泰迪智能科技(数据挖掘平台:TipDM数据挖掘平台)最新推出的数据挖掘实战专栏
专栏将数据挖掘理论与项目案例实践相结合,可以让大家获得真实的数据挖掘学习与实践环境,更快、更好的学习数据挖掘知识与积累职业经验
专栏中每四篇文章为一个完整的数据挖掘案例。案例介绍顺序为:先由数据案例背景提出挖掘目标,再阐述分析方法与过程,最后完成模型构建,在介绍建模过程中同时穿插操作训练,把相关的知识点嵌入相应的操作过程中。
为方便读者轻松地获取一个真实的实验环境,本专栏使用大家熟知的Python语言对样本数据进行处理以进行挖掘建模。
————————————————
评论分词
1. 分词、词性标注、去除停用词。
(1) 对评论数据进行分词
分词是文本信息处理的基础环节,是将一个单词序列切分成一个一个单词的过程。准确的分词可以极大的提高计算机对文本信息的是被和理解能力。相反,不准确的分词将会产生大量的噪声,严重干扰计算机的识别理解能力,并对这些信息的后续处理工作产生较大的影响。
汉语的基本单位是字,由字可以组成词,由词可以组成句子,进而由一些句子组成段、节、章、篇。可见,如果需要处理一篇中文语料,从中正确的识别出词是一件非常基础且重要的工作。
然而,中文以字为基本书写单位,词与词之间没有明显的区分标记。中文分词的任务就是把中文的序列切分成有意义的词,即添加合适的词串使得所形成的词串反映句子的本意,中午分词例子如表1所示。
表1 中文分词例子

当使用基于词典的中文分词方法进行中文信息处理时不得不考虑未登录词的处理。未登录词指词典中没有登录过的人名、地名、机构名、译名及新词语等。当采用匹配的办法来切分词语时,由于词典中没有登录这些词,会引起自动切分词语的困难。常见的未登陆词有命名实体,如“张三”“北京”“联想集团”“酒井法子”等;专业术语,如“贝叶斯算法”“模态”“万维网”;新词语,如“卡拉OK”“美刀”“啃老族”等。
另外,中文分词还存在切分歧义问题,如“当结合成分子时”这个句子可以有以下切分方法:“当/结合/成分/子时”,“当/结合/成/分子/时”,“当/结/合成/分子/时”,“当/结/合成分/子时”。
可以说,中文分词的关键问题为:切分歧义的消解和未登录词的识别。
词典匹配是分词最为传统也最为常见的一种办法。匹配方式可以为正向(从左到右)或逆向(从右到左)。对于匹配中遇到的多种分段可能性(segmentation ambiguity),通常会选取分隔出来词的数目最少的。
很明显,这种方式对词表的依赖很大,一旦出现词表中不存在的新词,算法是无法做到正确的切分的。但是词表匹配也有它的优势,比如简单易懂,不依赖训练数据,易于纠错等等。
还有一类方法是通过语料数据中的一些统计特征(如互信息量)去估计相邻汉字之间的关联性,进而实现词的切分。这类方法不依赖词表,特别是在对生词的发掘方面具有较强的灵活性,但是也经常会有精度方面的问题。
分词最常用的工作包是jieba分词包,jieba分词是python写成的一个分词开源库,专门用于中文分词,其有三条基本原理,即实现所采用技术。
① 基于trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)。jieba分词自带了一个叫做dict.txt的词典,里面有2万多条词,包含了词条出现的次数(这个次数是作者自己基于人民日报语料等资源训练得出来的)和词性。trie树是有名的前缀树,若一个词语的前面几个字一样,表示该词语具有相同的前缀,可以使用trie树来存储,trie树存储方式具有查找速度快的优势。后一句的“生成句子中汉字所有可能成词情况所构成的有向无环图”意思是给定一个待切分的句子,生成一个如图1所示的有向无环图。
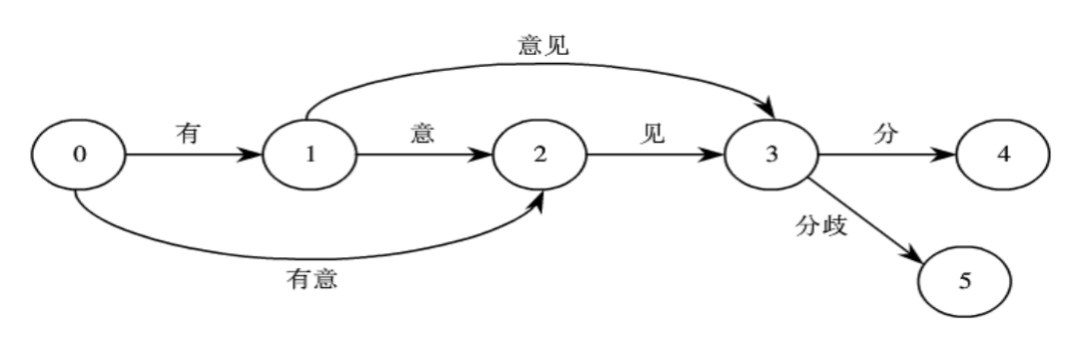
图1 “有意见分歧”切分生成的有向无环图
② 采用动态规划查找最大概率路径,找出基于词频的最大切分组合。先查找待分词句子中已经切分好的词语,再查找该词语出现的频率,然后根据动态规划查找最大概率路径的方法,对句子从右往左反向计算最大概率(反向是因为汉语句子的重心经常落在右边,从右往左计算,正确率要高于从左往右计算,这个类似于逆向最大匹配),最后得到最大概率的切分组合。
③ 对于未登录词,采用HMM模型,使用了Viterbi算法,将中文词汇按照BEMS四个状态来标记。其中B是begin,表示开始位置;E是end,表示结束位置;M是middle,表示中间位置;S是singgle,表示单独成词的位置。HMM模型采用(B,E,M,S)这四种状态来标记中文词语,比如北京可以标注为BE,即北/B京/E,表示北是开始位置,京是结束位置,中华民族可以标注为BMME,就是开始、中间、中间和结束。
(2) 去除停用词
停用词(Stop Words),词典译为“电脑检索中的虚字、非检索用字”。在SEO搜索引擎中,为节省存储空间和提高搜索效率,搜索引擎在索引页面或处理搜索请求时会自动忽略某些字或词,这些字或词即被称为停用词。
停用词一定程度上相当于过滤词(Filter Words),区别是过滤词的范围更大一些,包含情色、政治等敏感信息的关键词都会被视做过滤词加以处理,停用词本身则没有这个限制。通常意义上,停用词大致可分为如下两类。
一类是使用十分广泛,甚至是过于频繁的一些单词。比如英文的“i”“is”“what”,中文的“我”“就”等,这些词几乎在每个文档上均会出现,查询这样的词无法保证搜索引擎能够给出真正相关的搜索结果,因此无法缩小搜索范围来提高搜索结果的准确性,同时还会降低搜索的效率。因此,在搜索的时候,Google和百度等搜索引擎会忽略掉特定的常用词,如果使用了太多的停用词,有可能无法得到精确的结果,甚至可能得到大量毫不相关的搜索结果。
另一类是文本中出现频率很高,但实际意义又不大的词。这一类词主要包括了语气助词、副词、介词、连词等,通常自身并无明确意义,只有将其放入一个完整的句子中才有一定作用的词语。常见的有“的”“在”“和”“接着”等,例如“泰迪教育研究院是最好的大数据知识传播机构之一”这句话中的“是”“的”就是两个停用词。
经过分词后,评论由一个字符串的形式变为多个由文字或词语组成的字符串的形式,可判断评论中词语是否为停用词。根据上述停用词的定义整理出停用词库,并根据停用词库去除评论中的停用词,如代码清单1所示。
代码清单1 分词、词性标注、去除停用词代码
# 分词worker = lambda s: [(x.word, x.flag) for x in psg.cut(s)] # 自定义简单分词函数seg_word = content.apply(worker)
# 将词语转为数据框形式,一列是词,一列是词语所在的句子ID,最后一列是词语在该句子的位置n_word = seg_word.apply(lambda x: len(x)) # 每一评论中词的个数
n_content = [[x+1]*y for x,y in zip(list(seg_word.index), list(n_word))]index_content = sum(n_content, []) # 将嵌套的列表展开,作为词所在评论的id
seg_word = sum(seg_word, [])word = [x[0] for x in seg_word] # 词
nature = [x[1] for x in seg_word] # 词性
content_type = [[x]*y for x,y in zip(list(reviews['content_type']), list(n_word))]content_type = sum(content_type, []) # 评论类型
result = pd.DataFrame({"index_content":index_content, "word":word, "nature":nature, "content_type":content_type})
# 删除标点符号result = result[result['nature'] != 'x'] # x表示标点符号
# 删除停用词stop_path = open("../data/stoplist.txt", 'r',encoding='UTF-8')stop = stop_path.readlines()stop = [x.replace('\n', '') for x in stop]word = list(set(word) - set(stop))result = result[result['word'].isin(word)]
# 构造各词在对应评论的位置列n_word = list(result.groupby(by = ['index_content'])['index_content'].count())index_word = [list(np.arange(0, y)) for y in n_word]index_word = sum(index_word, []) # 表示词语在改评论的位置
# 合并评论id,评论中词的id,词,词性,评论类型result['index_word'] = index_word
2. 提取含名词的评论
由于本案例的目标是对产品特征的优缺点进行分析,类似“不错,很好的产品”,“很不错,继续支持”等评论虽然表达了对产品的情感倾向,但是实际上无法根据这些评论提取出哪些产品特征是用户满意的。评论中只有出现明确的名词,如机构团体及其它专有名词时,评论才有意义,因此需要对分词后的词语进行词性标注。之后再根据词性将含有名词类的评论提取出来。
jieba关于词典词性标记,采用ICTCLAS的标记方法。ICTCLAS汉语词性标注集如表2所示。
表2 ICTCLAS 汉语词性标注集

根据得出的词性,提取评论中词性含有“n”的评论,如代码清单2所示。
代码清单2 提取含有名词的评论
# 提取含有名词类的评论ind = result[['n' in x for x in result['nature']]]['index_content'].unique()result = result[[x in ind for x in result['index_content']]]3. 绘制词云查看分词效果
进行数据预处理后,可绘制词云查看分词效果,词云会将文本中出现频率较高的“关键词”予以视觉上的突出。首先需要对词语进行词频统计,将词频按照降序排序,选择前100个词,使用wordcloud模块中的WordCloud绘制词云,查看分词效果,如代码清单3所示。
代码清单3 绘制词云
import matplotlib.pyplot as pltfrom wordcloud import WordCloud
frequencies = result.groupby(by = ['word'])['word'].count()frequencies = frequencies.sort_values(ascending = False)backgroud_Image=plt.imread('../data/pl.jpg')wordcloud = WordCloud(font_path="STZHONGS.ttf", max_words=100, background_color='white', mask=backgroud_Image)my_wordcloud = wordcloud.fit_words(frequencies)plt.imshow(my_wordcloud)plt.axis('off') plt.show()
# 将结果写出result.to_csv("../tmp/word.csv", index = False, encoding = 'utf-8')
*代码请联系客服领取,联系方式见文末
运行代码清单3可得到分词后的词云图,如图2所示。

图2 分词后的词云图
根据图2可以看出,对评论数据进行预处理后,分词效果较为符合预期。其中“安装”“师傅”“售后”“物流”,“服务”等词出现频率较高,因此可以初步判断用户对产品这几个方面比较重视。
下一篇将推送:利用LDA主题模型提取京东评论数据(三)