前置准备
需要启动 Hadoop 集群,因为我们 Hive 是在 Hadoop 集群之上运行的。
从DataGrip 或者其他外部终端连接 Hive 需要先打开 Hive 的 metastore 进程和 hiveserver2 进程。metastore 和 hiveserver2 进程的启动过程比较慢,不要着急。
Hive DDL 数据定义语言
1、数据库(database)
创建数据库
create database [if not exists] 数据库名
[comment 注释:给开发人员看的]
[location 数据库保存路径]
[with dbproperties (配置名1=配置值1,配置名2=配置值2,)]
案例
-- 创建数据库 默认保存为 hdfs:///user/hive/warehouse.数据库名.db
create database db_hive;
-- 创建数据库并指定保存路径为 hdfs下的/db_hive2
create database db_hive2 location '/db_hive2';
-- 创建数据库名并指定数据库属性信息
create database db_hive3 with dbproperties ('create_date'='2023-9-15')
运行结果
默认保存路径:
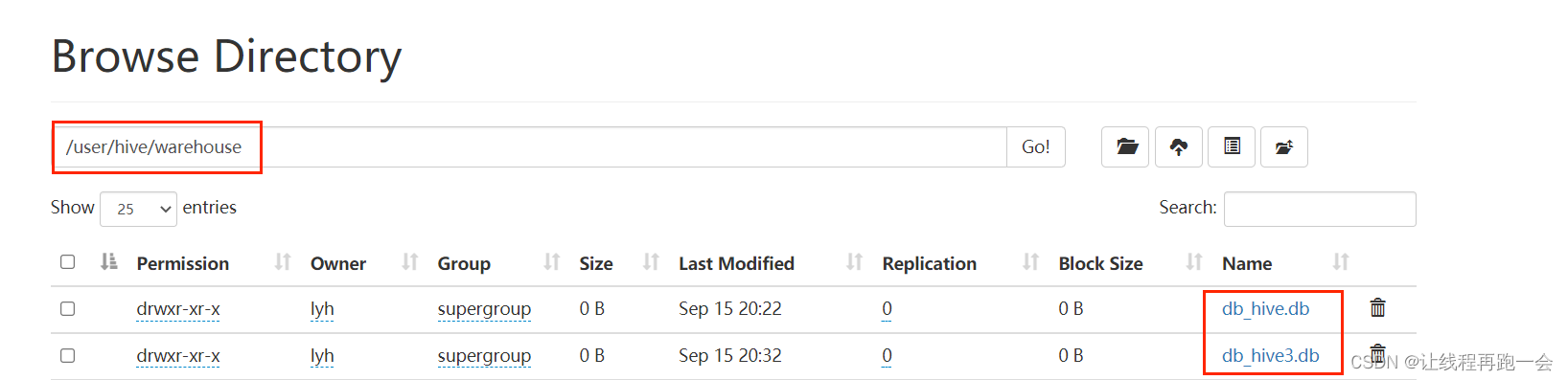
指定保存路径:
查询数据库
show databases [like 正则表达式]
案例
-- 查看所有以 db_hive 开头的数据
show databases like 'db_hive*';
运行结果
hive (default)> show databases like 'db_hive*';
OK
database_name
db_hive
db_hive2
db_hive3
Time taken: 0.071 seconds, Fetched: 3 row(s)
查看数据库详细信息
案例
-- 查看数据库信息(详细信息)
describe database extended db_hive3;
运行结果
hive (default)> describe database extended db_hive3;
OK
db_name comment location owner_name owner_type parameters
db_hive3 hdfs://hadoop102:8020/user/hive/warehouse/db_hive3.db lyh USER {create_date=2023-9-15}
Time taken: 0.043 seconds, Fetched: 1 row(s
这里可以看到我们创建数据库时设置的 with dbproperties 属性。
修改数据库
语法
-- 修改db properties
alter database db_hive set dbproperties ('create_time'='2023-9-15');
-- 修改 location 不会移动当前数据库下表的位置,影响的是后续创建的表的父目录
alter database db_hive2 set location 'hdfs:///hello/'; //一定要带前缀 hdfs://
use db_hive2;
create table student(name string); //新创建的表被存储在 /hello下
注意:再修改数据库的存储位置后,从该数据库的下一张表的存储路径才会开始生效,而且 set location 的值必须有前缀 "hdfs://"代表是存储在 HDFS文件系统下。
删除数据库
默认为 restrict 模式,即要求数据库必须为空,可以在删除语句后指定级别。
非空数据库需要删除所有表后再删除或者指定为 cascade 模式。
删除空数据库
-- 删除空数据库
drop database db_hive;
删除非空数据库
-- 删除非空数据库
drop database db_hive3 cascade ;
2、表(table)
创建表
1)普通建表
语法:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] 表名
[(字段名 字段类型 [COMMENT 字段注释], ...)]
[COMMENT 表注释]
[PARTITIONED BY (列名 数据类型 [COMMENT col_comment], ...)]
[CLUSTERED BY (列名, 列名, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT 指定的SERDE,Hive使用SERDE序列化和反序列化每行数据]
[STORED AS 读取文件的格式INPUTFORMAT,OUTPUTFORAMT]
[LOCATION 存储在HDFS的路径,默认是hdfs:///user/hive/warehouse/表名]
[TBLPROPERTIES (属性名=属性值, ...)]
关键字说明:
TEMPRORARY:
临时表,只在本次会话有效,客户端会话结束,表会自动删除。
EXTERNAL(重点):
外部表,与之相对的是内部表(管理表)。管理表意味着 Hive 会完全接管该表,包括元数据和 HDFS 中的数据。而外部表则意味着 Hive 只接管元数据,而不接管 HDFS 中的数据。
也就是说,删除数据的时候,如果删除的是内部表,那么元数据和HDFS中的数据都会被删除,如果是外部表,那么只有元数据会被删除,HDFS中的数据仍然保留。
查看当前表是管理表还是外部表:
-- 查看表 stu 是内部表还是外部表
desc formatted stu;
-- 内部表: MANAGED_TABLE,外部表: EXTERNAL_TABLE
ROW FORMAT(重点):

指定 SerDe,SerDe 是 Serializer and Deserializer 的简写。Hive 使用 SERDE 序列化和反序列化每行数据。
查看完整建表语句:
-- 查看表 stu 的 完整建表语句
show create table stu;
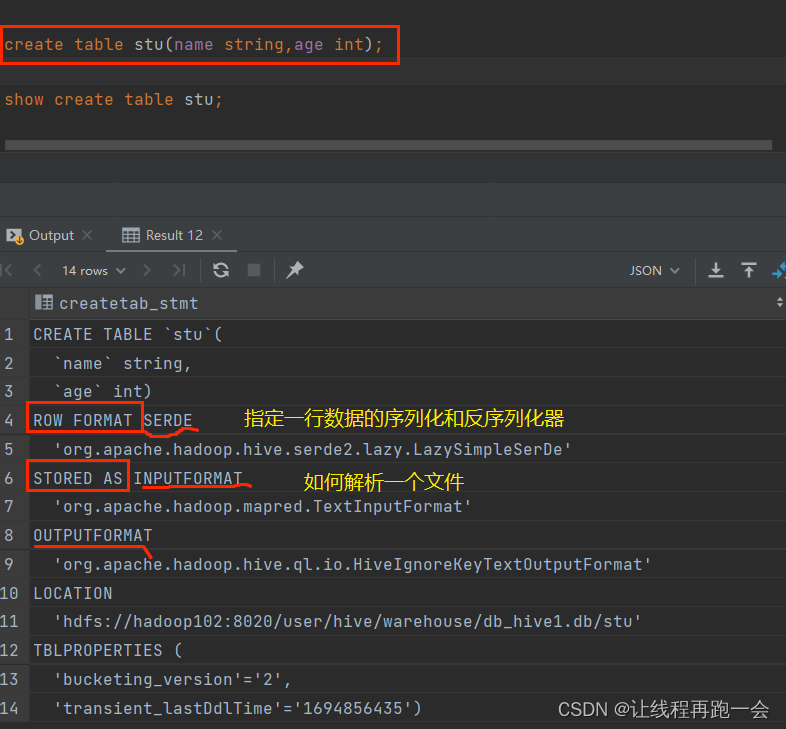
默认语法:
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
ROW FORMAT 和 STORED AS 这两个关键字在建表语句中非常重要,显然如果我们建一张表就写这么长的语句太麻烦了,所以 Hive 帮我们简化了以下语法:
语法1:DELIMITED 关键字
表示对文件中的每个字段按照特定分割符进行分割,会使用默认的 SERDE 对每行数据进行序列化和反序列化。
ROW FORMAT DELIMITED
-- 列分割符
[FIELDS TERMINATED BY char]
-- map、struct 和 array 之间的分隔符
[COLLECTION ITEMS TERMINATED BY char]
-- map 中 key 和 value 的分隔符,至于struct结构体,它在Delimited存储时,只会存储它的属性值,不会存储它的属性名
[MAP KEYS TERMINATED BY char]
-- 行分割符 默认 \n
[LINES TERMINATED BY char]
-- NULL 值的存储格式,默认值 \N
[NULL DEFINED AS char]
语法2 SERDE 关键字:
SERDE 关键字可以用于指定其他内置的 SERDE 或者 用户自定义的 SERDE。
例如 JSON SERDE,可用于处理 JSON 字符串。
ROW FORMAT SERDE SERDE名 [with serdeproperties
(属性名1=属性值1,属性名2=属性值2)]
STORED AS(重点):
指定存储文件类型
常用的存储文件类型:sequence file(二进制序列文件)、text file(文本)、rc file(列式存储格式文件)
如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE(我们在学习 Hadoop 的时候讲过,合并多个小文件就是合并成一个 sequence文件)。
语法1:
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
直接跟上指定的 INPUTFORMAT 和 OUTPUTFORMAT,这种太麻烦了,建议。
语法2:
直接在 SERDE AS 后面跟一个文件格式小写,比如 textfile(默认)、sequence file、orc file、parquet file。orc 和 parquet 都是列式存储文件。
-- 也就是默认的 'org.apache.hadoop.mapred.TextInputFormat'
SERDE AS textfile
PARTITIONED BY(重点)
创建分区表。将 Hive 中一张表的数据,按照指定的分区字段,分不到不同的路径。一个路径对应一个分区。
分区规则:指定的分区字段的值相同的放到一个分区。我们开发时通常按照日期分区。
CLUSTERED BY ... SORTED BY ... INTO ... BUCKETS(重点)
创建分桶表。会将 Hive 中一张表的数据分散存储到多个文件里面。
分散的规则:指定一个字段或者多个字段(clustered by),指定桶的个数(buckets),可以对每个桶里设置排序规则。分桶时,对字段进行 hashCode 取模运算,就像我们 Hadoop 分区的时候一样,根据计算结果放到对应第 0、1... 个桶中。
2)Create Table As Select (CTAS)建表
允许用户使用 select 语句返回的结果创建一张表,表的结构和查询结果一致。也就是说,这样创建的表自带数据(我们查询出来的数据)。
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] 表名
[COMMENT 表的描述]
[ROW FORMAT 指定的SERDE,Hive使用SERDE序列化和反序列化每行数据]
[STORED AS 读取文件的格式INPUTFORMAT,OUTPUTFORAMT]
[LOCATION 存储在HDFS的路径,默认是hdfs:///user/hive/warehouse/表名]
[TBLPROPERTIES (属性名=属性值, ...)]
[AS 查询语句]
注意:通过 CTAS 创建表的时候,不允许创建外部表(也就是EXTERNAL_TABLE),只允许是内部表(不需要设置,默认就是 MANAGED_TABLE)。
3)Create Table Like
允许用户复刻一张已经存在的表结构。也就是说,可以复制另一张表的结构,但是是一张新表,初始是没有数据的。
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS]
[数据库名.]表名
LIKE 已经存在的表名
[ROW FORMAT 指定的SERDE,Hive使用SERDE序列化和反序列化每行数据]
[STORED AS 读取文件的格式INPUTFORMAT,OUTPUTFORAMT]
[LOCATION 存储在HDFS的路径,默认是hdfs:///user/hive/warehouse/表名]
[TBLPROPERTIES (属性名=属性值, ...)]
这种表可以是外部表。
查看表
展示所有表
语法
show tables [in 数据库名] like [通配表达式]
案例
查看所有 tea 开头的表
show tables in db_hive1 like 'tea*';
查询结果:
teacher
teacher1
teacher2
查看表信息
语法
describe [extended | formatted] [数据库名.]表名
注:
extended:展示详细信息。
formatted:对详细信息进行格式化展示。
案例
查看表的基本信息
desc teacher;
查询结果:
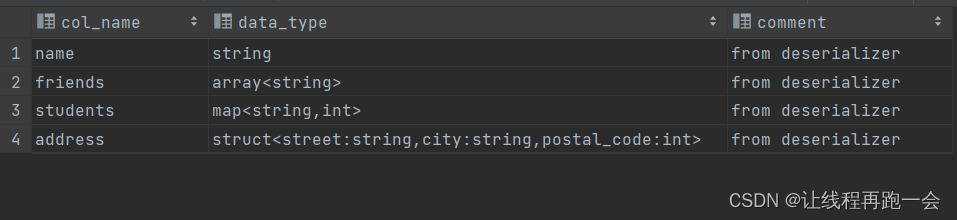
展示详细信息
我们通常只使用 extended 关键字是不够的,因为这样展示出来的详细内容会挤在一个单元格,不方便查看。所以我们一般直接使用 formatted 进行对详细信息进行格式化。
desc formatted teacher;
查询结果:
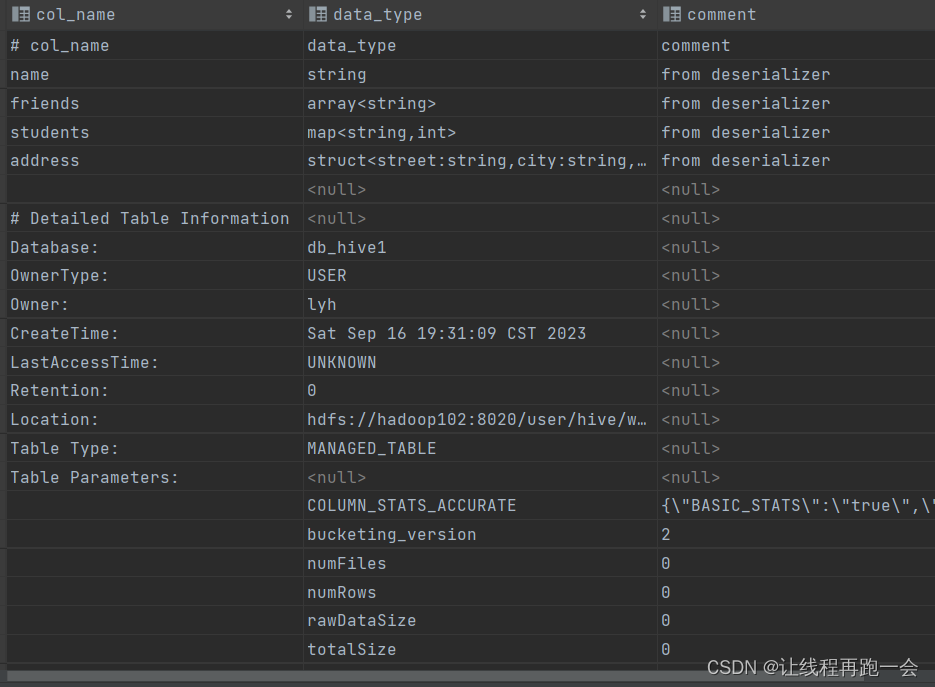

详细信息很多,包括表的基本信息以及存储信息(是否压缩、桶信息、输入输出格式等)。
修改表
重命名表
语法
alter table 表名 rename to 新表名;
案例
alter table teacher2 rename to tea;
修改列信息(常用)
修改列信息只会修改表的元数据信息,原本存在于表中的HDFS文件仍然需要我们自己区调整。
比如我们原本的字段顺序为 name:string、age:int、sex:string,然后我们调整了字段的顺序为:age、name、sex,那么必然我们HDFS文件中的数据也应该做调整,不然 name 字段被读取为 int 类型会报错。
增加列
默认加到表末。
alter table 表名 add columns (列名 列类型[comment 列注释], ...);
修改列
允许用户修改指定列的列名、数据类型、注释信息以及在表中的位置。
alter table 表名 change [column] 旧列名 新列名 列的类型 [comment 列的注释] [first|after 列名];
first:放到第一个字段。
after 列名: 放到某个字段后面。
替换列
允许用户用新的列集替换表原有的全部列,相当于融合了增加列和修改列。
alter table 表名 replace columns (列名 列类型[comment 列注释], ...);
案例
-- 新增一列 age
alter table teacher1 add columns (age int);
-- 设置不阻止不兼容的类型转换
set hive.metastore.disallow.incompatible.col.type.changes=false;
-- 把 age 字段放到 name 字段后面
alter table teacher1 change age age string after name;
-- 修改回原来的表
alter table teacher1 replace columns (
name string,friends array<string>,students map<string,int>,address struct<street:string,city:string,postal_code:int>);
注意:我们修改的只是表的元数据信息,而HDFS文件并无法修改,如果因为修改后字段类型顺序导致文件读取失败,就需要我们重新修改表结构或者修改调整HDFS文件内容(修改HDFS文件后需要重新上传)。
删除表
drop table [if exists] 表名;
需要注意的是,如果我们删除的是外部表,那么只会删除元数据,表解析的HDFS文件并不会被删除。
清空表
truncate [table] 表名;
注意:truncate 只能清空内部表,不能清空外部表中的数据。
案例
(一)内部表和外部表
1)内部表
默认创建的表都是所谓的管理表(内部表)。因为这种表 Hive 会(或多或少地)控制着数据的生命周期。Hive默认情况下会将这些表的数据存储在由配置项 hive.metastore.warehouse.dir(例如,/user/hive/warehouse) 所定义的目录的子目录下。
当我们删除一个管理表(内部表)时,Hive也会删除这个表中数据。管理表不适合和其他工具共享数据。
创建内部表
create table if not exists student(
id int,
name string
)
row format delimited
fields terminated by '\t'
location 'hdfs:///user/hive/warehouse/student';
数据准备
保存至 /opt/module/hive-3.1.2/test_datas/students.txt
1001 ss1
1002 ss2
1003 ss3
1004 ss4
1005 ss5
1006 ss6
1007 ss7
1008 ss8
1009 ss9
1010 ss10
1011 ss11
1012 ss12
1013 ss13
1014 ss14
1015 ss15
1016 ss16
上传文件到 HDFS 下Hive下student表的目录
上传到该表的Hive目录下后,Hive会自动将它解析成表:
hadoop fs -put student.txt /user/hive/warehouse/student
删除内部表
drop table student;
发现内部表和HDFS中的数据一同被删除。
2)外部表
修改上面的建表代码:
create external table if not exists student(
id int,
name string
)
row format delimited
fields terminated by '\t'
location 'hdfs:///user/hive/warehouse/student';
执行和上面相同的操作,最后删除:
发现表删除后,数据仍然存在于HDFS中。
(二)SERDE 和复杂数据类型
对 JSON 文件通过 Hive 进行分析处理。
数据来源
下面的内容其实是一个完整的JSON字符串,在 Hive 读取后其实只有一行。
{
"name": "lyh",
"friends": [
"my",
"zht"
],
"students": {
"drj": 48,
"lyf": 30
},
"address": {
"street": "chang an jie",
"city": "beijing",
"postal_code": 10010
}
}
设计表
我们考虑使用 JSON Serde,设计表的字段时,表的字段与 JSON 字符串的一级字段保持一致,对具有嵌套结构的 JSON 字符串,考虑使用复杂类型保存其内容。
我们可以发现,上面的JSON字符串中共有四个一级字段,其中 name 字段保存的是字符串,friends 字段保存的是一个数组,students 字段保存的是一个JSON对象,address 字段保存的也是一个JSON对象。
我们设计表的时候,其实考虑的就是字段、row format 、 store as 这些关键字。这里虽然是 JSON 文件但我们读取还是按照默认文本文件的读取方式来读取(TextInputFormat)。
create table teacher (
name string,
friends array<string>,
students map<string,int>,
address struct<street:string,city:string,postal_code:int>
)
row format serde 'org.apache.hadoop.hive.serde2.JsonSerDe';
-- 默认保存在 /user/hive/warehouse/db_hive1.db/teacher
-- json 文件直接用默认的读取方式即可 不需要设置 stored as 关键字
注意:json sered不能解析格式化的json文件,需要保障每一行json字符串数据处于一行中。row format也是每次序列化一行数据。
上传数据到HDFS时,需要将我们的JSON文件放到一行:
{"name": "lyh", "friends": ["my","zht"],"students": {"drj": 48,"lyf": 30},"address": {"street": "chang an jie","city": "beijing","postal_code": 10010}}
查询
select * from teacher;
select friends from teacher;
select friends[0] from teacher;
select students from teacher;
select students['drj'] from teacher;
select address.postal_id from teacher;
(三)create table as select 和 create table like
1)create table as select
在上面 teacher 表的基础上进行测试。
create table teacher1 as select * from teacher;
select * from teacher1;
测试结果:
创建的 teacher 表中的数据和 teacher 表一致。
2)create table like
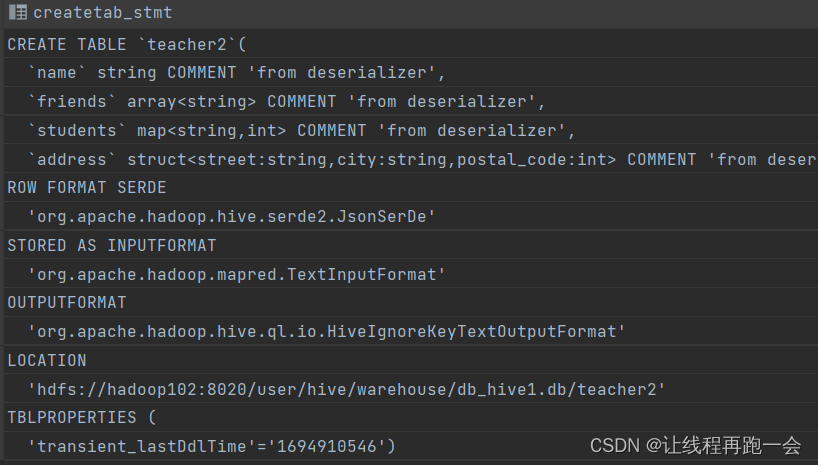
create table teacher2 like teacher;
select * from teacher2;
show create table teacher2;
测试结果:
创建的表是一个空表,但是结构和 teacher 表一致。
总结
耗时两个自习,跨度两天,终于把Hive DDL学完了,接下来就是上课看看笔记复习。