1 简介
1.1 大规模快速演进
Facebook 的生产网络本身就是一个大型分布式系统,针对不同任务划分成不同层次并采 用不同的技术(a large distributed system with specialized tiers and technologies):
- 边缘(edge)
- 骨干(backbone)
- 数据中心(data centers)
我们基础设施的核心设计哲学是具备下面两种能力:
- 快速演进(move fast)
- 支撑快速增长(support rapid growth)
同时还需要保证IDC的基础设施架构需要足够简单,以方便工程师进行运维。
1.2 集群方式的限制
我们以前的数据中心网络是基于集群构建的(built using clusters)。
- 一个集群是一个大型部署单元(a large unit of deployment)
- 包括几百个机柜及相应的置顶交换机(TOR switches)
- 通过一组大型、多端口集群交换机(large, high-radix cluster switches)对 TOR 做汇聚
这种集群方式的缺点是很明显的,主要是:
- 集群大小受限于集群交换机的端口密度(port density of the cluster switch)。要构建最大的集群,我们就需要最大的网络设备,而这些设备只能从有限 几家供应商那里买到;
- 一个盒子上有这么多端口,与我们“提供尽可能的最高带宽基础设施”目标有 冲突。当接口速度演进到下一个级别时(例如 10G 到 25G),支持新速度而又如 此高密度的盒子并不能很快出来;
- 数据中心的大面积区域都依赖少数几个盒子,那硬件和软 件故障将导致严重的后果;
- 更难的是,如何在集群大小(cluster size)、机柜带宽(rack bandwidth)和 出集群带宽(bandwidth out of the cluster)之间维护一个最优的长期平衡( optimal long-term balance);
传统上,集群间的连接是超售的(oversubscribed,与收敛比是类似的概念),集群 内的带宽要比集群间的带宽大得多。这假设并要求大部分应用内通信( intra-application communications)都要发生在集群内部。但我们的应用是分布式扩展的 ,不应受限于这种边界。我们的数据中心一般都会有很多集群,不仅集群内的机器到机器流 量在增长,跨集群的机器到机器流量也在不断增长。将更多端口用于集群互联能缓解这 个问题。但流量的快速和动态增长,使得这种平衡流量的方式永无尽头。
2 fabric设计
在设计下一代数据中心网络时,我们步子迈地比较大,将整个数据中心建筑(data center building)设计为单个高性能网络,而非众多集群组成的层级化超售系统( hierarchically oversubscribed system of clusters)。 我们还希望每次扩展容量时,在不淘汰或对存量基础设施进行定制的前提下,能有一个清晰 、简单的快速网络部署(rapid network deployment)和性能扩展(performance scalability)路径。
为实现这个目标,我们采取了一种分散(disaggregated)的方式:弃用大型设备和集 群,而是将网络分割为很多小型、无差别的基本单元 —— server pods(服务器独立交 付单元)—— 并在数据中心的所有 POD 之间创建统一的高性能连接。
2.1 POD概念
一个POD的网络结构图如下:
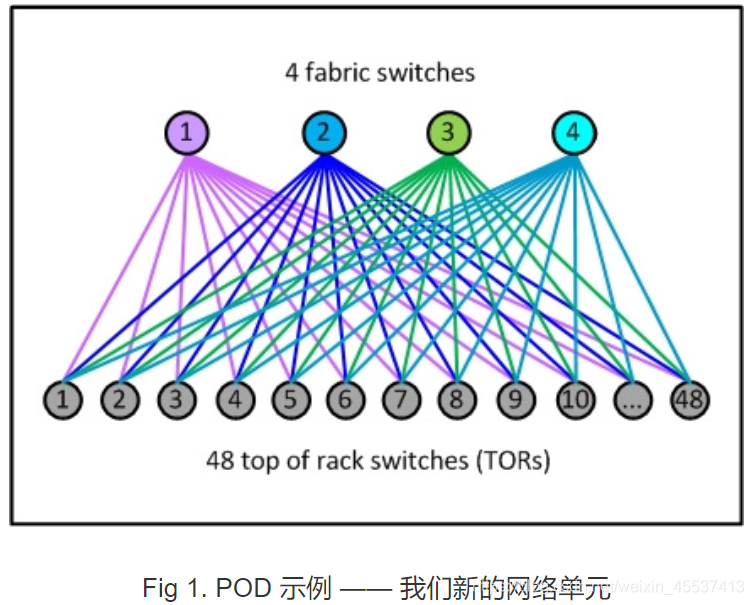
- POD 其实没有非常特别的地方 —— 它就像一个三层的微集群(layer3 micro-cluster);
- POD 并不是由任何硬件特性规定的;它只是我们的一个标准“网络单元”(unit of network);
- 每个 POD 有 4 个我们称之为 fabric 交换机的设备,有需要还可以扩展;
- 每个 TOR 当前有
4x40G 上行链路,为 10G 接入的服务器机柜提供 160G 的总上 行带宽;(现在采用的是25/100G组网)
相比之前clos传统网络架构的pod,这种小pod区别在于:
- 一个网络单元的规模很小,可以适应于不同机房模块的规模大小;
- 能匹配各数据中心的多种室内规划, 并且只需基本的中型交换机来汇聚 TOR;
- fabric 交换机更小的端口密度使得它们的内部架构非常简单、模块化和健壮(主要是表现单台设备的故障相比高密度的框式设备影响更小), 并且这种设备能够很容易从多家厂商采购;
- pod在设计上就定为无阻塞网络,pod的fabric交换机上下行收敛比1:1;
2.2 网络架构分析
为实现 building 范围的连接(building-wide connectivity),采用如下方式;
- 创建了 4 个独立的 spine 交换机平面(“planes” of spine switches),每个平 面最多支持 48 台独立设备。
- 每个 POD 内的每台 fabric 交换机,会连接到其所在 spine 平面内的每台 spine 交换机。
- POD 和 spine 平面提供了一个模块化的网络拓扑,能够提供几十万台 10G 接入交换机, 以及 PB 级跨 POD 带宽(bisection bandwidth),使得数据中心 building 实现 了无超售的机柜到机柜性能(non-oversubscribed rack-to-rack performance)。
网络架构如下所示:
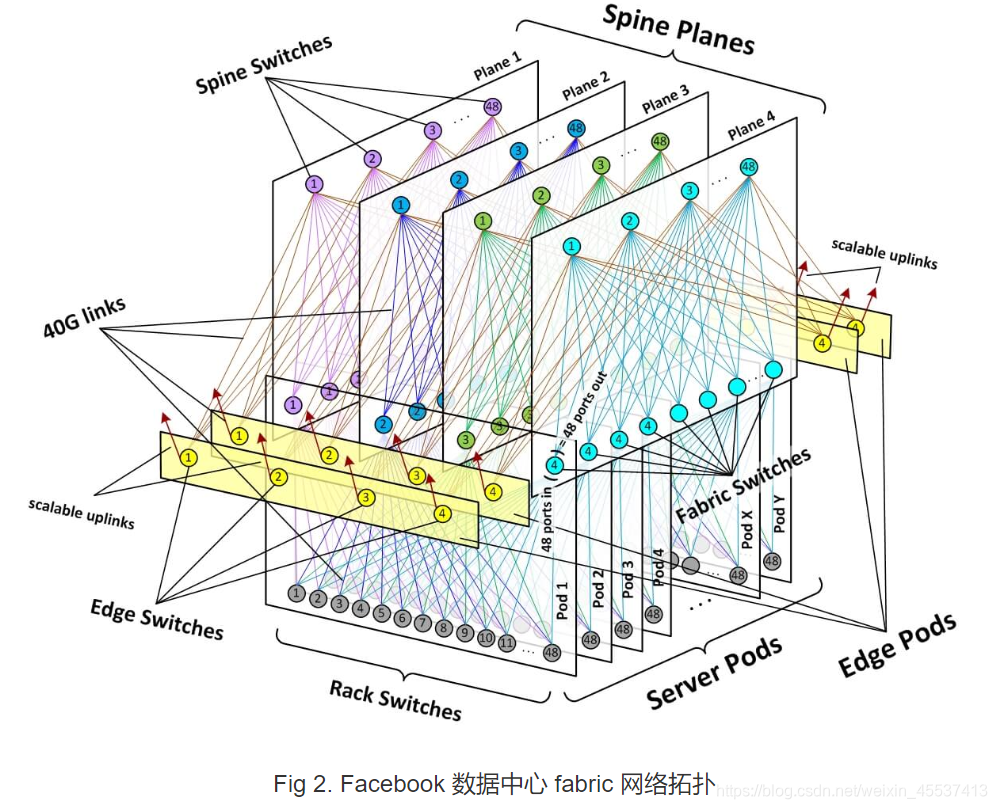
按照这种多平面进行划分的思路,构建如下架构:

按途中架构进行规划设计:
- s1交换机每个小pod由4台交换机组成,上下行收敛比为1:1。每个小pod下所能容纳的TOR数取决于s1的设备选型。若是用96口100G,一个小pod有48台TOR(不考虑堆叠/去堆叠:2304台服务器容量。假设每个机柜放置13台服务器,单pod下机柜数目177个左右);若是用128口100G,一个小pod下有64台TOR(不考虑去堆叠/堆叠,3072台服务器容量。假设每个机柜放置13台服务器,单pod下机柜数目256个左右);
- TOR交换机层面,收敛比为1200:400=3:1;
- s2交换机对应4个平面,每个平面的交换机数量最多可以到48台。采用128口100G交换机,上行接S3每台设备都是3条100G链路,则S2与S3间的带宽能达到19.2T(按一个one-building pod两万多台server的规模,最多能达到32T,也就是说该带宽是给该大POD到其他IDC、其他大POD的流量带宽)。下行最多可容纳9个server pod,每个pod能容纳2304台服务器,总共服务器容量为20736台server;
- s3交换机一般采用大框子的设备(12516/12816),其实在F4标准讲解中一般用中型号的交换机既可以满足,主要用来做One-building pod之间的互联互通(型号越高,横向扩展能力越强,若是采用大框子起码可以容纳30~50万台左右服务器;若是采用128口100G的盒式设备,4台组edge-pod则可以容纳20万台服务器左右,8组edge-pod可以容纳40万台);
- DCI设备主要是城域网的设备,在F4讲解的架构中S3是edge pod(边缘节点),但如果要dci互通,个人理解最好再加一层DCI交换机作为DCN的最外层边界,用来进行城域网间的互联;
2.3 网络建设落地
对于如此庞大的网络架构,在网络设备位置的摆放与布线方面,也需要进行设计,尽可能保持设备间线的利用率最高。减小线缆长度,便于快速部署,以下是f4架构中设备的位置关系摆放。从顶向下看,edge-pod位于各spine平面的垂直上层,与各个building互联,各spine平面位于机房中心,两边是各pod的fabric交换机,再往外是TOR。层次化分明,通过这种方式来达到线路的最高效利用。
