Hbase的列族式存储
列族就是多个数据列的组合,列族式可以说是表的schema的一部分,而列不是。Hbase可以说是列簇数据库,在创建表的时候要指定列族,而不需要指定具体的列。
Hbase Table组成:Table = rowkey + family + column + timestamp + value
数据存储模式:(Table, rowkey , family , column , timestamp) -> Value
Hbase数据存储原型
HBase 是一个稀疏的、分布式、持久、多维、排序的映射,它以行键(row key),列键(column key)和时间戳(timestamp)为索引。
Hbase在存储数据的时候,有两个SortedMap,首先按照rowkey进行字典排序,然后再对Column进行字典排序。

SortedMap< RowKey, LIst< SortedMap<Column,List<Value, Timestamp> > > >
Hbase数据表解析
我们分析下条语句,在hbase shell中,直接按create命令不带参数,hbase会提示建表的语法。
create 'demo:user', {NAME => 'f1', VERSIONS => 5, COMPRESSION => 'SNAPPY',COMPRESSION_COMPACT=>'snappy','REPLICATION_SCOPE'=>1}
- 表名字叫做'demo:user'
- NAME 列族名字是 f1,记住建表一定要指定列族名
- VERSION 是Hbase的表保存的数据版本数,默认保存3个版本
- REPLICATION_SCOPE 值可以为0或者1,0代表不复制,1代表启用复制
- COMPRESSION_COMPACT,COMPRESSION 是表的压缩类型
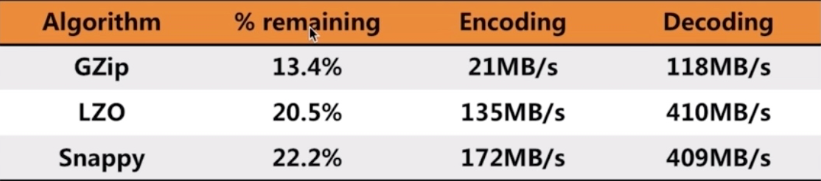
Hbase提供了三种常用的压缩类型,如下,并且官方给出的压缩率如下:
Hbase数据存储目录解析
我们在搭建Hbase的时候需要在hbase-site.xml中指定其存储目录,Hbase在指定的目录中构造数据数据


- .tmp 当对表进行创建和删除的时候会把表移动到.tmp目录下,然后再进行表操作,他是一个临时的数据交换目录
- WALS 理解为存储Hbase的操作日志
- archive 管理表的归档,这个由一个定时任务定时处理,管理和维护hbase的数据
- corrupt 一般是损坏的数据
- data 存储数据的核心目录
- hbase.id 标识hbase进程
- hbase.version 表名的
- oldWALs 日志已经被持久化之后,日志就被移动到这个目录下等待删除
- data/default 目录存储的是当前Hbase内包含的的表信息
- data/hbase 存储元数据和命名空间
Hbase的元信息表
hbase的元数据表为'hbase:meta',存储在ZooKeeper上面。它也是一张普通的hbase表。它的结构如下:
region是存储数据的最基本单元
Key:
-
table,key,time 三个部分的组合。因为Hbase根据rowkey排序,所有可用很快的找打对应的表
-
Values: 指向的是region server指向的region
-
info:regioninfo 对于region的基本信息存储,平时基本上用不到
-
info:server region服务器的地址和端口,这样就可以找到服务器
-
info:serverstartcode 数据校验的时候才用得到的里面的值也是会进行变化的。RegionServer挂掉,它也会及时的更新,Hbase表相当于Hbase的第一级索引,是Hbase最重要的系统表。
Hbase读取数据过程
在读数据的时候,客户端首先连接到ZooKeeper上面,然后查找"hbase:meta"表的位置,客户端查询"hbase:meta"表然后找到对应rowKey的Region,然后Region和RegionServer的信息缓存到客户端,在接下来的交互中就无需再次连接查询"hbase:meta"表了,如果缓存过期之后,客户端会发起一个新的查询,然后再缓存到本地。

在读取的时候,其中的WAL功能如下:
在写数据的时候,数据首先被写到日志文件中(write-ahead log),然后写到MemStore中。直接写到MemStore很有可能导致数据丢失的问题,因为它存储在内存中。一旦MemStore满了,MemStore的内容就会刷新到磁盘中的HFile文件中。
在发生故障的时候,WAL的作用就显示出来了。因为WAL存储在HDFS上面,一般会有多份的复制,任何一个服务器有复制的WAL都可以使用。
而HFile代表真实的数据存储文件,这个文件包含不同数量的数据块和固定数量的文件信息块。索引块记录数据和元数据块的偏移量,每一个数据块包含魔数头和许多的KeyValue实例。
以上内容来自:https://vip.kingdee.com/article/9416
参考
-
[Hbase .META table](https://stackoverflow.com/questions/25917701/hbase-meta-table)
-
[Hbase 官方参考](http://hbase.apache.org/book.html#arch.catalog.meta)
-
[Hbase 存储原理剖析](https://www.imooc.com/learn/996)
-
[几张图看懂列式存储](https://blog.csdn.net/dc_726/article/details/41143175)
-
[Hbase模式设计介绍](https://zhuanlan.zhihu.com/p/36235199)
-
[Hbase存储原理剖析](https://www.imooc.com/learn/996)
Hbase基本操作(shell操作)
在Hbase中,数据的存储都是二进制,并且列族和列都会根据字典顺序排序
$>hbase shell //登录shell终端.
$hbase>help //帮助
$hbase>help 'list_namespace' //查看特定的命令帮助,命名空间就如同关系型数据库中的库
$hbase>list_namespace //列出名字空间(如同数据库)
$hbase>list_namespace_tables 'defalut' //列出名字空间(如同数据库下的表)
$hbase>create_namespace 'ns1' //创建名字空间
$hbase>help 'create'
$hbase>create 'ns1:t1','f1' //创建表,指定空间下,并且指明列族
$hbase>put 'ns1:t1','row1','f1:id',100 //插入数据,指明RowKey,列族:列
$hbase>put 'ns1:t1','row1','f1:name','tom' //
$hbase>get 'ns1:t1','row1' //查询指定RowKey
$hbase>scan 'ns1:t1' //扫描表
$hbase>flush 'ns1:t1' //清理内存数据到磁盘。
$hbase>count 'ns1:t1' //统计函数
$hbase>disable 'ns1:t1' //删除表之前需要禁用表
$hbase>drop 'ns1:t1' //
$hbase>scan 'hbase:meta' //查看元数据表
不论哪一个shell我们首先要做的就是学会使用它自带的帮助文档,help是Hbase的帮助命令,如果想查看某个命令的用法,就用help '命令'查看。
元数据表meta
HMaster在Hbase集群启动的时候将存放数据的区域region指定到区域服务器HRegionServer节点上,并且将这些信息写到了一张名为meta的元数据表,这张表就想目录一样,用户在存储或是查找数据的时候通过这张表进行查找比对,找到自己操作所在的HRegionServer的区域region进行操作。
$hbase>list_namespace //列出名字空间(如同数据库)
发现有两个名字空间是默认的,default和hbase,我们看一下hbase名字空间下的表
$hbase>list_namespace_tables 'hbase' //列出名字空间(如同数据库下的表)
发现元数据meta表,使用scan来查看一下
$hbase>scan 'hbase:meta' //扫描表
发现我们建的所有表信息,都在这里面,包括在哪台HRegionServer节点上,我们拿出一些基本信息看一下
 此图仅供参考,不是原图。
此图仅供参考,不是原图。
如上图所示,最左边的 ns2:t2,,1532055628871.c4f8bb62217c308f2844aa5fcd599f69. 是HRegionServer节点分配的一个区域region名。从左边开始ns2:t2是我们建的名字空间ns2以及该名字空间下的表t2,紧接着的逗号标识开始行RowKey,如果一张表没有被切割过,就是默认的逗号,表示这张表没有被切割,是一张完整的表,如果被切割了,则切割处或是在所在区域的开始行RowKey。而c4f8bb62217c308f2844aa5fcd599f69则是HRegionServer节点分配的一个区域region编码,由前面的一串字符串按照MD5加密而来。
区域名所对应的右边column=列族:列记录了这个区域的一些基本信息,包括所在的HRegionServer节点s11:16020,开始行STARTKEY=>,ENDKEY=>,(都是逗号表示这个表没有被切割,从开始到结束)以及区域编码c4f8bb62217c308f2844aa5fcd599f69。有了这些基本信息我们就能够实时的读写了,根据匹配最左边的(例如ns2:t2,开始行RowKey,1532055628871.c4f8bb62217c308f2844aa5fcd599f69.)找到区域所在地HRegionServer节点地址,然后从HRegionServer节点上所对应的区域中查找存储数据。
Hbase既然将数据存储到了HDFS上,那目录结构是什么样子的呢?我们在搭建集群时候,已经配置在了hbse-site.xml中
在我们的HDFS的webui界面查找一下,发现其表数据存储目录结构格式为:hdfs://s10:8020/hbase/data/${名字空间}/${表名}/${区域名称}/${列族名称}/${文件名}
truncate 对表预分区信息的影响
使用hbase命令truncate 'tablename'后, 预分区信息没了,本来这张表进行了预分区,但是truncate之后表的预分区信息就没有了。要保留分区应该使用 truncate_preserve 'tablename'命令,如果直接使用truncate 'tablename'是不会保留分区的
create 'staff','info','partition1',SPLITS => ['1000','2000','3000','4000']
scan 'hbase:meta',{COLUMNS=>'info:regioninfo',FILTER=>"RowFilter(=, 'substring:staff,')" }
truncate_preserve 'staff'

truncate ‘staff’
