1,Hive是基于hadoop的数据仓库解决方案,由facebook贡献给Apache。Hive出现的初衷是让不熟悉编程的数据分析人员也能够使用hadoop处理大数据,这是怎么实现的呢?
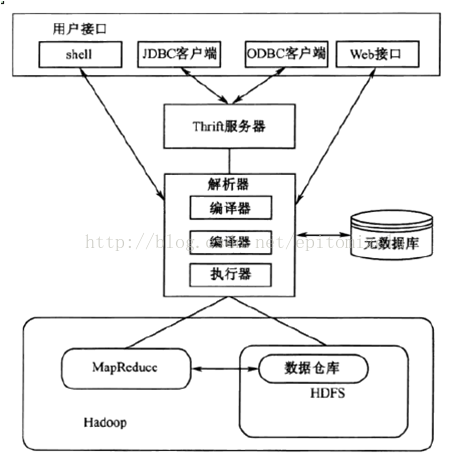
2,我们先来看看Hive提供的接口,从下面Hive的架构图中可以很明显的看出来,Hive 提供了Hive shell,JDBC/ODBC,Web接口来使用和管理Hive数据仓库。
- Hive的shell接口可以通过客户端接受shell命令,而Hive 提供了类似于 sql的HiveQL语法,使得通过Hive可以用类似于操作关系数据库那样对Hive数据仓库进行操作,熟悉sql的数据分析人员可以很容易的学会操作Hive利用hadoop进行大数据分析。
- Web接口可以让我们像管理hadoop一样通过浏览器监控、管理hive数据仓库。
3,Hive的安装分为三种:内嵌模式、单机模式、远程模式
![*]() 内嵌模式:元数据保持在内嵌的Derby模式,只允许一个会话连接
内嵌模式:元数据保持在内嵌的Derby模式,只允许一个会话连接
![*]() 本地独立模式:在本地安装Mysql,把元数据放到Mysql内
本地独立模式:在本地安装Mysql,把元数据放到Mysql内
![*]() 远程模式:元数据放置在远程的Mysql数据库
远程模式:元数据放置在远程的Mysql数据库
4,Hive内嵌模式的安装:内嵌安装,Hive的元数据存储在derby数据库中,derby数据只允许单用户连接,所以只适用于实验环境。
4.2 我的试验环境是在win7系统下安装virtualbox,linux系统是centos。所以我是在windows中下载Hive的安装压缩包,然后通过工具winscp将其传送到linux文件系统中。
4.3 解压Hive安装包并创建软连接。软连接可以不用创建,创建软连接的原因是hive-0.11.0 名称太长不方便书写,创建软连接相当于给hive-0.11.0起了一个更简单的别名。实际上我们也可以通过命令 mv 直接将文件夹名hive-0.11.0改为hive。
4.4修改配置文件,更改配置文件名称。
-
在hive安装目录下的conf文件夹中的hive-default.xml.template,hive-log4j.properties.template复制改名:
cp hive-default.xml.template hive-site.xml
- cp hive-log4j.properties.template hive-log4j.properties
这样hive的内嵌模式就安装好了,可以通过执行命令 Hive进行验证。
5,独立模式和远程模式的安装。
独立模式和远程模式下,元数据都存储在mysql数据库中,不同的是独立模式下mysql安装在本地,远程模式下mysql安装在远程计算机上。
因为独立模式和远程模式都不在使用内嵌的derby数据库存储元数据,而是使用mysql存储元数据,所以首先要装mysql数据库。
5.1本地安装mysql数据库。
下载mysql和mysql驱动之后,开始安装,要注意使用root用户来安装mysql数据库,否则会在使用的过程中遇到权限不足的问题。
第一步,解压mysql和mysql的java驱动。
第二步,使用命令rpm安装mysqlserver。(如下图,图片来自艾伦老师hadoop视频教程)
在安装过程中,系统会自动生成一个用户,用户名是当前系统用户名,如root,初始密码存放在/root/.mysql_secret文件夹中。如下图进行查看,每个用户的初识密码是不一样的。
第三步,安装mysql_client和mysql_devel.
执行命令启动mysql服务。
第四步,用之前安装mysqlserver时生成的用户名和密码登陆mysql,并修改密码。
第五步,授权任何ip地址的用户使用客户端登陆mysql。
第六步,创建一个新的用户,如hive,并给这个用户授权。
> create user 'hadoop'identified by '123456';
>grant all on *.* tohadoop@'%'with grant option;
第七步,用创建的用户hive登陆mysql,创建名为hive数据库用来存储hive数据仓库元数据。
mysql -uhadoop-p123456
mysql> create database hive;
5.2修改hive-site.xml配置文件,指定mysql连接字符串和用户名及密码。这里不修改的话就默认用derby作为元数据存储。
5.3,将之前下载解压的mysql的java驱动复制到{hivehome}/lib目录下

5.4 输入hive命令测试,hive独立安装是否成功。
总结:独立模式和内嵌模式区别和联系,独立模式是在内嵌模式的基础之上继续安装,独立模式要安装mysql数据库,要再hive-site.xml文件中指定元数据库为mysql,要将mysql的驱动包放置在hive安装目录下的lib目录中。
5.5远程模式的安装。
一是,远程模式首先要指定mysql的位置,在hive-site.xml文件中告诉hive怎么去连接mysql元数据库。
Ø修改hive-site.xml的javax.jdo.option.ConnectionURL参数,调整主机名为远程机的主机名
二是,hive-site.xml中配置metastore不采用本地存储的方式,而要采用远程的方式。
Ø配置hive.metastore.uris参数
<property>
<name>
hive.metastore.local
</name>
<value>
false
</value>
<description>controls whether to connect to remote metastore server or open a new metastore server in Hive Client JVM</description>
</property>
<property>
<name>
hive.metastore.uris
</name>
<value>
thrift://hadoop0:9083
</value>
<description></description>
</property>
对于远程安装,即把hive的元数据库安装在和hive不同的服务器上,所以和内嵌安装以及独立安装不同的是,我们需要单独启动远程的metastore服务,从而连接元数据库。
6,hive的远程启动。远程安装的启动步骤可以总结为:启动mysql服务(mysql service start),启动远程元数据服务(hive --service metastore),启动本地hive服务(hive --service hiveserver)。