一、Flink概述
1.基本描述
Flink官网地址:Apache Flink® — Stateful Computations over Data Streams | Apache Flink
Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。

2.有界流和无界流
- 无界流(流):
- 有定义流的开始,没有定义结束。会无休止产生数据
- 无界流数据必须持续处理
- 有界流(批):
- 有定义流的开始,也有定义流的结束
- 可以拿到所有数据后再进行处理,并且做排序
- 有界流通常被称为批处理
3.有状态
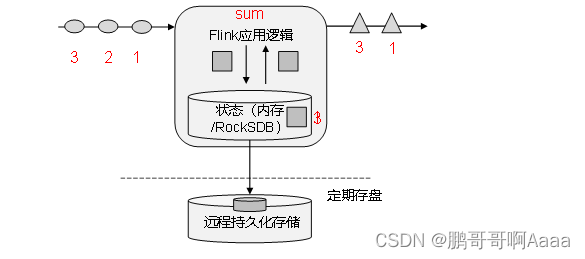
flink中除了流之外还会有额外的数据,用来对这些流做一些状态统计。
比如流是路上的汽车,我们是路边的人,数过去了多少车。过去一辆我们可以记一个,再过去就2个。也可以通过画正字的方式记录,最后通过统计正字来得到过去多少车。这里的数字以及正字,就是车以外的额外数据,用作统计。我们每来一个车统计一下,统计完之后可以对外输出。同时,每过一段时间会持久化一下,以防丢失。
4.flink的特点
低延迟、高吞吐、结果准确、良好的容错
- 高吞吐、低延迟:每秒可以处理数百万个事件,毫秒级延迟
- 结果准确:flink提供事件事件(event_time)和处理时间(processing_time)语义。对于乱序事件流,事件事件语序仍然能提供一致且精确的结果
- 精确一次(exactly-once)的状态一致性保证
- 可以连接到常见的存储系统:kafka,hive,jdbc,hdfs,redis等
- 高可用:本身就是高可用,配合k8s,yarn和mesos的紧密集成,再加上从故障中快速恢复和动态扩展的能力,可以以极少的停机时间实现7*24小时运行
5.flink和spark的区别
- spark以批处理为根本
- spark采用rdd模型,所谓rdd就是每3秒看做的一个批次,spark引擎处理这三秒的数据。spark streaming的Dstream实际上就是一组组rdd的集合
- spark是批计算,将DAG划分为不同的stage,一个完成才计算下一个
- Flink以流处理为根本
- flink基本模型是数据流,以及事件序列
- flink是标准的流执行模式,一个事件在一个节点处理完之后可以直接下发下一个节点处理
spark:

flink:
|
flink |
spark |
| 计算模型 |
流计算 |
微批计算 |
| 时间语序 |
事件事件、处理时间 |
处理时间 |
| 窗口 |
多、灵活 |
少、不灵活
窗口必须是批次的整数倍 |
| 状态 |
有 |
没有 |
| 流式sql |
有 |
没有 |
6.flink应用场景
电商、市场营销
物联网(IOT)
物流配送,服务业
银行,金融
7.flink分层api

- 有状态流处理:通过底层api (处理函数),对最原始的数据加工处理。与DataStream api集成,可以处理复杂计算
- DataStream(流处理)/DataSet(批处理) api:封装了底层api,提供转换、连接、聚合、窗口等通用模块。在flink1.12之后,DataSet被合到DataStream里面去了,即DataStream是批流都可以处理的api
- Table api:以表为中心的声明式编程。可以与DataStream无缝切换
- sql:以sql查询表达式的形式表现程序,可以在table api的表上执行
简单来说,就是flink的一层层封装。
二、Flink快速上手
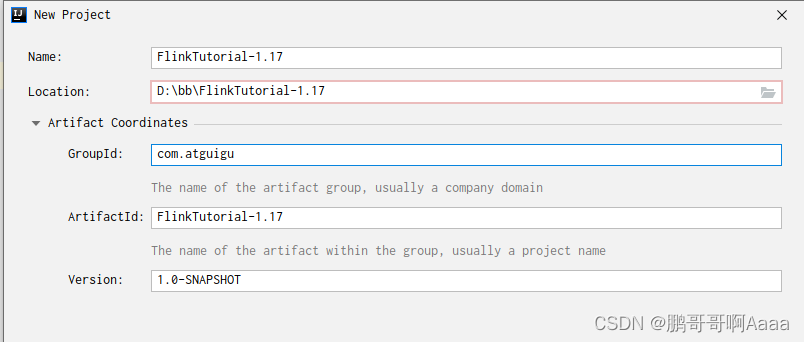
1.创建项目
新建一个maven项目:
2.导入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.atguigu</groupId>
<artifactId>FlinkTutorial-1.17</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
</project>
3.创建文件夹
新建一个input文件夹,里面一个txt,随便输入一些单词

4.批处理形式的word count编写(已过时)
注:此种方式使用的是DataSet API。我们新的版本已经将批和流都统一到DataStream API中了,因此这种方式的代码编写看一看就好,已过时。
package com.atguigu.wc;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* TODO DataSet API 实现 wordcount(不推荐)
*/
public class BatchWordCount {
public static void main(String[] args) throws Exception {
// TODO 1. 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// TODO 2.读取数据:从文件中读取
DataSource<String> lineDS = env.readTextFile("input/word.txt");
// TODO 3.切分、转换 (word,1)
FlatMapOperator<String, Tuple2<String, Integer>> wordAndOne = lineDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
// TODO 3.1 按照 空格 切分单词
String[] wo