写在前面:
个人对TPCH benchma的理解。我接到这个任务的时候,描述是这样的,“××呀,用benchMarke生成TPC-H然后测试一下"。我第一反应就是benchMark是什么,TPCH是什么。现在把这个弄完一遍后来说一下我的理解。
首先什么是TPC-H?
包括:八张定义好的表(也就是八个create语句)、表中的一条条的数据(比如”张三,1997-12-25,‘江苏’,98)、22条SQL语句。
TPC-H能干什么?
用来测试数据库管理系统的性能。浅显的举例子,比如现在有个项目要用数据库,备选的有MySQL、postgreSQL、张三公司开发的zsDB。指标就是要一个查询的快的数据库。这时候就可以用TPC-H的创建表的语句在三个数据库中创建同样的表,然后都导入TPC-H生成的1TB的记录数据,然后运行同样的TPC-H的22条SQL语句,在三个变量都相同的情况下,看最后哪个数据库跑完22条语句用的平均时间最短。根据结果选出一个来用。
我们用TPC-H需要干什么?怎么用?
不同的数据库的SQL语句语法上有差别,所以我们需要告诉TPC-H我们需要测试什么数据库,让他生成对应数据库的表创建语句,约束语句,SQL语句等。而且根据不同的情况需要生成不同大小的数据,比如1G,100G,1TB等等,就干这么个事
什么是benchMark
说实话,我现在也没理解。感觉是benchMark是一个集合。比如测试数据库除了 TPC-H 还有TPC-DS等等,还有测试cpu性能的什么的,所有的这些标准的大家都认可的测试集,称之为benchMark。(纯属个人理解,如果错误,欢迎批评指正,万分感谢)
参考文献在末尾
1.下载TPC-H的文件夹
TPC-H压缩包官网地址


注意:下载时需要填写邮箱,然后会发一个下载地址到邮箱里,邮箱地址只能下载一次,下一次下载需要再填一次邮箱,到新的地址下载。
如果是linux 可以用wget命令等下载,也可以在Windows下下载之后传输到Linux上,百度一下如何将文件传输到服务器上。或者用WinS C P可以很方便的传输文件
2.解压压缩包

(这个压缩包的名字很长,我自己改了下名字)
解压后如下

3.编译
①将makefile.suite 的复制到 makefile

②修改makefile文件


键盘输入 i 键入插入模式

完成后 按 Esc进入命令模式 输入 :wq 保存并退出
③修改dbgen目录下的tpcd.h文件
注意:如果DATABASE这里填的是红框里已有的数据库就不用进行这一步了,我用的是postgreSQL这里没有,所以需要进行这一步。向tpcd.h中添加下面的内容。
#ifdef POSTGRESQL
#define GEN_QUERY_PLAN "EXPLAIN"
#define START_TRAN "BEGIN TRANSACTION"
#define END_TRAN "COMMIT;"
#define SET_OUTPUT ""
#define SET_ROWCOUNT "LIMIT %d\n"
#define SET_DBASE ""
#endif
④编译 不管需不需要步骤③都需要编译 make
 编译完成后会在当前目录下生成dbgen
编译完成后会在当前目录下生成dbgen
4.产生数据 (数据就是数据库中一行一行的记录)
./dbgen -s 1 -f

-s 1 表示产生1GB的数据 -f 表示复制原来的数据
可以灵活修改这些参数 比如 ./dbgen -s 100生成100G的数据
将数据移到一个单独的目录
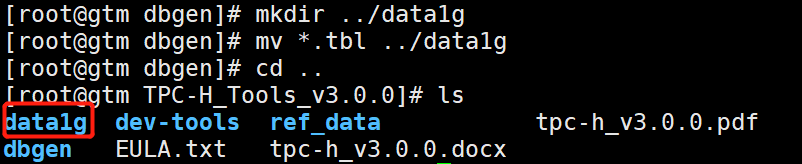
pwd Linux查看当前文件绝对路径的命令
向数据库中导入数据时要注意,需要把 .tbl文件中每一行后面的 | 这个竖线符号去掉,不然会报错。至于怎么去掉,我是自己写了python程序
import os
#去除文件夹data1g中的文件中每一列最后一行的 ‘|’
#讲去除后的内容写入文件夹 2data1g对应的文件中
for root in os.listdir('data1g'):
f = open('data1g' + '//' + root, 'r')
w = open('2data1g' + '//' + '1' + root, 'w')
for i in f:
length = len(i) - 2
if ('|' == i[length]):
j = i[:length] + "\n"
w.write(j)
f.close()
w.close()
处理完的数据在2data1g这个文件夹里面。
我是用WinSCP 先将服务器里的data1g文件拖拽到windows本地处理,处理完之后将2data1g的文件夹拖拽到服务器上原来data1g文件夹所在的位置
如果有权限问题,比如数据库在某个用户下,然后winSCP拖拽文件时是另一个用户登录的比如root用户,又可能在下面用命令运行数据库的时候产生错误,也可能在对文件进行操作时出现无法操作的问题。可以用chmod命令修改文件所属的用户(出现对应问题时上网查看命令的具体使用)
5.生成查询语句
到queries文件夹下
TPC-H_Tools_v3.0.0/dbgen/queries

queries文件夹原来长这样

需要将qgen 和 dists.dss复制到queries目录下
注意下方命令 cp 源文件路径 目的文件路径
所以下面第一条命令前一个qgen 和后一个 qgen之间有一个空格哦
dists.dss也是这样

生成查询语句,注意这里有22个所有只能生成22个
会写批处理的可以用批处理,我不会,所以我就一行行写写了22行
./qgen -d 1 > d1.sql
./qgen -d 2 > d2.sql
./qgen -d 3 > d3.sql
./qgen -d 4 > d4.sql
./qgen -d 5 > d5.sql
./qgen -d 6 > d6.sql
./qgen -d 7 > d7.sql
./qgen -d 8 > d8.sql
./qgen -d 9 > d9.sql
./qgen -d 10 > d10.sql
./qgen -d 11 > d11.sql
./qgen -d 12 > d12.sql
./qgen -d 13 > d13.sql
./qgen -d 14 > d14.sql
./qgen -d 15 > d15.sql
./qgen -d 16 > d16.sql
./qgen -d 17 > d17.sql
./qgen -d 18 > d18.sql
./qgen -d 19 > d19.sql
./qgen -d 20 > d20.sql
./qgen -d 21 > d21.sql
./qgen -d 22 > d22.sql

6.数据库操作
此处根据数据库不同命令也有差别
我用的是poatgres-XL
①连接数据库
②建立数据库
create databse tpch; //创建数据库tpch
drop database tpch; //删除数据库tpch
\l //(L的小写) 显示当前都有哪些数据库
\c tpch //进入数据库
③创建表
创建表的sql语句在TPC-H_Tools_v3.0.0/dbgen下的 dss.ddl
CREATE TABLE NATION ( N_NATIONKEY INTEGER NOT NULL,
N_NAME CHAR(25) NOT NULL,
N_REGIONKEY INTEGER NOT NULL,
N_COMMENT VARCHAR(152));
CREATE TABLE REGION ( R_REGIONKEY INTEGER NOT NULL,
R_NAME CHAR(25) NOT NULL,
R_COMMENT VARCHAR(152));
CREATE TABLE PART ( P_PARTKEY INTEGER NOT NULL,
P_NAME VARCHAR(55) NOT NULL,
P_MFGR CHAR(25) NOT NULL,
P_BRAND CHAR(10) NOT NULL,
P_TYPE VARCHAR(25) NOT NULL,
P_SIZE INTEGER NOT NULL,
P_CONTAINER CHAR(10) NOT NULL,
P_RETAILPRICE DECIMAL(15,2) NOT NULL,
P_COMMENT VARCHAR(23) NOT NULL );
CREATE TABLE SUPPLIER ( S_SUPPKEY INTEGER NOT NULL,
S_NAME CHAR(25) NOT NULL,
S_ADDRESS VARCHAR(40) NOT NULL,
S_NATIONKEY INTEGER NOT NULL,
S_PHONE CHAR(15) NOT NULL,
S_ACCTBAL DECIMAL(15,2) NOT NULL,
S_COMMENT VARCHAR(101) NOT NULL);
CREATE TABLE PARTSUPP ( PS_PARTKEY INTEGER NOT NULL,
PS_SUPPKEY INTEGER NOT NULL,
PS_AVAILQTY INTEGER NOT NULL,
PS_SUPPLYCOST DECIMAL(15,2) NOT NULL,
PS_COMMENT VARCHAR(199) NOT NULL );
CREATE TABLE CUSTOMER ( C_CUSTKEY INTEGER NOT NULL,
C_NAME VARCHAR(25) NOT NULL,
C_ADDRESS VARCHAR(40) NOT NULL,
C_NATIONKEY INTEGER NOT NULL,
C_PHONE CHAR(15) NOT NULL,
C_ACCTBAL DECIMAL(15,2) NOT NULL,
C_MKTSEGMENT CHAR(10) NOT NULL,
C_COMMENT VARCHAR(117) NOT NULL);
CREATE TABLE ORDERS ( O_ORDERKEY INTEGER NOT NULL,
O_CUSTKEY INTEGER NOT NULL,
O_ORDERSTATUS CHAR(1) NOT NULL,
O_TOTALPRICE DECIMAL(15,2) NOT NULL,
O_ORDERDATE DATE NOT NULL,
O_ORDERPRIORITY CHAR(15) NOT NULL,
O_CLERK CHAR(15) NOT NULL,
O_SHIPPRIORITY INTEGER NOT NULL,
O_COMMENT VARCHAR(79) NOT NULL);
CREATE TABLE LINEITEM ( L_ORDERKEY INTEGER NOT NULL,
L_PARTKEY INTEGER NOT NULL,
L_SUPPKEY INTEGER NOT NULL,
L_LINENUMBER INTEGER NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR(1) NOT NULL,
L_LINESTATUS CHAR(1) NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL);
④添加约束
约束(主键、外键)在dss.ri文件中
因为不知名原因外键添加不成功,所以我就直接删除了文件中外键的添加
⑤导入数据 注意路径
\copy customer from '/tpch/TPC-H_Tools_v3.0.0/2data1g/1customer.tbl' with delimiter as '|' NULL ' ';
\copy lineitem from '/tpch/TPC-H_Tools_v3.0.0/2data1g/1lineitem.tbl' with delimiter as '|' NULL ' ';
\copy nation from '/tpch/TPC-H_Tools_v3.0.0/2data1g/1nation.tbl' with delimiter as '|' NULL ' ';
\copy orders from '/tpch/TPC-H_Tools_v3.0.0/2data1g/1orders.tbl' with delimiter as '|' NULL ' ';
\copy part from '/tpch/TPC-H_Tools_v3.0.0/2data1g/1part.tbl' with delimiter as '|' NULL ' ';
\copy partsupp from '/tpch/TPC-H_Tools_v3.0.0/2data1g/1partsupp.tbl' with delimiter as '|' NULL ' ';
\copy region from '/tpch/TPC-H_Tools_v3.0.0/2data1g/1region.tbl' with delimiter as '|' NULL ' ';
\copy supplier from '/tpch/TPC-H_Tools_v3.0.0/2data1g/1supplier.tbl' with delimiter as '|' NULL ' ';
⑥运行sql语句
参考文献
https://blog.csdn.net/iteapoy/article/details/104214119
https://blog.csdn.net/m0_37852301/article/details/120886897
https://www.cnblogs.com/littlesuccess/p/3840594.html
https://www.cnblogs.com/joyeecheung/p/3599698.html
https://www.cnblogs.com/yongzhewudi/p/5371396.html
希望大家科研顺利、工作顺利、不要出现莫名其妙的ERROR