一. 目标检测SSD(单发多框检测)
1. 介绍
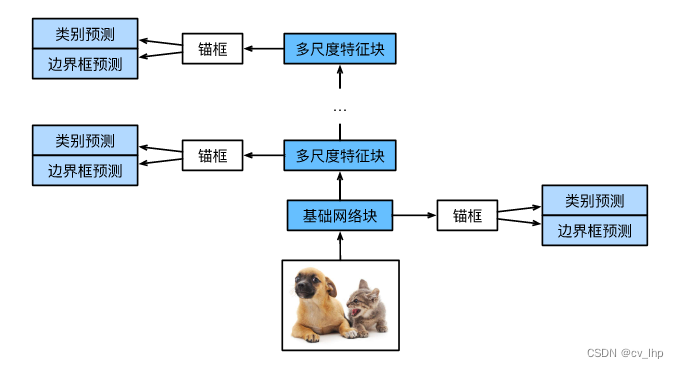
SSD模型主要由基础网络组成,其后是几个多尺度特征块。 基本网络用于从输入图像中提取特征,因此它可以使用深度卷积神经网络。 单发多框检测论文中选用了在分类层之前截断的VGG,现在也常用ResNet替代。 我们可以设计基础网络,使它输出的高和宽较大,从而基于该特征图生成的锚框数量较多,可以用来检测尺寸较小的目标,接下来的每个多尺度特征块将上一层提供的特征图的高和宽缩小(如减半),并使特征图中每个单元在输入图像上的感受野变得更广阔。由于接近顶部(输出层)的多尺度特征图较小,但具有较大的感受野,它们适合检测较少但较大的物体。 简而言之,通过多尺度特征块,单发多框检测生成不同大小的锚框,并通过预测边界框的类别和偏移量来检测大小不同的目标,因此这是一个多尺度目标检测模型,如下图所示。
2. 类别预测层
设目标类别的数量为
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)