博主简介
博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c++,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,如果有错误之处,大家可以指正。
专栏简介: 本专栏主要研究计算机视觉,涉及算法,案例实践,网络模型等知识。包括一些常用的数据处理算法,也会介绍很多的Python第三方库。如果需要,点击这里订阅专栏 。
给大家分享一个我很喜欢的一句话:“每天多努力一点,不为别的,只为日后,能够多一些选择,选择舒心的日子,选择自己喜欢的人!”

目录
 编辑前言
编辑前言
编辑目标识别的概念
编辑神经网络的使用
 编辑构建数据集的方法
编辑构建数据集的方法
编辑搭建神经网络
编辑训练及效果评估
编辑解决过拟合
编辑数据增强
编辑迁移学习
 前言
前言
前面我们介绍了深度学习中的神经网络,那么本届我们就开始正式的进入深度学习中了,前面我们介绍过计算机视觉的四大任务:目标识别、目标检测、目标跟踪和目标分割。其中最基础的就是目标识别,几乎所有的计算机视觉的知识都是在目标识别问题上构建的,也就是说目标识别问题构成了整个计算机视觉的地基,如果我们不能解决识别问题,就无法建造我们的计算机视觉大厦。
本章,我们就通过一个项目实战来全面认识目标识别。本节我们用到的数据集:数据集下载。
 目标识别的概念
目标识别的概念
目标识别的概念在前面我们就已经介绍过了,计算机视觉之所以叫做计算机视觉,这是用为这是基于计算机,模仿人类视觉的一种概念模型。但是计算机始终计算机,它并不能像人一样直接分别出物体,而是对物体进行标记。比如说,我们对一堆照片进行识别的时候,里面的猫识别成功后标记为1,如果是狗就标记为2.也就是他的识别是已经规划好的数据,并不能随机应变。
其次,计算机输出的是物体类别的概率,例如,第一类的概率为0.9,第二类的概率为0.1,最后取最大概率对应的类别进行输出,这与人类识别物体是不同的,从这方面可以看出,计算机是非常严谨的,应为他不会认为某一个类别的概率为100%。
由于计算机对于每一类都输出概率,就出现了一个引申概念:top k准确率,顾名思义就是将输出概率最大的k个类别输出,只要猜对其中的一个,就认为计算机猜对了,这在目标识别的评价中很常见,因为一张图片中往往有多个目标,而标签只有一个,所以简单的才一次决定输赢是不合理的,k的值由类别的数量决定,一般取5~10.
神经网络的使用
构建数据集的方法
在进行神经网络的学习中,数据集的使用是非常重要的,在这个过程中,我们可以使用开源的数据集,也可以自己创建数据集。下面我们准备对猫狗大战数据集进行使用。
(1)、将图片构建成同样的大小,这是用与一般的卷积神经网络需要输入图片的大小固定。
(2)、对每张图片构建数据标签,对于猫狗大战,图片猫标记为0,图片狗标记为1.
(3)、将数据集分为训练集和测试集,一般比例为4:1,或5:1.为了防止过拟合,我们需要在训练集上训练,之后再测试集测试,当训练集和测试集最终表现差不多的时候,我们就可以认为模型没有过拟合,而最终的结果也需要使用测试集上的准确率。
(4)、分批次,对于深度学习,我们一般使用小批次梯度下降算法,所以我们需要确定每个批次图片的数量,数量需要更具我们的CPU或GPU的内存来决定,一般取64或129张图片为一个批次。
(5)、随机打乱训练集的图片顺序,为了提升训练结果,每训练完一遍数据集后,我们需要对数据集进行随机打乱顺序,确保每个批次输入的图片都是完全随机的,否则很容易陷入局部极值。
来吧,展示,上代码:
import tensorflow as tf
import os
#读取数据集并构建数据集
_URL='https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
#解压
path_to_zip=tf.keras.utils.get_file('cats_and_dogs.zip',origin=_URL,extract=True)
PATH=os.path.join(os.path.dirname(path_to_zip),'cats_and_dogs_filtered')
#分为训练集和测试集
train_dir=os.path.join(PATH,'train')
validation_dir=os.path.join(PATH,'validation')
#分为猫图片和狗图片
train_cats_dir=os.path.join(train_dir,'cats')
train_dogs_dir=os.path.join(train_dir,'dogs')
validation_cats_dir=os.path.join(validation_dir,'cats')
validation_dogs_dir=os.path.join(validation_dir,'dogs')
#批次大小
batch_size=64
epochs=20
#图片输入大小为150*150
IMG_HEIGHT=150
IMG_WIDTH=150
#从目录生成数据集,shuffle表示随机打乱数据顺序
train_data_gen=tf.keras.preprocessing.image.ImageDataGenerator()
train_data_gentor=train_data_gen.flow_from_directory(batch_size=batch_size,directory=train_dir,
shuffle=True,target_size=(IMG_HEIGHT,IMG_WIDTH),class_mode='binary')
val_data_gen=tf.keras.preprocessing.image.ImageDataGenerator()
val_data_gentor=val_data_gen.flow_from_directory(batch_size=batch_size,directory=validation_dir
,target_size=(IMG_HEIGHT,IMG_WIDTH),class_mode='binary')
 搭建神经网络
搭建神经网络
接下来我们需要根据图片的大小搭建一个合适的神经网络,对于初学者,建议使用10层左右的神经网络。一般来说,只对神经网络的第一层和最后一层有输入和输出大小的限制。例如,第一层的输入需要图片的形状,而最后一层的输出需要为物体类别数量。
第一层:3x3卷积层,32个输出通道,输入形状为图片的形状:150x150x3,填充1个像素,激活函数为relu()。
第二层:2x2的最大池化层。
第三层:3x3的卷积层,64个输出通道,填充一个像素,激活函数为relu()。
第四层:2x2的最大池化层。
第五层:3x3的卷积层,64个输出通道,填充一个像素,激活函数为relu()。
第六层:2x2的最大池化层。
第七层:输出为256维的全连接层,激活函数为relu()。
第八层:输出为1维的全连接层,激活函数为sigmoid()。
#搭建神经网络
#每一行代表神经网络的一层
model=tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32,3,padding='same',activation='relu',input_shape=(IMG_HEIGHT,IMG_WIDTH,3)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64,3,padding='same',activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64,3,padding='same',activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256,activation='relu'),
tf.keras.layers.Dense(1,'sigmoid')
])
训练及效果评估
为了防止可能出现错误,我们先不要再整个数据机上训练,而是在小规模的数据集上训练,保证模型可以在小规模数据集上过拟合,进而使用整个数据集。
接下来就可以训练了,我们需要选择优化器,一般来说Adam优化器可以解决大部分问题,损失函数我们一般选择交叉熵损失,在本例中我们使用二分类交叉熵。训练过程中我们可以美国一定部署把当前损失和准确率记录下来,以此来判断模型训练的效果。当我们发现损失函数不再下降时应该即时停止训练。
#训练
#编译模型,输入优化器,损失函数,训练过程需要保存的特征
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
#训练
history=model.fit_generator(
train_data_gen,
steps_per_epoch=100//batch_size, #每轮的步数
epochs=epochs,
validation_data=val_data_gen,
validation_steps=100//batch_size
)
解决过拟合
当我们使用的数据集比较小的时候,就需要用一定的方法防止过拟合。所以可以通过减小模型参数来解决过拟合问题。
model1=tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32,3,padding='same',activation='relu',input_shape=(IMG_HEIGHT,IMG_WIDTH,3)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32,3,padding='same',activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(1,activation='sigmoid')
])
第二种方法是增加正则化项,常用的为L1和L2正则化方法。在神经网络中我们一般用L2正则化方法,我们需要调整权重系数,有一个神奇的值0.0005,此值可以作为大部分问题的权重系数。
model=tf.keras.Sequential([
tf.keras.layers.Conv2D(32,3,padding='same',activation='relu',input_shape=(IMG_HEIGHT,IMG_WIDTH,3),kernel_regularizer=tf.keras.regularizers.l2(l=0.0005)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64,3,padding='same',activation='relu',input_shape=(IMG_HEIGHT,IMG_WIDTH,3),kernel_regularizer=tf.keras.regularizers.l2(l=0.0005)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64,3,padding='same',activation='relu',input_shape=(IMG_HEIGHT,IMG_WIDTH,3),kernel_regularizer=tf.keras.regularizers.l2(l=0.0005)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256,activation='relu',kernel_regularizer=tf.keras.regularizers.l2(l=0.0005)),
tf.keras.layers.Dense(1,activation='sigmoid',kernel_regularizer=tf.keras.regularizers.l2(l=0.0005))
])
第三种方法是加入Dropout层,Dropout层的原理在前面已经讲过,一般来说Dropout层的效果比前两个更好,我们需要调整删除神经元的概率,一般设为0.5.
#增加Dropout层
model=tf.keras.Sequential([
tf.keras.layers.Conv2D(32,3,padding='same',activation='relu',input_shape=(IMG_HEIGHT,IMG_WIDTH,3)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Dropout(0.5), #设置Dropout层
tf.keras.layers.Conv2D(64,3,padding='same',activation='relu'),
tf.keras.layers.Dropout(0.5), #Dropout层
tf.keras.layers.Conv2D(64,3,padding='same',activation='relu'),
tf.keras.layers.MaxPooling2D(), #池化层
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256,activation='relu'), #全连接层
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(1,activation='sigmoid')
])
当然,我们可以把前几个方法结合在一起,组成一个最佳的模型,最后,对于深度学习,还有一个非常重要的超参数,就是学习效率。一般来说,我么可以从0.001开始调整,当学习率太高时,我们难以得到高精度的结果;当学习率太小时,训练时间很长。
#调整学习率
#学习率先用0.001训练
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),loss='sparse_categorical_crossentropy',metrics=['accuracy'])
#学习率调小为原来的1/10
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001),loss='sparse_categorical_crossentropy',metrics=['accuracy'])
数据增强
如果我们使用的数据非常少,那么我们得到的数据就不会很准确。这时候就需要数据增强,其实说简单点,就是将数据集增多,例如你有2000张图片,我们可以翻转,变色等方式改变图片,以此达到增加数据。在之后的训练中,每轮如果还是用2000张图片进行训练,但是每一轮的图片都是不同的。经过了随机变换,得到的数据模型会更加准确。
#随即水平反转
image_gen=tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255,horizontal_flip=True)
#随机竖直翻转
image_gen=tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255,vertical_flip=True)
#随即旋转
image_gen=tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255,rotation_range=45)
#随即缩放,zoom_range在0~1表示图片缩放比例范围[1-zoom_range,1+zoom_range]
image_gen=tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255,zoom_range=0.5)
#全部应用
image_gen_train=tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,
rotation_range=45,
width_shift_range=.15,
height_shift_range=.15,
horizontal_flip=True,
vertical_flip=True,
zoom_range=0.5
)
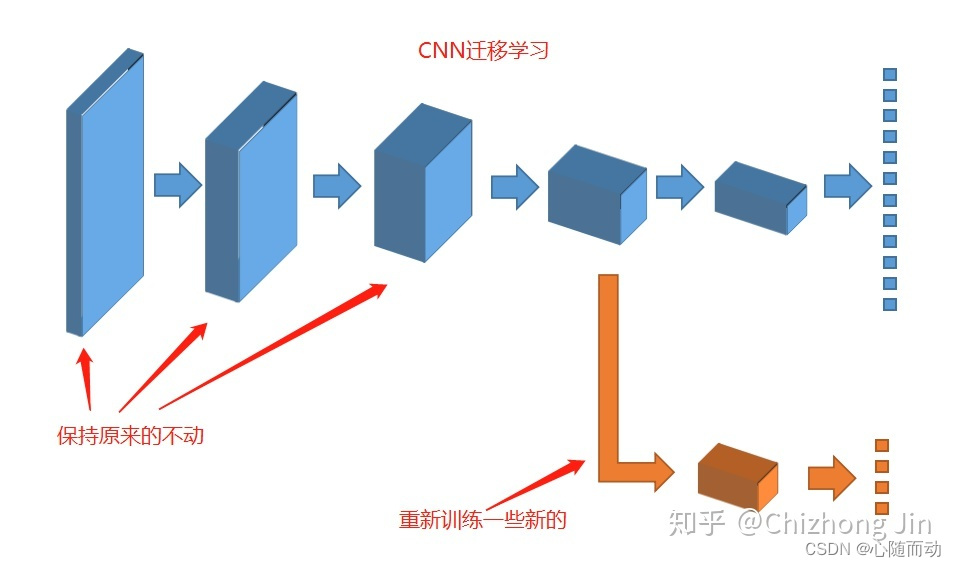
迁移学习
迁移学习是什么?
其实说的简单点就是借用别人的模型来进行训练自己的任务,优点就是速度快,效果好。就比如说,书本上的知识很详细,很多,但是理解起来可能没那么快,但是如果有一个人给你讲解,那是不是就很快能理解。也就是吸收别人的东西。
迁移学习主要有两种方法:第一种叫微调(Fine Tune),顾名思义就是对已经训练好的模型进行细微的调整,一般我们会调整整个模型的最后几层;
第二种方法叫作加层,就是在模型最后增加几层,然后对这几个层进行训练即可。
下面我借用ResNet50模型来简单的介绍一下如何使用迁移学习:
#选则基础模型
base_model=tf.keras.applications.ResNet50(weights='imagenet')
base_model.summary()
#将基础模型的参数设置为不可训练
base_model.trainable=False
#加层
prediction_layer1=tf.keras.layers.Dense(128,activation='relu')
prediction_layer2=tf.keras.layers.Dense(1,activation='sigmoid')
model=tf.keras.Sequential([
base_model,
prediction_layer1,
prediction_layer2
])
#微调
fine_tune_at=150
for layer in base_model.layers[fine_tune_at:]:
layer.trainable=True
base_model.summary()
prediction_layer=tf.keras.layers.Dense(1,activation='sigmoid')
model=tf.keras.Sequential([
base_model,
prediction_layer
])

好了,这里我们已经初步认识了如何搭建自己的神经网络和数据集以及一些啥=常规的方法,下一节我们就开始学习神经网络中的视觉了。拜拜了你嘞!
