现有用户行为日志表tb_user_log
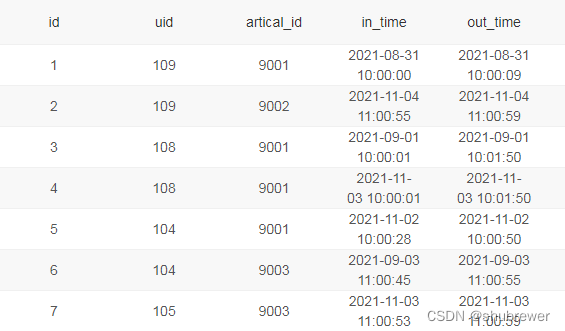
问题:统计活跃间隔对用户分级后,各活跃等级用户占比,结果保留两位小数,且按占比降序排序。
注:
- 用户等级标准简化为:忠实用户(近7天活跃过且非新晋用户)、新晋用户(近7天新增)、沉睡用户(近7天未活跃但更早前活跃过)、流失用户(近30天未活跃但更早前活跃过)。
- 假设今天就是数据中所有日期的最大值。
- 近7天表示包含当天T的近7天,即闭区间[T-6, T]。

问题分解:
-
计算每个用户最早最晚活跃日期(作为子表t_uid_first_last):
- 按用户ID分组:GROUP BY uid
- 统计最早活跃:MIN(DATE(in_time)) as first_dt
- 统计最晚活跃:MAX(DATE(out_time)) as last_dt
-
计算当前日期和总用户数(作为子表t_overall_info):
- 获取当前日期:MAX(DATE(out_time)) as cur_dt
- 统计总用户数:COUNT(DISTINCT uid) as user_cnt
-
左连接两表,即将全表统计信息追加到每一行上:t_uid_first_last LEFT JOIN t_overall_info ON 1
-
计算最早最晚活跃离当前天数差(作为子表t_user_info):
- 最早活跃距今天数:TIMESTAMPDIFF(DAY,first_dt,cur_dt) as first_dt_diff
- 最晚(最近)活跃距今天数:TIMESTAMPDIFF(DAY,last_dt,cur_dt) as last_dt_diff
-
计算每个用户的活跃等级:
| 1 2 3 4 5 6 |
CASE
WHEN last_dt_diff >= 30 THEN "流失用户"
WHEN last_dt_diff >= 7 THEN "沉睡用户"
WHEN first_dt_diff < 7 THEN "新晋用户"
ELSE "忠实用户"
END as user_grade
|
-
统计每个等级的占比:
完整代码:
SELECT user_grade, ROUND(COUNT(uid) / MAX(user_cnt), 2) as ratio
FROM (
SELECT uid, user_cnt,
CASE
WHEN last_dt_diff >= 30 THEN "流失用户"
WHEN last_dt_diff >= 7 THEN "沉睡用户"
WHEN first_dt_diff < 7 THEN "新晋用户"
ELSE "忠实用户"
END as user_grade
FROM (
SELECT uid, user_cnt,
TIMESTAMPDIFF(DAY,first_dt,cur_dt) as first_dt_diff,
TIMESTAMPDIFF(DAY,last_dt,cur_dt) as last_dt_diff
FROM (
SELECT uid, MIN(DATE(in_time)) as first_dt,
MAX(DATE(out_time)) as last_dt
FROM tb_user_log
GROUP BY uid
) as t_uid_first_last
LEFT JOIN (
SELECT MAX(DATE(out_time)) as cur_dt,
COUNT(DISTINCT uid) as user_cnt
FROM tb_user_log
) as t_overall_info ON 1=1
) as t_user_info
) as t_user_grade
GROUP BY user_grade
ORDER BY ratio DESC;
最后附上原数据表方便大家练习:
DROP TABLE IF EXISTS tb_user_log;
CREATE TABLE tb_user_log (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
uid INT NOT NULL COMMENT '用户ID',
artical_id INT NOT NULL COMMENT '视频ID',
in_time datetime COMMENT '进入时间',
out_time datetime COMMENT '离开时间',
sign_in TINYINT DEFAULT 0 COMMENT '是否签到'
) CHARACTER SET utf8 COLLATE utf8_bin;
INSERT INTO tb_user_log(uid, artical_id, in_time, out_time, sign_in) VALUES
(109, 9001, '2021-08-31 10:00:00', '2021-08-31 10:00:09', 0),
(109, 9002, '2021-11-04 11:00:55', '2021-11-04 11:00:59', 0),
(108, 9001, '2021-09-01 10:00:01', '2021-09-01 10:01:50', 0),
(108, 9001, '2021-11-03 10:00:01', '2021-11-03 10:01:50', 0),
(104, 9001, '2021-11-02 10:00:28', '2021-11-02 10:00:50', 0),
(104, 9003, '2021-09-03 11:00:45', '2021-09-03 11:00:55', 0),
(105, 9003, '2021-11-03 11:00:53', '2021-11-03 11:00:59', 0),
(102, 9001, '2021-10-30 10:00:00', '2021-10-30 10:00:09', 0),
(103, 9001, '2021-10-21 10:00:00', '2021-10-21 10:00:09', 0),
(101, 0, '2021-10-01 10:00:00', '2021-10-01 10:00:42', 1);