创建图模型
图模型由若干节点类型(vertex type)和若干边类型(edge type)组成。可以指定边类型的源节点类型(source vertex type)和目标节点类型(target vertex type)。图模型是对现实世界的问题的一种直观的抽象。
我们很容易建立电影推荐问题的模型,模型中有两种节点类型:人(person)和电影(movie),以及一种边类型:打分(rate)。rate的源节点类型为person,目标节点类型为movie。
我们使用GUI集成开发工具GraphStudio创建图模型。打开浏览器,在地址栏输入安装TigerGraph机器的IP+14240端口访问GraphStudio,载入完成后点击左侧导航栏的Design Schema项进入创建图模型页面:
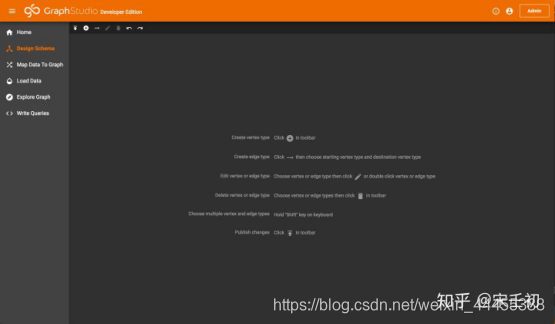
单击下图中黄色箭头所指的工具栏中的按钮即可添加节点类型,在弹出的窗口中设置节点类型名称、主键(primary id)名称和类型、属性(attribute)名称和类型,并根据语义选择节点类型的颜色和图标。我们首先添加person节点类型:
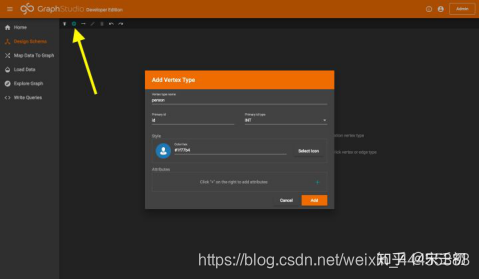
然后添加movie节点类型:

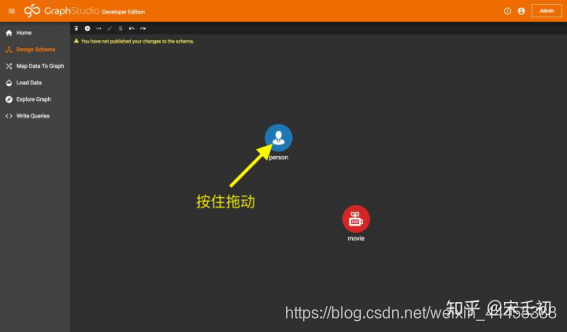
添加完毕后可以通过鼠标拖动调整节点类型的位置:
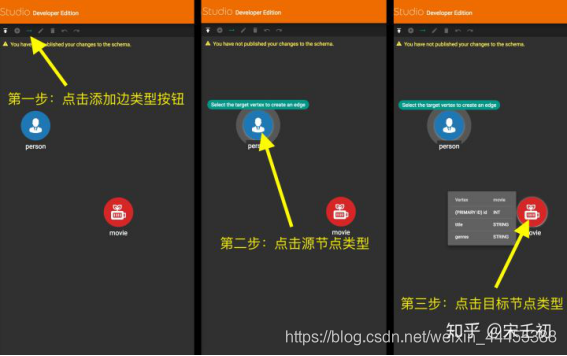
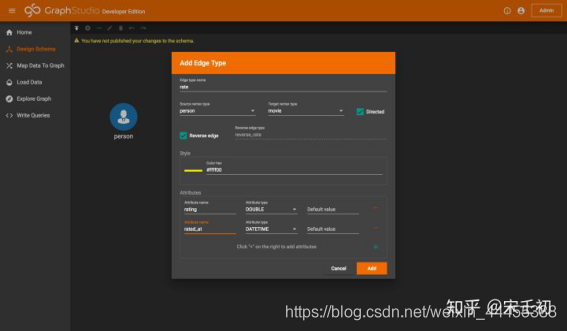
单击下图第一步中黄色箭头所指的工具栏中的按钮进入添加边类型模式,然后如第二步点击源节点类型,然后如第三步点击目标节点类型。
在弹出的窗口中设置边类型名称、边类型的有向性(directed)、属性(attribute)名称和类型,并可以选择边类型的颜色。我们输入rate边类型的信息:
至此,我们完成了图模型的创建。可以用鼠标滚轮缩放图模型,也可以用鼠标按住工作面板的空白处拖动整个图模型。点击工具栏中的发布按钮将图模型发布到TigerGraph系统中。整个发布大概需要2分钟。

创建数据映射
数据映射(data mapping)指建立数据模型之间的元素的对应关系。在电影推荐的这个实例中,我们需要建立从csv文件代表的数据模型到图模型之间的对应关系。
这里需要弄清楚模型和元素之间的关系,这种关系类似于面向对象程序设计中类(class)与实例(instance)之间的关系。我们刚刚创建的图模型描述了这些类之间的关系,而我们接下来要向图中载入的数据(元素)则是具体的每一个人、每一部电影和每条某人对某电影的打分。
在由movies.csv文件和ratings.csv文件组成的模型中,文件表头的语义代表了该模型的结构。movies.csv文件除表头以外的每行数据代表了一个电影元素,我们需要将它映射到图模型中的电影元素。ratings.csv文件除表头以外的每行数据包含了一个(可能重复出现的)人元素和一个打分元素,我们需要将它映射到图模型的人元素和打分元素。
点击左侧导航栏的Map Data To Graph项进入创建数据映射页面:
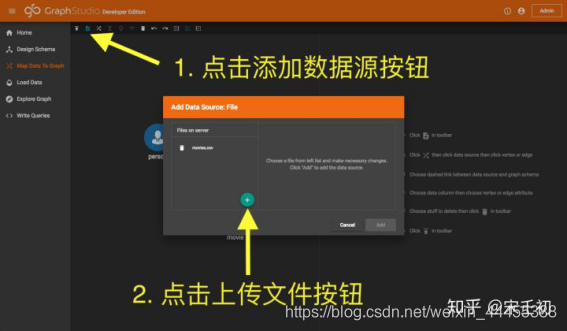
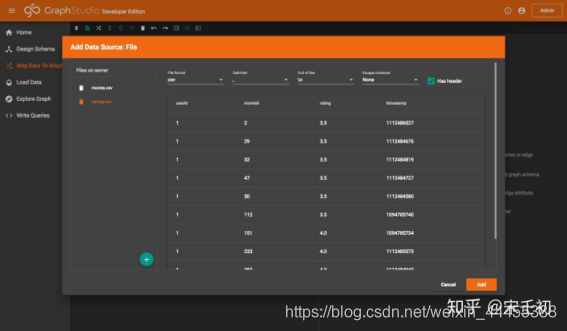
我们需要将数据文件上传到TigerGraph后台。这里有两种方式:对于小于500MB的文件,可以直接通过GUI上传。点击下图中黄色箭头1所指的工具栏添加数据源按钮,在弹出的窗口中点击黄色箭头2所指的上传文件按钮,选择本机解压缩后的ml-20m数据集中的movies.csv文件上传。上传完成后在文件列表中会显示该文件:
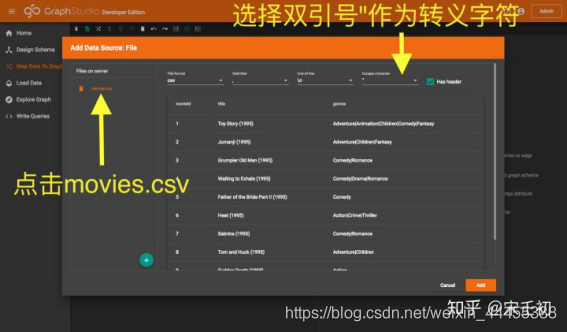
然后我们将该数据源添加到工作面板上。在Files on server列表中点击movies.csv文件,GraphStudio后台用算法智能分析数据并推断出文件的分隔符(delimiter)、换行符(end of line)和是否有表头(has header)。GraphStudio的这个推断是尽力而为的,如果不准确,用户可以自由修改这些设置,文件会马上被重新分行分列。需要注意的是GraphStudio不对转义字符(escape character)做推断。回顾前文我们提到movies.csv对于title列数据有逗号的情况采用双引号转义,所以我们需要在转义字符下拉列表中选择双引号("):
点击添加之后,movies.csv作为一个数据源被添加到工作面板上,表示为一个文件图标。用户可以按住这个图标拖动到任何想要的位置:
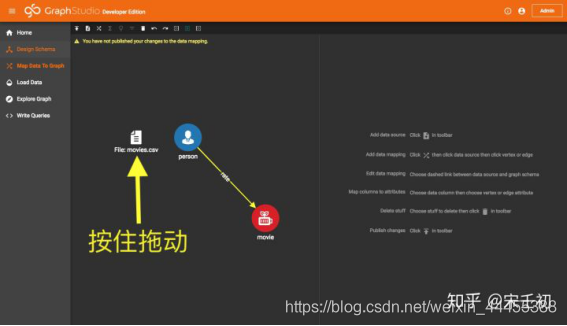
下面我们添加ratings.csv文件。出于保护系统资源的考虑,GraphStudio限制通过GUI上传单个文件不能超过500MB,而ratings.csv刚好超过了这个限制,因此我们通过scp命令(或者任意其他方式)直接将该文件传到虚拟机的
/home/tigergraph/tigergraph/loadingData/
文件夹内(如果你在安装TigerGraph过程中没有使用默认的用户名或安装路径,则请将文件上传到相应的路径)。
再次点击工具栏添加数据源按钮,在弹出的窗口中选择ratings.csv文件添加到工作面板:
好了,我们已经添加了所需的数据源,接下来创建数据源到图模型之间的数据映射。
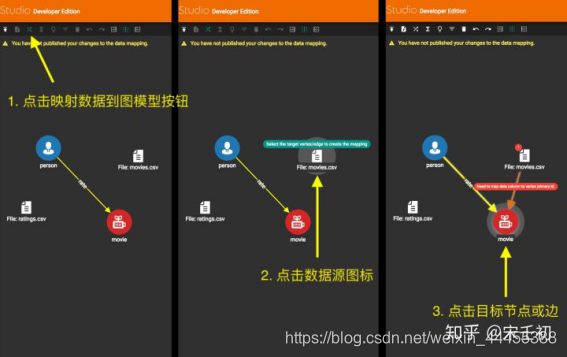
首先我们将movies.csv映射到movie节点类型。点击工具栏中的映射数据到图模型按钮,然后点击数据源(movies.csv)图标,然后点击目标节点类型(movie)。这时候一条数据映射关系就被创建了:
接下来,我们需要填充映射关系的内容,即数据源中的数据如何映射到目标节点(或边)的属性。在右侧工作面板中,表示数据源movies.csv的表和表示movie节点类型的表已经静静地等在那里了。建立映射的方式非常直观,先点击数据源表中的某一行(对应于csv文件中的某一列,这种旋转90度的表达方式是ETL中普遍采用的可视化方式),再点击节点类型属性表中的某一行(对应节点的主键或某个属性),就完成了一个属性映射。这里我们建立了三条属性映射,你可能注意到原来显示在左侧工作面板该数据映射上面的错误信息消失了,这是因为你创建了对于movie节点类型的主键的映射。对于节点来说,主键映射是必须的。而属性可以不被映射,在这种情况下当数据加载时这些未被映射的属性会使用默认值。

最后,我们建立ratings.csv到rate边类型的数据映射。重复与上面类似的操作,最终的映射结果为:
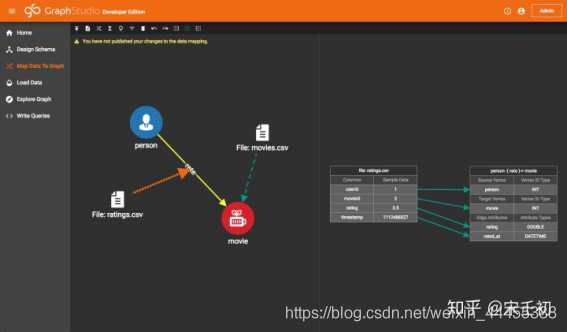
至此,我们完成了数据映射的创建。需要注意的是我们并没有映射从ratings.csv到person节点类型的映射,这是因为在ratings.csv映射到rate边类型的时候我们建立了userId列到rate边的源节点类型person的属性映射,这会在后续的数据加载中自动创建以ratings.csv中该列数据值为主键的person类型的节点。在TigerGraph系统中所有加载到相同类型的具有相同主键的节点会被合并为一个节点,默认的合并规则为属性覆盖。
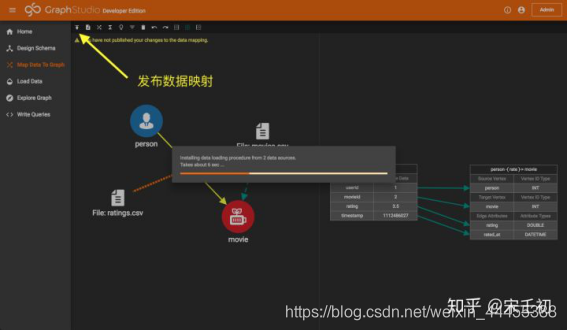
最后,点击左上角的发布按钮将数据映射发布到TigerGraph系统。发布所需时间和数据映射的个数相关,这里大概需要6秒:
载入数据
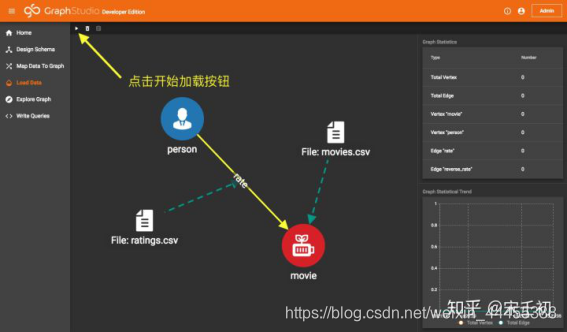
接下来我们让TigerGraph系统根据我们创建的数据映射加载数据。点击左侧导航栏的Load Data项进入加载数据页面,点击工具栏中的开始加载按钮:
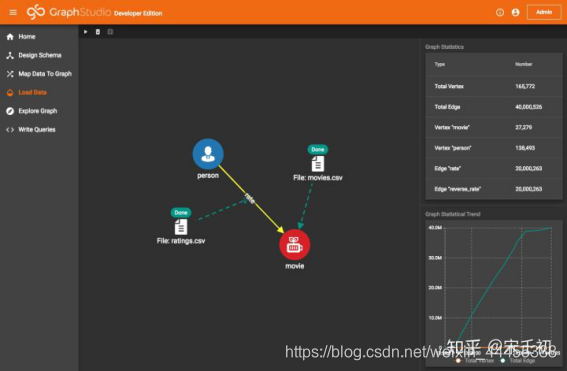
加载整个数据集耗时仅2分钟,这仅仅是在个人苹果笔记本的虚拟机上就能达到的加载速度!加载完毕后我们通过右侧的统计信息看到总共加载了16.5万个节点和4000万条边。之前我们说总共有2000万条打分记录,而每条记录在TigerGraph图数据库中被加载到一条rate边和一条reverse_rate反向边,因此总共有4000万条边。
浏览图数据
下面我们利用GraphStudio内置的一些图数据浏览功能直观的感受一下刚刚加载的数据。点击左侧导航栏的Explore Graph项进入浏览图数据页面:
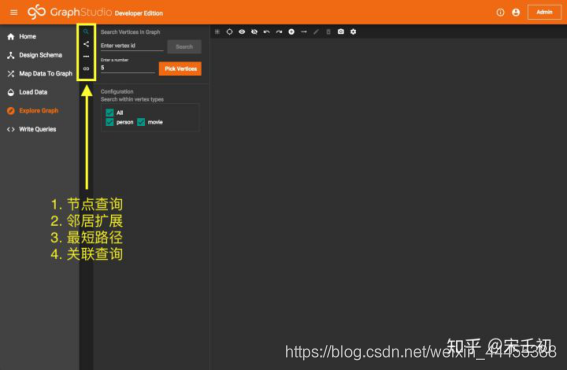
首先我们点击拾取节点(Pick Vertices)按钮从图数据中拾取5个person节点和5个movie节点。这里的拾取不是随机的,因此每次拾取会返回相同的结果。如果你想要更多的节点,可以修改Enter a number中的数字。这里最大可以输入500。如果你知道节点的主键,可以在Enter vertex id输入框中输入主键的值,然后点击旁边的Search按钮拾取那个节点。配置(Configuration)可以控制拾取节点的类型范围,默认是从全部类型中拾取。你也可以勾选取消一些类型。
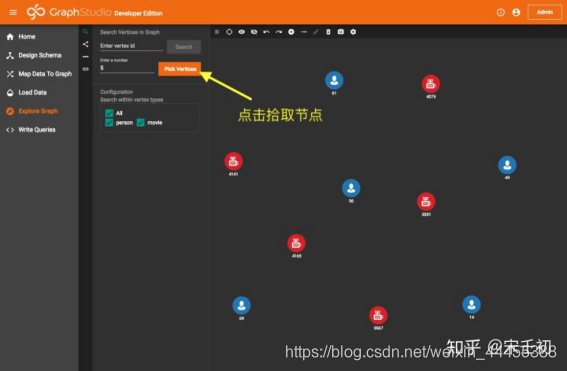
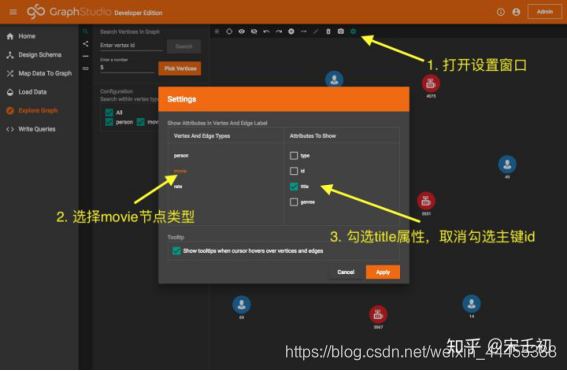
默认情况下所有节点显示的标签都是它们的主键。你可以修改设置显示其他属性,我们设置movie类型的节点显示它们的title属性:
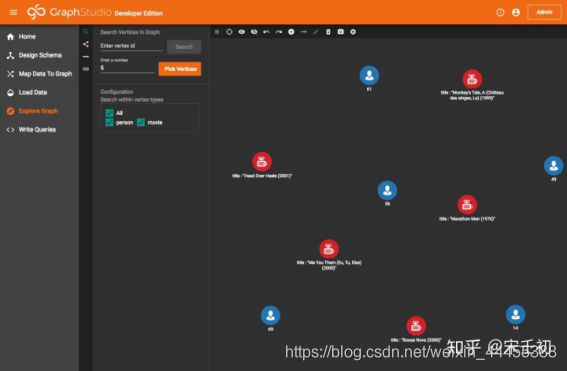
完成修改之后,可以看到工作面板中的movie节点的标题被显示出来了,可视化变得更加直观。
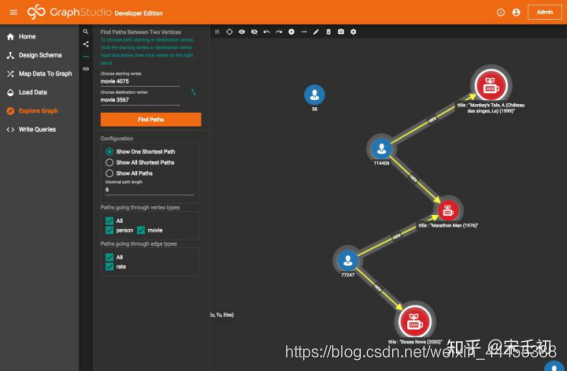
切换到黑色的纵向导航栏第三个最短路径项。点击选择起始节点(Choose starting vertex)输入框,再随意点击工作面板中的一个节点。再点击选择目标节点(Choose destination vertex)输入框,再随意选择工作面板中的另一个节点。
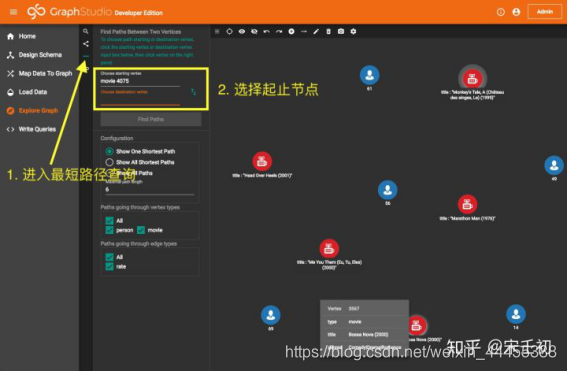
点击查找路径(Find Paths)按钮,TigerGraph瞬间找到了两点之间的一条最短路径,长度为4。请尝试修改设置将打分显示在rate边的标签上~
你可以继续尝试浏览图数据页面的其他功能。相信你会通过一些操作发现这是一个非常密集的图(点与点之间有极多的连接路径)。