先看BoxDemo的前几节,
1.vertex input Layout
2.vertexBuffer
3.IndexBuffer
4.vertexShader
5.constant Buffer
6.pixelShader
7.renderState
8.effect
1.vertex input Layout
Once we have defined a vertex structure, we need to provide Direct3D with a description of our vertex structure so that
it knows what to do with each component. This description is provided to Direct3D in the form of an input layout
(ID3D11InputLayout).
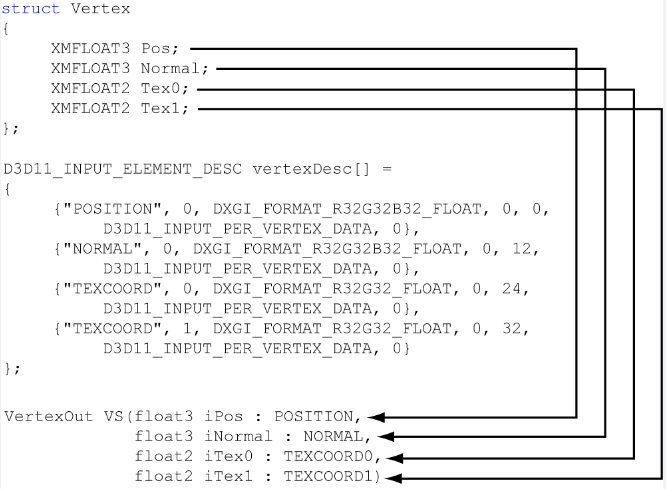
创建vertexStruct后,需要提供具体数据描述,告知渲染管线数据是啥。
1. SemanticName: A string to associate with the element. This can be any valid variable name. Semantics are used
to map elements in the vertex structure to elements in the vertex shader input signature
顶点结构每个语义和shader里参数的语义进行匹配。
当然了,vertexShader里不同语义的顺序并不是问题,比如说把
struct VertexIn
{
float4 Color : COLOR;
float3 PosL : POSITION; 切换成Position在前,Color在后,也是可正确绘制出box的,实际上是每个语以对应一个寄存器,但需要注意标记同语义的顺序;
};
void BoxApp::BuildVertexLayout()
{
// Create the vertex input layout.
D3D11_INPUT_ELEMENT_DESC vertexDesc[] =
{
{"POSITION", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 0, D3D11_INPUT_PER_VERTEX_DATA, 0},
{"COLOR", 0, DXGI_FORMAT_R32G32B32A32_FLOAT, 0, 12, D3D11_INPUT_PER_VERTEX_DATA, 0}
};
// Create the input layout
//1. pInputElementDescs: An array of D3D11_INPUT_ELEMENT_DESC elements describing the vertex structure.
2. NumElements: The number of elements in the D3D11_INPUT_ELEMENT_DESC elements array.
3. pShaderBytecodeWithInputSignature: A pointer to the shader byte-code of the input signature of the
vertex shader.
4. BytecodeLength: The byte size of the vertex shader signature data passed into the previous parameter.
5. ppInputLayout: Returns a pointer to the created input layout
D3DX11_PASS_DESC passDesc;
mTech->GetPassByIndex(0)->GetDesc(&passDesc);
//1.描述vertex struct的数组 2.数组元素 3.对应的shader内参数指针 4.size 5.获取layout
HR(md3dDevice->CreateInputLayout(vertexDesc, 2, passDesc.pIAInputSignature,
passDesc.IAInputSignatureSize, &mInputLayout));
}
After an input layout has been created, it is still not bound to the device yet. The last step is to bind the input layout
you want to use to the device as the following code shows:
md3dImmediateContext->IASetInputLayout(mInputLayout);
2.vertexBuffer
Direct3D buffers not only store data, but also describe how
the data will be accessed and where it will be bound to the rendering pipeline.
buffer不仅存数据,还描述了获取数据的方式和绑定到渲染管线的哪里
第四章已经描述过针对buffer的usage的四种类别
Usage:
1.default,GPU读和写,CPU可使用UpdateSubSource(不理解...待解释)
2.immuate:GPU只读, 本次boxDemo中,vertex和index都是使用的此usage,因为并没有改变vertexBuffer内的值
3.dynamic :CPU可写,GPU读,用于每帧app修改数据
4.staging : CPU可从GPU中Copy数据进行读写。
CPUAccessFlags:
If the CPU needs to read from the buffer, specify D3D11_CPU_ACCESS_READ. A buffer with read access must
have usage D3D11_USAGE_STAGING.
In general, the CPU reading
from a Direct3D resource is slow (GPUs are optimized to pump data through the pipeline, but not read back) and
can cause the GPU to stall (the GPU may need to wait for the resource being read from to finish before it can
continue its work). The CPU writing to a resource is faster, but there is still the overhead of having to transfer the
updated data back to video memory. It is best to not specify any of these flags (if possible), and let the resource sit
in video memory where only the GPU writes and reads to it.
就是说CPU读GPU数据可能会造成GPU的延迟,
D3D11_BUFFER_DESC vbd;
vbd.Usage = D3D11_USAGE_IMMUTABLE;
vbd.ByteWidth = sizeof(Vertex) * 8;
vbd.BindFlags = D3D11_BIND_VERTEX_BUFFER;
vbd.CPUAccessFlags = 0;
vbd.MiscFlags = 0;
vbd.StructureByteStride = 0;
D3D11_SUBRESOURCE_DATA vinitData;
vinitData.pSysMem = vertices;
HR(md3dDevice->CreateBuffer(&vbd, &vinitData, &mBoxVB));
创建vertexBuffer后,为了输入到具体的pipeline,需要绑定buffer给设备:
md3dImmediateContext->IASetVertexBuffers(0,1,&mBoxVB,&stride,&offset);
3.index和indexBuffer
Note that DXGI_FORMAT_R16_UINT and
DXGI_FORMAT_R32_UINT are the only formats supported for index buffers.
4.VertexShader
If there is no geometry shader, then the vertex shader must at least do the projection transformation because
this is the space the hardware expects the vertices to be in when leaving the vertex shader (if there is
no geometry shader). If there is a geometry shader, the job of projection can be deferred to the
geometry shader.
A vertex shader (or geometry shader) does not do the perspective divide; it just does the projection matrix part.
The perspective divide will be done later by the hardware.
VS没有进行坐标归一化,只转换到齐次坐标系,硬件做了除w操作,到NDC空间。
6.Pixel shader
occluded by another pixel
fragment with a smaller depth value, or the pixel fragment may be discarded by a later pipeline test like the stencil
buffer test. Therefore, a pixel on the back buffer may have several pixel fragment candidates; this is the distinction
between what is meant by “pixel fragment” and “pixel,” although sometimes the terms are used interchangeably, but
context usually makes it clear what is meant.
(区分pixel和psF,一个pixel可能包括几个pixel fragment,然后进行fragment的筛选)
sv_target:指出PS的返回值类型要和renderTarget类型一致
7.renderState
D3D是典型的状态机。 状态一直保持不变,直到进行更新。inputLayout,vertex/index Buffer,
8.Effects
1. technique11: A technique consists of one or more passes which are used to create a specific rendering
technique. For each pass, the geometry is rendered in a different way, and the results of each pass are combined
in some way to achieve the desired result. For example, a terrain rendering technique may use a multi-pass
texturing technique. Note that multi-pass techniques are usually expensive because the geometry is redrawn for
each pass; however, multi-pass techniques are required to implement some rendering techniques.
2. pass: A pass consists of a vertex shader, optional geometry shader, optional tessellation related shaders, a pixel
shader, and render states. These components indicate how to process and shade the geometry for this pass. We
note that a pixel shader can be optional as well (rarely). For instance, we may just want to render to the depth
buffer and not the back buffer; in this case we do not need to shade any pixels with a pixel shader.
Creating Direct3D resources is expensive and should always be done at initialization time, and never at
runtime. That means creating input layouts, buffers, render state objects, and effects should always be
done at initialization time.
就是说 创建工作要在initialization时候。
mTech = mFX->GetTechniqueByName("ColorTech");
mfxWorldViewProj= mFX->GetVariableByName("gWorldViewProj")->AsMatrix();
Note that these calls update an internal cache in the effect object, and are not transferred over to GPU memory
until we apply the rendering pass . This ensures one update to GPU memory instead of many small updates,
which would be inefficient.
数据的更新是在Effect调用pass后,一次性进行的。instead of many small updates
mfxWorldViewProj->SetMatrix(reinterpret_cast<float*>(&worldViewProj));
D3DX11_TECHNIQUE_DESC techDesc;
mTech->GetDesc( &techDesc );
for(UINT p = 0; p < techDesc.Passes; ++p)
{
mTech->GetPassByIndex(p)->Apply(0, md3dImmediateContext);
// 36 indices for the box.
md3dImmediateContext->DrawIndexed(36, 0, 0);
}
When the geometry is drawn in a pass, it will be drawn with the shaders and render states set by that pass. The
ID3DX11EffectTechnique::GetPassByIndex method returns a pointer to an ID3DX11EffectPass
interface, which represents the pass with the specified index. The Apply method updates the constant buffers stored in
GPU memory, binds the shader programs to the pipeline, and applies any render states the pass sets. In the current
version of Direct3D 11, the first parameter of ID3DX11EffectPass::Apply is unused, and zero should be
specified; the second parameter is a pointer to the device context the pass will use.
GetPassByIndex 获取pass的index,Apply更新GPU中的constantBuffer,绑定shader程序到管线,应用renderState
书中有趣的还是shader中不同条件的pass选取;
Observe that we have added an additional uniform parameter to the pixel shader that denotes the quality level.
This parameter is different in that it does not vary per pixel, but is instead uniform/constant. Moreover, we do not
change it at runtime either, like we change constant buffer variables. Instead we set it at compile time, and since the
value is known at compile time, it allows the effects framework to generate different shader variations based on its
value. This enables us to create our low, medium, and high quality pixel shaders without us duplicating code (the
effects framework basically duplicates the code for us as a compile time process), and without using branching
instructions.
#define low 0
#define mid 1(...high..)
float4 PS(IN_P pin,unsigned int Quality)
{
if(Quality==low){...}
else if(Quality==mid){...}
}
techique11 techLow
{
pass0
{
SetPixelShader(compilerShader(PS_5_0,PS(low)))
}
}
techique11 techMid
{
pass0
{
SetPixelShader(compilerShader(PS_5_0,PS(mid)))
}
}
....
这种方式可以提高代码的利用率,同时编译时,根据PS的参数不同选择编译代码,不编译条件不满足的部分。也许相当于预编译把。
添加ESC退出:在D3DApp.MsgProc.switch 函数内添加:
//增添esc退出操作
case WM_KEYDOWN:
if (GetAsyncKeyState(VK_ESCAPE) & 0x8000)
{
PostQuitMessage(0);
return 0;
}