一、数据挖掘,又称为数据库中知识发现(Knowledge Discovery from Database,简称KDD),它是一个从大量数据中抽取挖掘出未知的、有价值的模式或规律等知识的复杂过程。数据挖掘的定义过程描述如下图所示:
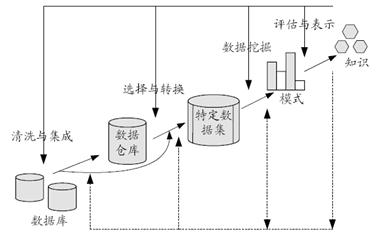
从图中可以看出,整个知识挖掘过程是由若干挖掘步骤组成,而数据挖掘仅仅是其中的一个主要步骤。整个KDD的主要步骤有:
1、 数据清洗(data cleaning),其作用就是清除数据噪声和与挖掘主体明显无关的数据;
2、 数据集成(data integration),其作用就是将来自多数据源中的相关数据组合到一起;
3、 数据转换(data transformation),其作用就是将数据转换为易于进行数据挖掘的数据存储形式;
4、 数据挖掘(data mining),它是知识挖掘的一个基本步骤,其作用就是利用智能方法挖掘数据模式或规律知识;
5、 模式评估(pattern evaluation),其作用就是根据一定评估标准(interesting measure)从挖掘结果筛选出有意义的模式知识;
6、 知识表示(knowledge presentation),其作用就是利用可视化和知识表达技术,向用户展示所挖掘的相关知识。
二、一个典型的数据挖掘系统,如下图所示,主要包括以下主要部件:

1、 数据库、数据仓库或其他信息库,它表示数据挖掘对象是由一个(或组)数据库、数据仓库、数据表单或其他信息数据库组成。通常需要使用数据清洗和数据集成操作,对这些数据对象进行初步的处理;
2、 数据库或数据仓库服务器,这类服务器负责根据用户的数据挖掘请求,读取相关的数据;
3、 知识库,此处存放数据挖掘所需要的领域知识,这些知识将用于指导数据挖掘的搜索过程,或者用于帮助对挖掘结果的评估。挖掘算法中所使用的用户定义的阀值就是最简单的领域知识;
4、 数据挖掘引擎,这是数据挖掘系统的最基本部件,它通常包含一组挖掘功能模块,以便完成定性归纳、关联分析、分类归纳、进化计算和偏差分析等挖掘功能;
5、 模式评估模块,该模块可根据趣味标准(interestingness measures),协助数据挖掘模块聚焦挖掘更有意义的模式知识。当然该模块能够与数据挖掘模块有机结合,与数据挖掘模块所使用的具体挖掘算法有关。显然若数据挖掘算法能够与知识评估方法有机结合将有助提高数据挖掘的效率。
6、 可视化用户界面,该模块帮助用户与数据挖掘系统本身进行沟通交流。一方面用户通过该模块将自己的挖掘要求或任务提交给挖掘系统,以及提供挖掘搜索所需要的相关知识;另一方面系统通过该模块向用户展示或解释数据挖掘的结果或中间结果;此外该模块也可以帮助用户李岚数据对象内容与数据定义模式、评估挖掘出的模式知识,以及以多种形式展示挖掘出的模式知识。
三、分类(Classification)就是找出一组能够描述数据集合典型特征的模型(或函数),以便能够分类识别未知数据的归属或类别,即将未知事例映射到某种离散类别之一。分类模型(或函数)可以通过分类挖掘算法从一组训练样本数据(其类别归属已知)中学习获得。分类挖掘所获取的分类模型可以采用多种形式加以描述输出。其中主要的表示方法有:分类规则(IF-THEN)、决策树(decision trees)、数学公式(mathematical formulate)和神经网络。分类通常用于预测未知数据事例的归属类别,如一个银行客户的信用等级时属于A级、B级还是C级。但在一些情况下,需要预测某数据属性的值(连续数值),这样的分类就被称为预测(predication),尽管预测既包括连续数值得预测,也包括有限离散值得分类;但一般还是使用预测来表示对连续数值的预测;而使用分类表示对有限离散值的预测。
四、聚类分析:聚类分析(clustering analysis)与分类预测方法明显不同之处在于,后者所学习获取分类预测模型所使用的数据是已知类别归属(class-labeled data),而聚类分析所分析处理的数据无事先确定的类别归属,类别归属标志在聚类分析处理的数据集中式不存在的。
聚类分析中,首先需要根据“各聚集(clusters)内部数据对象间的相似度最大化;而各聚集(clusters)对象间相似度最小化”的基本聚类分析原则,以及度量数据对象之间相似度的计算公式,将聚类分析的数据对象划分为若干组(groups)。因此一个组中数据对象间的相似度要比不同组数据对象间的相似度要大。每一个聚类分析所获得的组就可以视为是一个同类别归属的数据对象稽核,更进一步从这些同类别数据集,又可以通过分类学习获得相应得分类预测模型(规则)。此外,通过反复不断地对获得的聚类组进行聚类分析,还可获得初始数据稽核的一个层次结构模型。
一个数据库中的数据一般不可能都符合分类预测或聚类分析所获得的模型。那些不符合大多数数据对象所构成的规律(模型)的数据对象就被称为异类(outlier)之前许多数据挖掘方法都在正式进行数据挖掘之前就将这些异类作为噪声或意外而将其派出在数据挖掘的分析处理范围之外。但在一些应用场合,如各种商业欺诈行为的自动监测,小概率发生的事件(数据)往往比经常发生的事件(数据)更有挖掘价值。对异类数据的分析处理通常就成为异类挖掘。数据中的异类可以利用树立统计方法分析获得,即利用已知数据所获得的概率统计分布模型,或利用相似度计算所获得的相似数据对象分布,分析确认异类数据。而偏离监测就是从数据已有或期望中找出某些关键 测度显著的变化。
数据演化分析(evolution analysis)就是对随时间变化的数据对象的变化规律和趋势进行建模描述。这一建模手段包括:概念描述、对比概念描述、关联分析、分类分析、时间相关数据(time-related)分析(这其中又包括:时序数据分析、序列或周期模式匹配,以及基于相似性的数据分析)。