raft共识算法
raft是一种分布式一致性算法;
tikv server通过raft算法保证数据的强一致性;pd server也是通过raft来保证数据的一致性;
Raft下读写是如何工作的?
读写都是通过leader;follower只有选举和备份的作用,读写都不经过follower;learner只有复制的作用,没有选举权;
leader选举(leader election)
两个超时控制选举:
- election timeout, 选举超时,就是follower等待成为candidate的时间,是150ms到300ms的随机值;
- heartbeat timeout,心跳超时,要小于150ms,即小于election timeout;
选举超时后,follower成为candidate,开始新一轮选举,election term(任期)加一;follower给自己投上一票,然后向其它节点拉票;如果其他节点还没有投票,那么就投给这个candidate;收到拉票请求后,其它节点重置它的选举超时;candidate获得大多数的选票的时候,就成为leader。leader在心跳超时(heartbeat timeout)内,向其它节点同步自身的变化,follower节点收到通知后给leader回复;当前选举周期一直持续到某个follower节点收不到heartbeat,从而成为candidate。
follower成为candidate后,需要做以下事情:
- election term加一;
- 给自己投一票;
- 重置election timeout;
follower收到拉票请求后,需要做以下事情:
- 重置election timeout;
- election term加一
- 只会给第一个拉票的candidate投票;
收到heartbeat也需要重置election timeout;
日志复制(log replication)
所有的写操作,都需要通过leader节点;leader先将写操作写入log(WAL日志),并没有提交;之后将log发送给follower节点,follower节点会写入自己的WAL日志,之后回复leader节点;leader节点获得大多数节点的应答后,再进行提交,之后将结果回复给client;最后再通知follwer节点落盘;
网络分区(network partitions, 脑裂)
比如集群一共有5个节点,由于网络故障,分成两个分区A, B;A有3个节点,B有2个节点,原先的leader节点在B中,A会重新选举出一个新的leader;对于A的写操作,由于大多数原则,最终会commit;对于B,因为不满足大多数原则,所以不会commit。
网络恢复后,raft如何恢复一致性?
网络恢复后,B会回滚未提交的日志,并且会同步A的数据;主要是因为A的election term比B大,最终A中的leader会成为整个集群的leader;
election term的作用?
解决网络分区问题;
Region
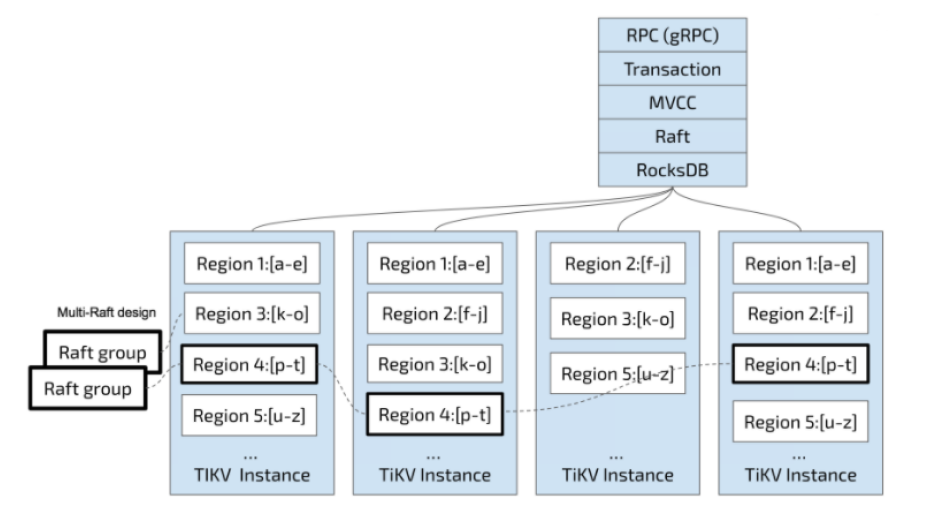
tikv将整个key-value空间分为很多段,每一段是一系列连续的key,每一段叫做一个region;
以region为单位,将数据分散在集群中的所有tikv节点上,并且尽量保证每个节点上的region数量差不多;这是pd server的主要工作;
每一个region有一个主节点,还有多个replica,它们之间通过raft算法来进行数据的同步,组成一个raft group;保证了tidb的强一致性和高可用性;
region的数据同步,跟MVCC息息相关;
分布式事务
关系型数据库,重点是事务;事务的重点是隔离级别,MVCC;隔离级别通过一定程度破坏一致性,来提高并发能力;不同的隔离级别对应不同的异常情况;
tidb分布式事务采用的是Percolator模型;本质是一个二阶段提交;
二阶段提交
二阶段提交是将事务的提交过程分成了两个阶段来进行处理;目的是使分布式系统架构下的所有节点在进行事务处理过程中能够保持原子性和一致性;二阶段提交能够非常方便地完成所有分布式事务参与者的协调,统一决定事务的提交或回滚;
传统的分布式事务所实现的二阶段提交如下图:
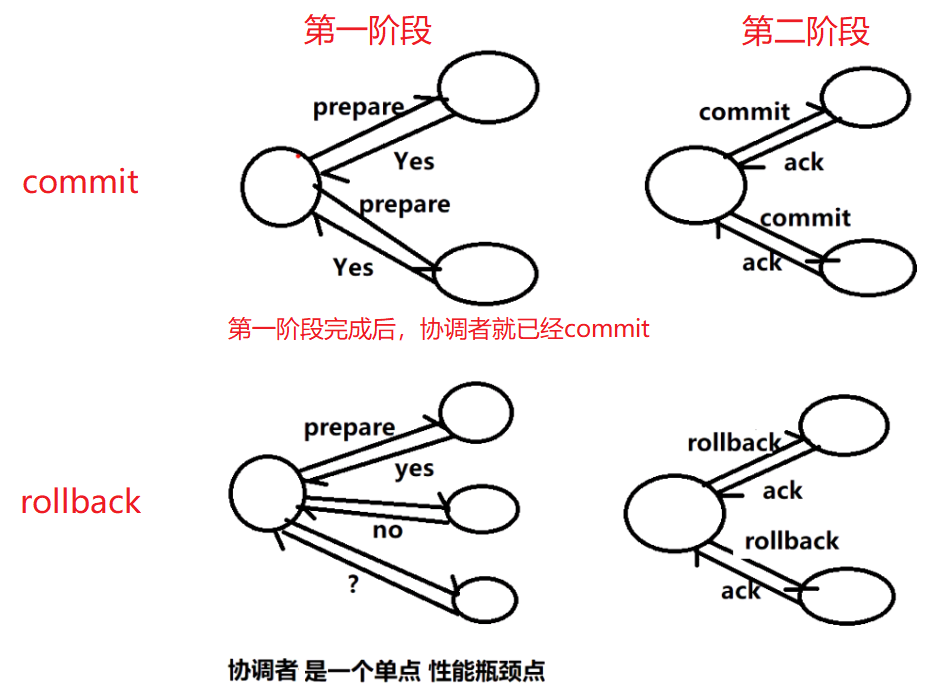
二阶段提交将一个事务的处理过程分为了投票和执行两个阶段;核心是对每个事务都采用先尝试后提交的处理方式。
在分布式的场景下,有可能会出现第一阶段后某个参与者与协调者的连接中断,此时这个参与者并不清楚这个事务到底最终是提交了还是被回滚了,因为理论上来说,协调者在第一阶段结束后,如果确认收到所有参与者都已经将数据落盘,那么即可标注这个事务提交成功。然后进入第二阶段,但是第二阶段如果某参与者没有收到 COMMIT 消息,那么在这个参与者复活以后,它需要到一个地方去确认本地这个事务后来到底有没有成功被提交,此时就需要事务管理器的介入。这个事务管理器在整个系统中是个单点,是一个性能瓶颈;比如mysql集群解决方法mycat中就有单点问题;
percolator
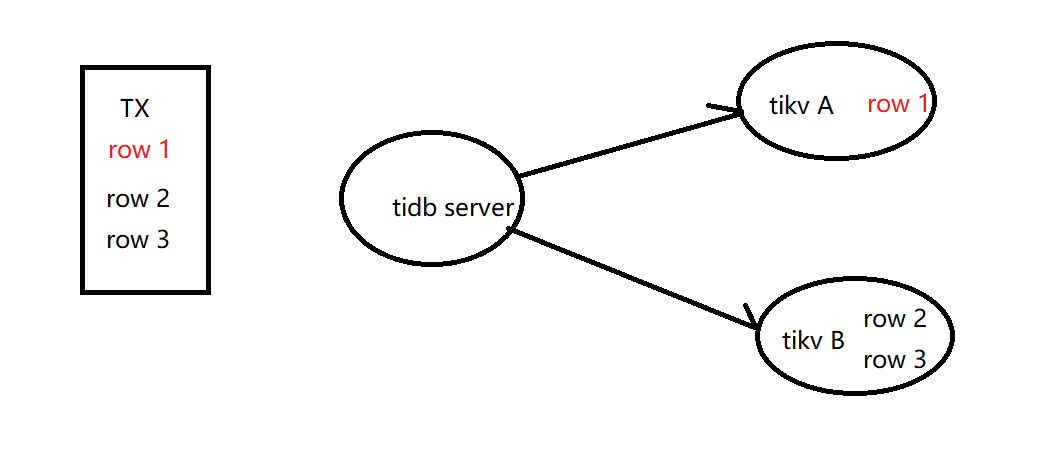
percolator是一个去中心化的方案,本质是二阶段提交;tidb中的协调者就是tidb server;
事务开始时,tidb server会从pd leader上获取一个timestamp,之后使用这个ts作为标记这个事务的唯一id;标准的 percolator 模型采用的是乐观事务模型,在提交之前,会收集所有参与修改的行(key-value pairs),从里面随机选一行,作为这个事务的 primary row,剩下的行自动作为 secondary rows;primary row是随机的,它的意义就是负责标记这个事务的完成状态,解决传统二阶段提交中的单点问题;在选出primary row后,开始二阶段提交;只是tikv节点对于事物是否完成的状态查询,可以通过primary row来完成,解决了单点的性能瓶颈;
为什么可以通过primary row就可以确定整个事务的完成状态?
因为事务的原子性;要么都成功,要么都失败;
隔离级别
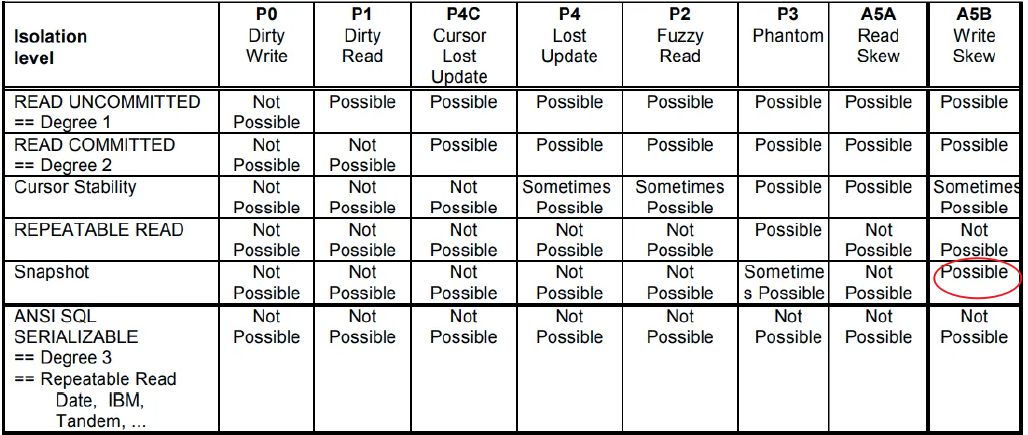
tidb支持snapshot隔离级别;是比reapeatale read更高的隔离级别;解决幻读,但是存在写偏序的问题;
snapshot isolation
- 事务的读操作从Commited快照中读数据,快照时间可以是事务的第一次读操作之前的任意时间,记作StartTimestamp;
- 事务准备提交时,获取一个CommitTimestamp,它需要比现存的StartTimestamp和CommitTimestamp都大;
- 事务提交时进行冲突检查,如果没有其它事务在[StartTS, commitTS]区间内提交了与自己的WriteSet有交集的数据,则本事务可以提交;这里阻止了Lost Update异常;
- SI允许事务用很旧的CommitTS来执行,从而不被任何的写操作阻塞,或者读一个历史数据;当然,如果使用一个很旧的CommitTS来提交,事务大概率是会被Abort的;
写偏序如何解决?
读加锁
tidb没有共享锁,只有排它锁;
select * from table for update;
MVCC
多版本并发控制,提供一致性非锁定读;tikv中的MVCC是分布式的,不能用rocksdb的MVCC;rocksdb的MVCC是本地的,它利用了snapshot(sequence number)来实现;tikv的MVCC,利用timestamp oracle来实现;tikv的MVCC实现是通过在key后面添加版本号(version)来实现,version实际就是timestamp,全局时钟,确定分布式系统中事务的tx id;
region的数据同步,跟MVCC是息息相关的,因为只有version数据同步了,才能够支持分布式的MVCC;
Key1_Version3 -> Value
Key1_Version2 -> Value
Key1_Version1 -> Value
……
Key2_Version4 -> Value
Key2_Version3 -> Value
Key2_Version2 -> Value
Key2_Version1 -> Value
……
KeyN_Version2 -> Value
KeyN_Version1 -> Value
TiFlash
tidb是一款分布式HTAP数据库,有两种存储节点,分别是tikv和tiflash;tikv将数据分为region存储,底层使用了rocksdb存储,是行式存储,适合TP类型的业务;而tiflash采用列式存储,适合AP类型的业务;tiflash也在tikv的raft集群中,tiflash作为leaner,从tikv节点实时同步数据,拥有毫秒级别的延迟,以及非常优秀的数据分析性能;
kv和tiflash;tikv将数据分为region存储,底层使用了rocksdb存储,是行式存储,适合TP类型的业务;而tiflash采用列式存储,适合AP类型的业务;tiflash也在tikv的raft集群中,tiflash作为leaner,从tikv节点实时同步数据,拥有毫秒级别的延迟,以及非常优秀的数据分析性能;
tiflash的数据结构融合了B+树和LSM-Tree的优点;B+树读性能高,LSM-Tree写性能高;LSM-Tree写放大很大,优化写放大;