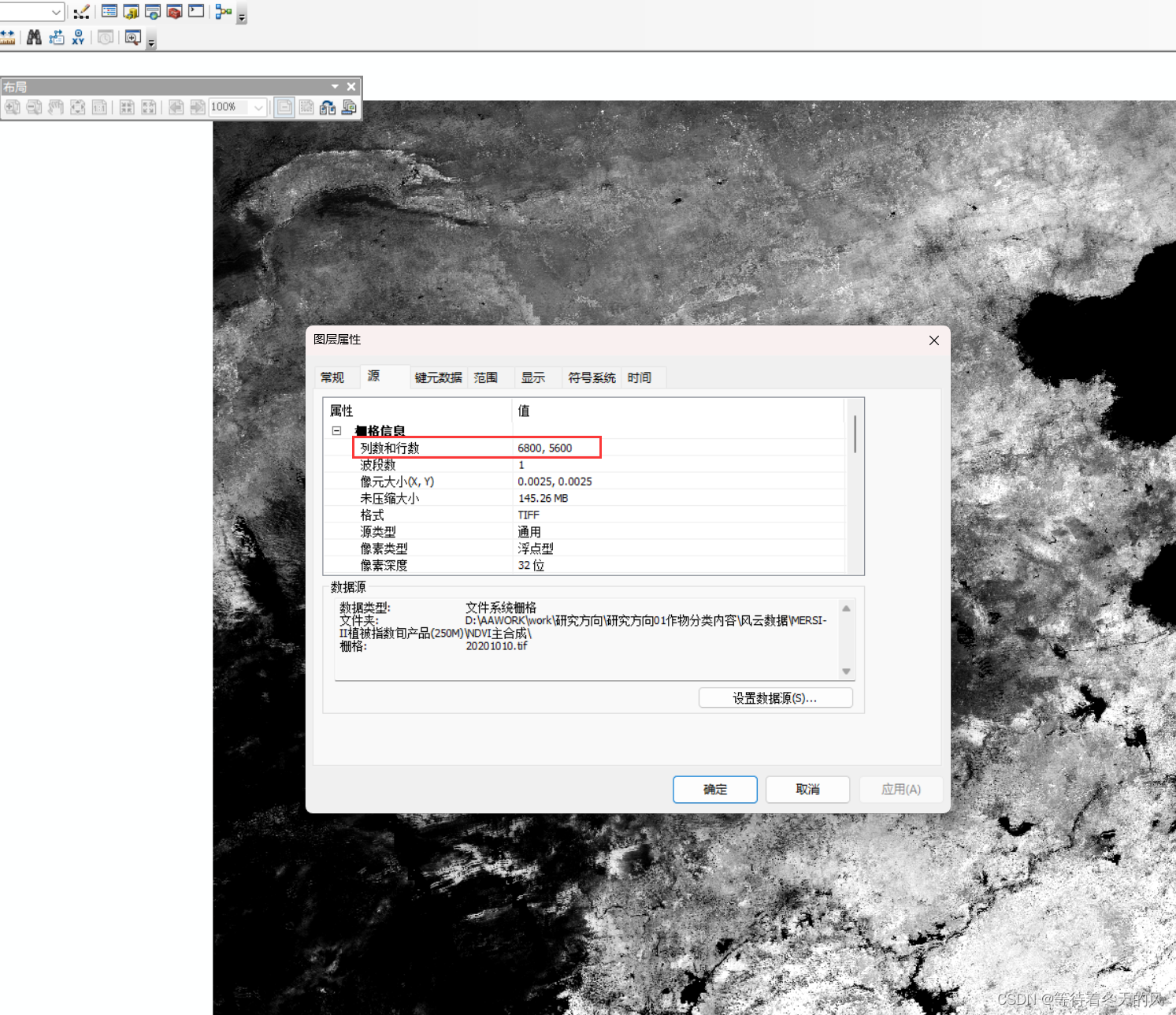
如图所示,有三个这样的数据,且该数据为5600行6800列,我们可以分成10个批次分段读取该TIF数据,10个批次以此为0,560,1120,1680,2240,2800,3360,3920,4480,5040,5600。
代码实现:
import os
import numpy as np
from osgeo import gdal, gdalnumeric
def read_tif(filepath):
dataset = gdal.Open(filepath)
col = dataset.RasterXSize#图像长度
row = dataset.RasterYSize#图像宽度
geotrans = dataset.GetGeoTransform()#读取仿射变换
proj = dataset.GetProjection()#读取投影
data = dataset.ReadAsArray()#转为numpy格式
data = data.astype(np.float32)
# a = data[0][0]
# data[data == a] = np.nan
data[data <= -3] = np.nan
return [col, row, geotrans, proj, data]
def read_tif02(file):
data = gdalnumeric.LoadFile(file)
data = data.astype(np.float32)
# a = data[0][0]
# data[data == a] = np.nan
data[data <= -3] = np.nan
return data
def get_all_file_name(ndvi_file):
list1=[]
if os.path.isdir(ndvi_file):
fileList = os.listdir(ndvi_file)
for f in fileList:
file_name= ndvi_file+"\\"+f
list1.append(file_name)
return list1
else:
return []
if __name__ == '__main__':
file_ndvi = r"D:\AAWORK\work\研究方向\研究方向01作物分类内容\风云数据\MERSI-II植被指数旬产品(250M)\NDVI主合成"
file_out = r"D:\AAWORK\work\2021NDVISUM.tif"
ndvi_file_list = get_all_file_name(file_ndvi)
col00, row00, geotrans00, proj00, data_00_ndvi = read_tif(ndvi_file_list[0])
data_01_ndvi = read_tif02(ndvi_file_list[1])
data_02_ndvi = read_tif02(ndvi_file_list[2])
list_row = [0,560,1120,1680,2240,2800,3360,3920,4480,5040,5600]
for index,i in enumerate(list_row):
if index <= len(list_row)-2:
print(list_row[index],list_row[index+1])
#分段进行操作
# sum_list = get_section(list_row[index],list_row[index+1],col00,data_00_ndvi,data_01_ndvi,data_02_ndvi)
# 分段进行保存
# save_section(sum_list, list_row[index], list_row[index+1], col00,data_00_ndvi,data_01_ndvi,data_02_ndvi)
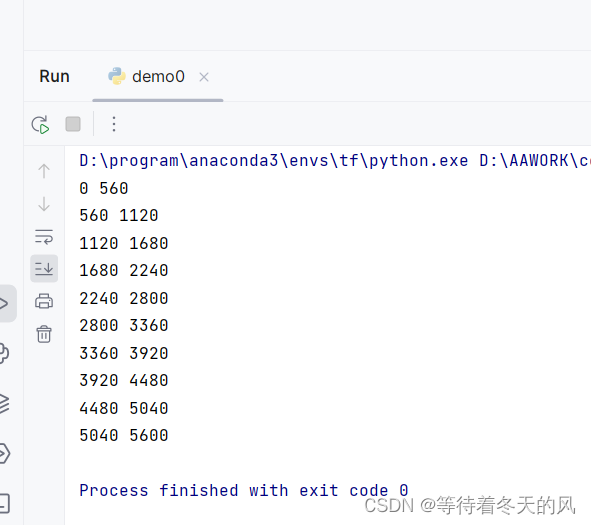
2 实现分批读取数据以及进行计算
拿到开始的行和结束的行数,进行分批读取数据并进行计算,(这里求和求的是整数,如有需要的话可以自己更改)代码如下:
import os
import tensorflow as tf
import numpy as np
import pandas as pd
from osgeo import gdal, gdalnumeric
def get_sum_list(data_list):
list1 = []
for data in data_list:
sum = 0
for d in data:
if not np.isnan(d):
sum = sum+d
list1.append(int(sum))
return list1
def read_tif(filepath):
dataset = gdal.Open(filepath)
col = dataset.RasterXSize#图像长度
row = dataset.RasterYSize#图像宽度
geotrans = dataset.GetGeoTransform()#读取仿射变换
proj = dataset.GetProjection()#读取投影
data = dataset.ReadAsArray()#转为numpy格式
data = data.astype(np.float32)
# a = data[0][0]
# data[data == a] = np.nan
data[data <= -3] = np.nan
return [col, row, geotrans, proj, data]
def read_tif02(file):
data = gdalnumeric.LoadFile(file)
data = data.astype(np.float32)
# a = data[0][0]
# data[data == a] = np.nan
data[data <= -3] = np.nan
return data
def get_all_file_name(ndvi_file):
list1=[]
if os.path.isdir(ndvi_file):
fileList = os.listdir(ndvi_file)
for f in fileList:
file_name= ndvi_file+"\\"+f
list1.append(file_name)
return list1
else:
return []
def get_nan_sum(ndvi_list):
"""
得到NAN数据的个数
:param ndvi_list:
:return:
"""
count = 0
for ndvi in ndvi_list:
if np.isnan(ndvi):
count = count+1
return count
def get_section(row0, row1, col1,data1,data2,data3):
"""
分段读取数据,读取的数据进行计算
:param row0:
:param row1:
:param col1:
:param data1:
:param data2:
:param data3:
:return:
"""
list1 = []
for i in range(row0, row1): # 行
for j in range(0, col1): # 列
ndvi_list = []
ndvi_list.append(data1[i][j])
ndvi_list.append(data2[i][j])
ndvi_list.append(data3[i][j])
if get_nan_sum(ndvi_list)>1:
pass
else:
list1.append(ndvi_list)
ndvi_list = None
sum_list = get_sum_list(list1)
list1 = None
return sum_list
if __name__ == '__main__':
file_ndvi = r"D:\AAWORK\work\研究方向\研究方向01作物分类内容\风云数据\MERSI-II植被指数旬产品(250M)\NDVI主合成"
file_out = r"D:\AAWORK\work\2021NDVISUM.tif"
ndvi_file_list = get_all_file_name(file_ndvi)
col00, row00, geotrans00, proj00, data_00_ndvi = read_tif(ndvi_file_list[0])
data_01_ndvi = read_tif02(ndvi_file_list[1])
data_02_ndvi = read_tif02(ndvi_file_list[2])
list_row = [0,560,1120,1680,2240,2800,3360,3920,4480,5040,5600]
for index,i in enumerate(list_row):
if index <= len(list_row)-2:
print(list_row[index],list_row[index+1])
#分段进行操作
sum_list = get_section(list_row[index],list_row[index+1],col00,data_00_ndvi,data_01_ndvi,data_02_ndvi)
print(np.array(sum_list))
# 分段进行保存
# save_section(sum_list, list_row[index], list_row[index+1], col00,data_00_ndvi,data_01_ndvi,data_02_ndvi)

3 实现分批保存成TIF文件(所有完整代码)
在2中已经得到了每一批的list结果,我们拿到list结果之后,可以进行保存成tif文件。代码如下:
import os
import numpy as np
from osgeo import gdal, gdalnumeric
def get_sum_list(data_list):
list1 = []
for data in data_list:
sum = 0
for d in data:
if not np.isnan(d):
sum = sum+d
list1.append(int(sum))
return list1
def read_tif(filepath):
dataset = gdal.Open(filepath)
col = dataset.RasterXSize#图像长度
row = dataset.RasterYSize#图像宽度
geotrans = dataset.GetGeoTransform()#读取仿射变换
proj = dataset.GetProjection()#读取投影
data = dataset.ReadAsArray()#转为numpy格式
data = data.astype(np.float32)
# a = data[0][0]
# data[data == a] = np.nan
data[data <= -3] = np.nan
return [col, row, geotrans, proj, data]
def read_tif02(file):
data = gdalnumeric.LoadFile(file)
data = data.astype(np.float32)
# a = data[0][0]
# data[data == a] = np.nan
data[data <= -3] = np.nan
return data
def get_all_file_name(ndvi_file):
list1=[]
if os.path.isdir(ndvi_file):
fileList = os.listdir(ndvi_file)
for f in fileList:
file_name= ndvi_file+"\\"+f
list1.append(file_name)
return list1
else:
return []
def save_tif(data, file, output):
"""
保存成tif
:param data:
:param file:
:param output:
:return:
"""
ds = gdal.Open(file)
shape = data.shape
driver = gdal.GetDriverByName("GTiff")
dataset = driver.Create(output, shape[1], shape[0], 1, gdal.GDT_Float32)#保存的数据类型
dataset.SetGeoTransform(ds.GetGeoTransform())
dataset.SetProjection(ds.GetProjection())
dataset.GetRasterBand(1).WriteArray(data)
def get_nan_sum(ndvi_list):
"""
得到NAN数据的个数
:param ndvi_list:
:return:
"""
count = 0
for ndvi in ndvi_list:
if np.isnan(ndvi):
count = count+1
return count
def get_section(row0, row1, col1,data1,data2,data3):
"""
分段读取数据,读取的数据进行计算
:param row0:
:param row1:
:param col1:
:param data1:
:param data2:
:param data3:
:return:
"""
list1 = []
for i in range(row0, row1): # 行
for j in range(0, col1): # 列
ndvi_list = []
ndvi_list.append(data1[i][j])
ndvi_list.append(data2[i][j])
ndvi_list.append(data3[i][j])
if get_nan_sum(ndvi_list)>1:
pass
else:
list1.append(ndvi_list)
ndvi_list = None
sum_list = get_sum_list(list1)
list1 = None
return sum_list
def save_section(sum_list, row0, row1, col1,data1,data2,data3):
"""
保存分段的数据
:param sum_list:
:param row0:
:param row1:
:param col1:
:param data1:
:param data2:
:param data3:
:return:
"""
file = r"D:\AAWORK\work\研究方向\研究方向01作物分类内容\风云数据\MERSI-II植被指数旬产品(250M)\kongbai_zhu_250m.tif"#这是一个空白数据,每个像元的值为0
data = read_tif02(file)
m = 0
for i in range(row0, row1): # 行
for j in range(0, col1): # 列
ndvi_list = []
ndvi_list.append(data1[i][j])
ndvi_list.append(data2[i][j])
ndvi_list.append(data3[i][j])
if get_nan_sum(ndvi_list)>1:
pass
else:
data[i][j] = sum_list[m]
m = m + 1
save_tif(data,file,file_out.replace(".tif","_"+str(row0)+"_"+str(row1)+".tif"))
data = None
if __name__ == '__main__':
file_ndvi = r"D:\AAWORK\work\研究方向\研究方向01作物分类内容\风云数据\MERSI-II植被指数旬产品(250M)\NDVI主合成"
file_out = r"D:\AAWORK\work\2021NDVISUM.tif"
ndvi_file_list = get_all_file_name(file_ndvi)
col00, row00, geotrans00, proj00, data_00_ndvi = read_tif(ndvi_file_list[0])
data_01_ndvi = read_tif02(ndvi_file_list[1])
data_02_ndvi = read_tif02(ndvi_file_list[2])
list_row = [0,560,1120,1680,2240,2800,3360,3920,4480,5040,5600]
for index,i in enumerate(list_row):
if index <= len(list_row)-2:
print(list_row[index],list_row[index+1])
#分段进行操作
sum_list = get_section(list_row[index],list_row[index+1],col00,data_00_ndvi,data_01_ndvi,data_02_ndvi)
print(np.array(sum_list))
# 分段进行保存
save_section(sum_list, list_row[index], list_row[index+1], col00,data_00_ndvi,data_01_ndvi,data_02_ndvi)
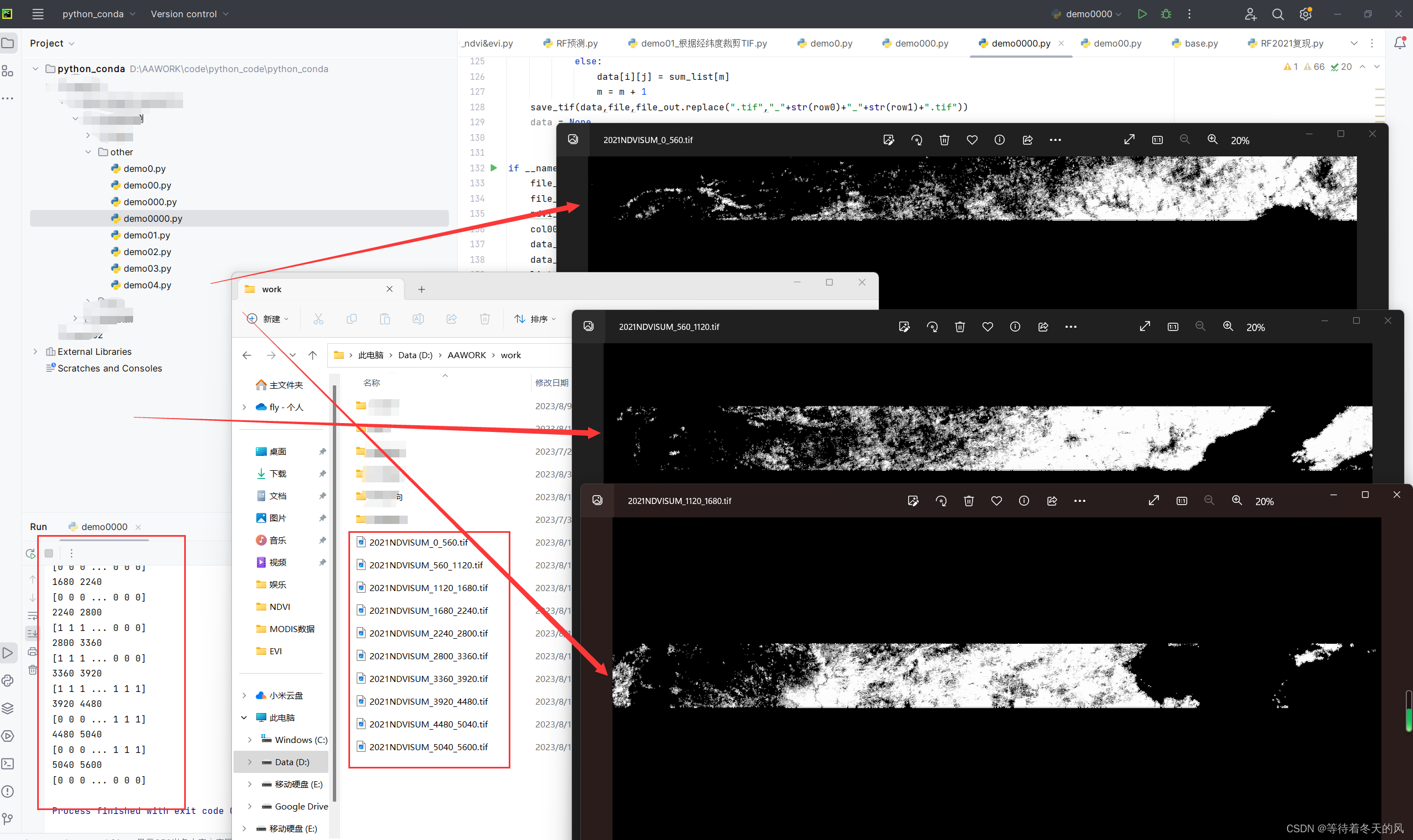

4 分段TIF整合到一个TIF
我们要把上述10个TIF文件整合到一个TIF文件里,方法很多,我这里提供一个方法,供大家使用,代码如下:
import os
from osgeo import gdalnumeric, gdal
import numpy as np
def get_all_file_name(file):
list1=[]
if os.path.isdir(file):
fileList = os.listdir(file)
for f in fileList:
file_name= file+"\\"+f
list1.append(file_name)
return list1
else:
return []
def read_tif(filepath):
dataset = gdal.Open(filepath)
col = dataset.RasterXSize#图像长度
row = dataset.RasterYSize#图像宽度
geotrans = dataset.GetGeoTransform()#读取仿射变换
proj = dataset.GetProjection()#读取投影
data = dataset.ReadAsArray()#转为numpy格式
data = data.astype(np.float32)
# a = data[0][0]
# data[data == a] = np.nan
data[data <= -3] = np.nan
return [col, row, geotrans, proj, data]
def read_tif02(file):
data = gdalnumeric.LoadFile(file)
data = data.astype(np.float32)
# a = data[0][0]
# data[data == a] = np.nan
data[data <= -3] = np.nan
return data
def save_tif(data, file, output):
ds = gdal.Open(file)
shape = data.shape
driver = gdal.GetDriverByName("GTiff")
dataset = driver.Create(output, shape[1], shape[0], 1, gdal.GDT_Int16)#保存的数据类型
dataset.SetGeoTransform(ds.GetGeoTransform())
dataset.SetProjection(ds.GetProjection())
dataset.GetRasterBand(1).WriteArray(data)
if __name__ == '__main__':
file_path = r"D:\AAWORK\work\分段数据"
file_out = r"D:\AAWORK\work\2021NDVISUM.tif"
file_list = get_all_file_name(file_path)
data_all = read_tif02(r"D:\AAWORK\work\研究方向\研究方向01作物分类内容\风云数据\MERSI-II植被指数旬产品(250M)\kongbai_zhu_250m.tif")
for file in file_list:
data = read_tif02(file)
data_all = data_all+data
save_tif(data_all,r"D:\AAWORK\work\研究方向\研究方向01作物分类内容\风云数据\MERSI-II植被指数旬产品(250M)\kongbai_zhu_250m.tif",file_out)

5 生成一个空白TIF(每个像元值为0的TIF)
思路比较简单,就是遍历每个像元,然后把每个像元的值设置为0,设置为其它可以,然后再进行保存。
from osgeo import gdal
import numpy as np
def read_tif(filepath):
dataset = gdal.Open(filepath)
col = dataset.RasterXSize#图像长度
row = dataset.RasterYSize#图像宽度
geotrans = dataset.GetGeoTransform()#读取仿射变换
proj = dataset.GetProjection()#读取投影
data = dataset.ReadAsArray()#转为numpy格式
data = data.astype(np.float32)
# a = data[0][0]
# data[data == a] = np.nan
# data[data <= -3] = np.nan
return [col, row, geotrans, proj, data]
def save_tif(data, file, output):
ds = gdal.Open(file)
shape = data.shape
driver = gdal.GetDriverByName("GTiff")
dataset = driver.Create(output, shape[1], shape[0], 1, gdal.GDT_Int16)#保存的数据类型
dataset.SetGeoTransform(ds.GetGeoTransform())
dataset.SetProjection(ds.GetProjection())
dataset.GetRasterBand(1).WriteArray(data)
if __name__ == '__main__':
file_path = r"D:\AAWORK\work\2021NDVISUM.tif"
file_out = r"D:\AAWORK\work\kongbai.tif"
col, row, geotrans, proj, data = read_tif(file_path)
for i in range(0,row):
for j in range(0,col):
data[i][j] = 0
save_tif(data,file_path,file_out)