【导读】大家好,我是泳鱼。一个乐于探索和分享AI知识的码农!
回归分析为许多机器学习算法提供了坚实的基础。在这篇文章中,我们将介绍回归分析概念、7种重要的回归模型、10 个重要的回归问题和5个评价指标。
什么是回归分析?
回归分析是一种预测性的建模技术,它研究的是因变量(目标)和自变量(预测器)之间的关系。这种技术通常用于预测分析,时间序列模型以及发现变量之间的因果关系。例如,司机的鲁莽驾驶与道路交通事故数量之间的关系,最好的研究方法就是回归。
回归分析是建模和分析数据的重要工具。在这里,我们使用曲线/线来拟合这些数据点,在这种方式下,从曲线或线到数据点的距离差异最小。我会在接下来的部分详细解释这一点。
我们为什么使用回归分析?
如上所述,回归分析估计了两个或多个变量之间的关系。下面,让我们举一个简单的例子来理解它:
比如说,在当前的经济条件下,你要估计一家公司的销售额增长情况。现在,你有公司最新的数据,这些数据显示出销售额增长大约是经济增长的2.5倍。那么使用回归分析,我们就可以根据当前和过去的信息来预测未来公司的销售情况。
使用回归分析的好处良多。具体如下:
它表明自变量和因变量之间的显著关系;
它表明多个自变量对一个因变量的影响强度。
回归分析也允许我们去比较那些衡量不同尺度的变量之间的相互影响,如价格变动与促销活动数量之间联系。这些有利于帮助市场研究人员,数据分析人员以及数据科学家排除并估计出一组最佳的变量,用来构建预测模型。
我们有多少种回归模型?
有各种各样的回归技术用于预测。这些技术主要有三个度量(自变量的个数,因变量的类型以及回归线的形状)。我们将在下面的部分详细讨论它们。
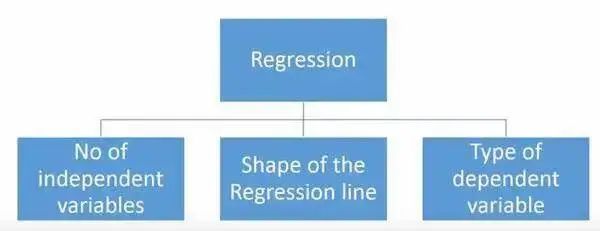
对于那些有创意的人,如果你觉得有必要使用上面这些参数的一个组合,你甚至可以创造出一个没有被使用过的回归模型。但在你开始之前,先了解如下最常用的回归方法:
1. Linear Regression线性回归
它是最为人熟知的建模技术之一。线性回归通常是人们在学习预测模型时首选的技术之一。在这种技术中,因变量是连续的,自变量可以是连续的也可以是离散的,回归线的性质是线性的。
线性回归使用最佳的拟合直线(也就是回归线)在因变量(Y)和一个或多个自变量(X)之间建立一种关系。
用一个方程式来表示它,即Y=a+b*X+e,其中a表示截距,b表示直线的斜率,e是误差项。这个方程可以根据给定的预测变量(s)来预测目标变量的值。
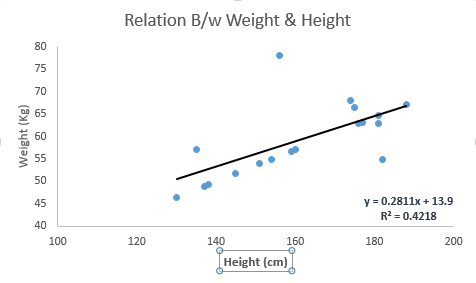
一元线性回归和多元线性回归的区别在于,多元线性回归有(>1)个自变量,而一元线性回归通常只有1个自变量。现在的问题是“我们如何得到一个最佳的拟合线呢?”。
如何获得最佳拟合线(a和b的值)?
这个问题可以使用最小二乘法轻松地完成。最小二乘法也是用于拟合回归线最常用的方法。对于观测数据,它通过最小化每个数据点到线的垂直偏差平方和来计算最佳拟合线。因为在相加时,偏差先平方,所以正值和负值没有抵消。
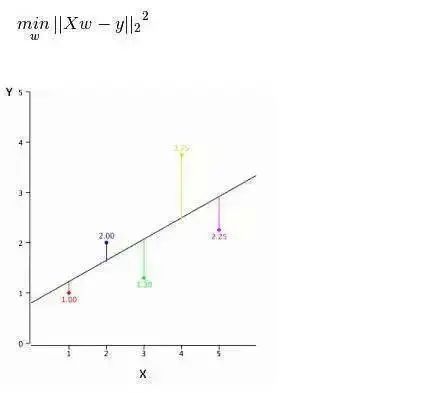
我们可以使用R-square指标来评估模型性能。想了解这些指标的详细信息,可以阅读:模型性能指标Part 1,Part 2。
要点:
1.自变量与因变量之间必须有线性关系。
2.多元回归存在多重共线性,自相关性和异方差性。
3.线性回归对异常值非常敏感。它会严重影响回归线,最终影响预测值。
4.多重共线性会增加系数估计值的方差,使得在模型轻微变化下,估计非常敏感。结果就是系数估计值不稳定
5.在多个自变量的情况下,我们可以使用向前选择法,向后剔除法和逐步筛选法来选择最重要的自变量。
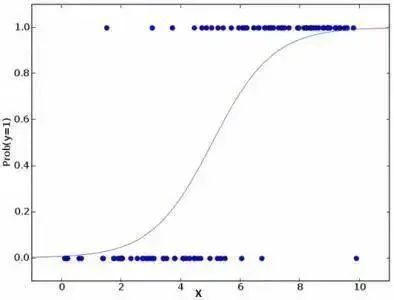
2. Logistic Regression逻辑回归
逻辑回归是用来计算“事件=Success”和“事件=Failure”的概率。
当因变量的类型属于二元(1 / 0,真/假,是/否)变量时,我们就应该使用逻辑回归。这里,Y的值从0到1,它可以用下方程表示。
odds= p/ (1-p) = probability of event occurrence / probability of not event occurrenceln(odds) = ln(p/(1-p))logit(p) = ln(p/(1-p)) = b0+b1X1+b2X2+b3X3....+bkXk
上述式子中,p表述具有某个特征的概率。你应该会问这样一个问题:“我们为什么要在公式中使用对数log呢?”。
因为在这里我们使用的是的二项分布(因变量),我们需要选择一个对于这个分布最佳的连结函数。它就是Logit函数。在上述方程中,通过观测样本的极大似然估计值来选择参数,而不是最小化平方和误差(如在普通回归使用的)。
要点:
1.它广泛的用于分类问题。
2.逻辑回归不要求自变量和因变量是线性关系。它可以处理各种类型的关系,因为它对预测的相对风险指数OR使用了一个非线性的log转换。
3.为了避免过拟合和欠拟合,我们应该包括所有重要的变量。有一个很好的方法来确保这种情况,就是使用逐步筛选方法来估计逻辑回归。
4.它需要大的样本量,因为在样本数量较少的情况下,极大似然估计的效果比普通的最小二乘法差。
5.自变量不应该相互关联的,即不具有多重共线性。然而,在分析和建模中,我们可以选择包含分类变量相互作用的影响。
6.如果因变量的值是定序变量,则称它为序逻辑回归。
7.如果因变量是多类的话,则称它为多元逻辑回归。
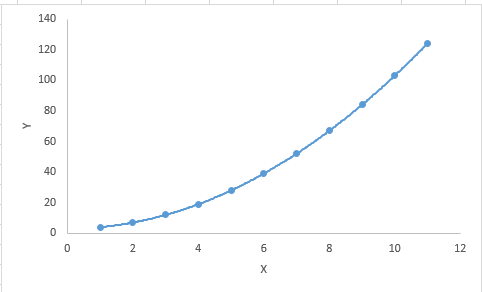
3. Polynomial Regression多项式回归
对于一个回归方程,如果自变量的指数大于1,那么它就是多项式回归方程。如下方程所示:y=a+b*x^2
在这种回归技术中,最佳拟合线不是直线。而是一个用于拟合数据点的曲线。
重点:
虽然会有一个诱导可以拟合一个高次多项式并得到较低的错误,但这可能会导致过拟合。你需要经常画出关系图来查看拟合情况,并且专注于保证拟合合理,既没有过拟合又没有欠拟合。
下面是一个图例,可以帮助理解:
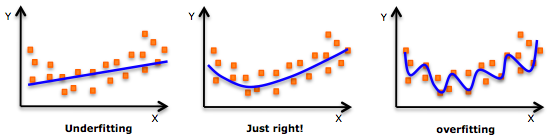
明显地向两端寻找曲线点,看看这些形状和趋势是否有意义。更高次的多项式最后可能产生怪异的推断结果。
4. Stepwise Regression逐步回归
在处理多个自变量时,我们可以使用这种形式的回归。在这种技术中,自变量的选择是在一个自动的过程中完成的,其中包括非人为操作。
这一壮举是通过观察统计的值,如R-square,t-stats和AIC指标,来识别重要的变量。逐步回归通过同时添加/删除基于指定标准的协变量来拟合模型。
下面列出了一些最常用的逐步回归方法:
标准逐步回归法做两件事情。即增加和删除每个步骤所需的预测。
向前选择法从模型中最显著的预测开始,然后为每一步添加变量。
向后剔除法与模型的所有预测同时开始,然后在每一步消除最小显着性的变量。
这种建模技术的目的是使用最少的预测变量数来最大化预测能力。这也是处理高维数据集的方法之一。
5. Ridge Regression岭回归
岭回归分析是一种用于存在多重共线性(自变量高度相关)数据的技术。在多重共线性情况下,尽管最小二乘法(OLS)对每个变量很公平,但它们的差异很大,使得观测值偏移并远离真实值。岭回归通过给回归估计上增加一个偏差度,来降低标准误差。
上面,我们看到了线性回归方程。还记得吗?它可以表示为:
y=a+b*x这个方程也有一个误差项。完整的方程是:
y=a+b*x+e (error term), [error term is the value needed to correct for a prediction error between the observed and predicted value]
=> y=a+y= a+ b1x1+ b2x2+....+e, for multiple independent variables.
在一个线性方程中,预测误差可以分解为2个子分量。一个是偏差,一个是方差。预测错误可能会由这两个分量或者这两个中的任何一个造成。在这里,我们将讨论由方差所造成的有关误差。
岭回归通过收缩参数λ(lambda)解决多重共线性问题。看下面的公式:
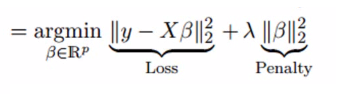
在这个公式中,有两个组成部分。第一个是最小二乘项,另一个是β2(β-平方)的λ倍,其中β是相关系数。为了收缩参数把它添加到最小二乘项中以得到一个非常低的方差。
要点:
1.除常数项以外,这种回归的假设与最小二乘回归类似;
2.它收缩了相关系数的值,但没有达到零,这表明它没有特征选择功能
3.这是一个正则化方法,并且使用的是L2正则化。
6. Lasso Regression套索回归
它类似于岭回归,Lasso (Least Absolute Shrinkage and Selection Operator)也会惩罚回归系数的绝对值大小。此外,它能够减少变化程度并提高线性回归模型的精度。看看下面的公式:

Lasso 回归与Ridge回归有一点不同,它使用的惩罚函数是绝对值,而不是平方。这导致惩罚(或等于约束估计的绝对值之和)值使一些参数估计结果等于零。使用惩罚值越大,进一步估计会使得缩小值趋近于零。这将导致我们要从给定的n个变量中选择变量。
要点:
1.除常数项以外,这种回归的假设与最小二乘回归类似;
2.它收缩系数接近零(等于零),这确实有助于特征选择;
3.这是一个正则化方法,使用的是L1正则化;
如果预测的一组变量是高度相关的,Lasso 会选出其中一个变量并且将其它的收缩为零。
7. ElasticNet回归
ElasticNet是Lasso和Ridge回归技术的混合体。它使用L1来训练并且L2优先作为正则化矩阵。当有多个相关的特征时,ElasticNet是很有用的。Lasso 会随机挑选他们其中的一个,而ElasticNet则会选择两个。
Lasso和Ridge之间的实际的优点是,它允许ElasticNet继承循环状态下Ridge的一些稳定性。
要点:
1.在高度相关变量的情况下,它会产生群体效应;
2.选择变量的数目没有限制;
3.它可以承受双重收缩。
除了这7个最常用的回归技术,你也可以看看其他模型,如Bayesian、Ecological和Robust回归。
如何正确选择回归模型?
当你只知道一个或两个技术时,生活往往很简单。我知道的一个培训机构告诉他们的学生,如果结果是连续的,就使用线性回归。如果是二元的,就使用逻辑回归!然而,在我们的处理中,可选择的越多,选择正确的一个就越难。类似的情况下也发生在回归模型中。
在多类回归模型中,基于自变量和因变量的类型,数据的维数以及数据的其它基本特征的情况下,选择最合适的技术非常重要。以下是你要选择正确的回归模型的关键因素:
1.数据探索是构建预测模型的必然组成部分。在选择合适的模型时,比如识别变量的关系和影响时,它应该首选的一步。
2. 比较适合于不同模型的优点,我们可以分析不同的指标参数,如统计意义的参数,R-square,Adjusted R-square,AIC,BIC以及误差项,另一个是Mallows’ Cp准则。这个主要是通过将模型与所有可能的子模型进行对比(或谨慎选择他们),检查在你的模型中可能出现的偏差。
3.交叉验证是评估预测模型最好额方法。在这里,将你的数据集分成两份(一份做训练和一份做验证)。使用观测值和预测值之间的一个简单均方差来衡量你的预测精度。
4.如果你的数据集是多个混合变量,那么你就不应该选择自动模型选择方法,因为你应该不想在同一时间把所有变量放在同一个模型中。
5.它也将取决于你的目的。可能会出现这样的情况,一个不太强大的模型与具有高度统计学意义的模型相比,更易于实现。
6.回归正则化方法(Lasso,Ridge和ElasticNet)在高维和数据集变量之间多重共线性情况下运行良好。
线性回归的假设是什么?
线性回归有四个假设:
线性:自变量(x)和因变量(y)之间应该存在线性关系,这意味着x值的变化也应该在相同方向上改变y值。
独立性:特征应该相互独立,这意味着最小的多重共线性。
正态性:残差应该是正态分布的。
同方差性:回归线周围数据点的方差对于所有值应该相同。
什么是残差,它如何用于评估回归模型?
残差是指预测值与观测值之间的误差。它测量数据点与回归线的距离。它是通过从观察值中减去预测值的计算机。
残差图是评估回归模型的好方法。它是一个图表,在垂直轴上显示所有残差,在 x 轴上显示特征。如果数据点随机散布在没有图案的线上,那么线性回归模型非常适合数据,否则我们应该使用非线性模型。
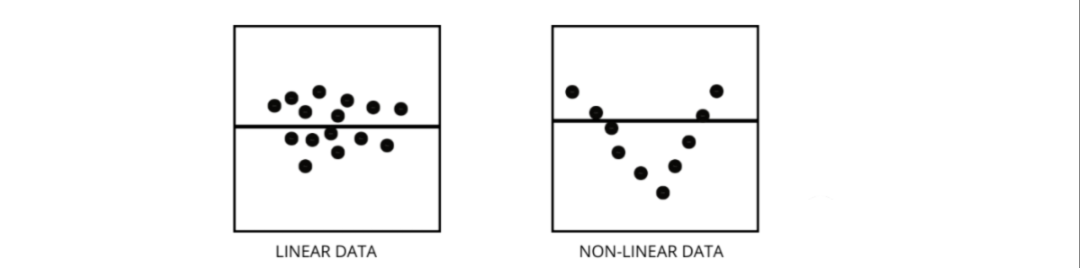
如何区分线性回归模型和非线性回归模型?
两者都是回归问题的类型。两者的区别在于他们训练的数据。
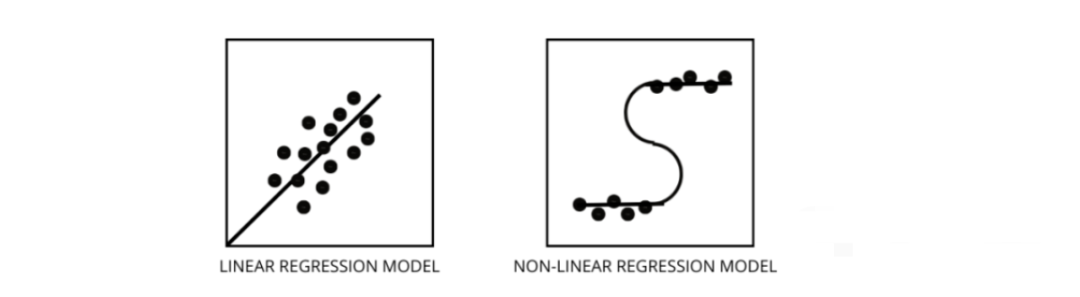
线性回归模型假设特征和标签之间存在线性关系,这意味着如果我们获取所有数据点并将它们绘制成线性(直线)线应该适合数据。
非线性回归模型假设变量之间没有线性关系。非线性(曲线)线应该能够正确地分离和拟合数据。
找出数据是线性还是非线性的三种最佳方法:
残差图;
散点图;
假设数据是线性的,训练一个线性模型并通过准确率进行评估。
什么是多重共线性,它如何影响模型性能?
当某些特征彼此高度相关时,就会发生多重共线性。相关性是指表示一个变量如何受到另一个变量变化影响的度量。
如果特征 a 的增加导致特征 b 的增加,那么这两个特征是正相关的。如果 a 的增加导致特征 b 的减少,那么这两个特征是负相关的。在训练数据上有两个高度相关的变量会导致多重共线性,因为它的模型无法在数据中找到模式,从而导致模型性能不佳。所以在训练模型之前首先要尽量消除多重共线性。
异常值如何影响线性回归模型的性能?
异常值是值与数据点的平均值范围不同的数据点。换句话说,这些点与数据不同或在第 3 标准之外。
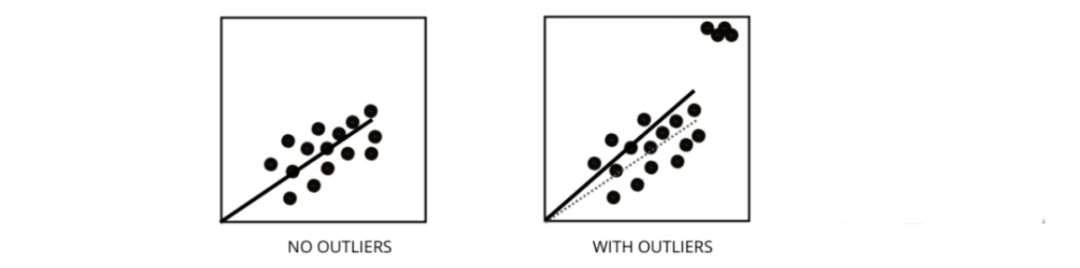
线性回归模型试图找到一条可以减少残差的最佳拟合线。如果数据包含异常值,则最佳拟合线将向异常值移动一点,从而增加错误率并得出具有非常高 MSE 的模型。
什么是 MSE 和 MAE 有什么区别?
MSE 代表均方误差,它是实际值和预测值之间的平方差。而 MAE 是目标值和预测值之间的绝对差。
MSE 会惩罚大错误,而 MAE 不会。随着 MSE 和 MAE 的值都降低,模型趋向于一条更好的拟合线。
L1 和 L2 正则化是什么,应该在什么时候使用?
在机器学习中,我们的主要目标是创建一个可以在训练和测试数据上表现更好的通用模型,但是在数据非常少的情况下,基本的线性回归模型往往会过度拟合,因此我们会使用 l1 和l2 正则化。
L1 正则化或 lasso 回归通过在成本函数内添加添加斜率的绝对值作为惩罚项。有助于通过删除斜率值小于阈值的所有数据点来去除异常值。
L2 正则化或ridge 回归增加了相当于系数大小平方的惩罚项。它会惩罚具有较高斜率值的特征。
l1 和 l2 在训练数据较少、方差高、预测特征大于观察值以及数据存在多重共线性的情况下都很有用。
异方差是什么意思?
它是指最佳拟合线周围的数据点的方差在一个范围内不一样的情况。它导致残差的不均匀分散。如果它存在于数据中,那么模型倾向于预测无效输出。检验异方差的最好方法之一是绘制残差图。
数据内部异方差的最大原因之一是范围特征之间的巨大差异。例如,如果我们有一个从 1 到 100000 的列,那么将值增加 10% 不会改变较低的值,但在较高的值时则会产生非常大的差异,从而产生很大的方差差异的数据点。
方差膨胀因子的作用是什么的作用是什么?
方差膨胀因子(vif)用于找出使用其他自变量可预测自变量的程度。
让我们以具有 v1、v2、v3、v4、v5 和 v6 特征的示例数据为例。现在,为了计算 v1 的 vif,将其视为一个预测变量,并尝试使用所有其他预测变量对其进行预测。
如果 VIF 的值很小,那么最好从数据中删除该变量。因为较小的值表示变量之间的高相关性。
逐步回归(stepwise regression)如何工作?
逐步回归是在假设检验的帮助下,通过移除或添加预测变量来创建回归模型的一种方法。它通过迭代检验每个自变量的显著性来预测因变量,并在每次迭代之后删除或添加一些特征。它运行n次,并试图找到最佳的参数组合,以预测因变量的观测值和预测值之间的误差最小。
它可以非常高效地管理大量数据,并解决高维问题。
除了MSE 和 MAE 外回归还有什么重要的指标吗?

我们用一个回归问题来介绍这些指标,我们的其中输入是工作经验,输出是薪水。下图显示了为预测薪水而绘制的线性回归线。
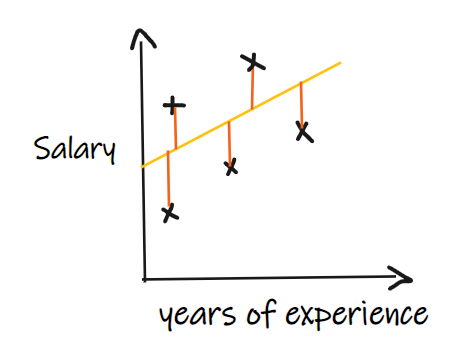
指标一:平均绝对误差(MAE)
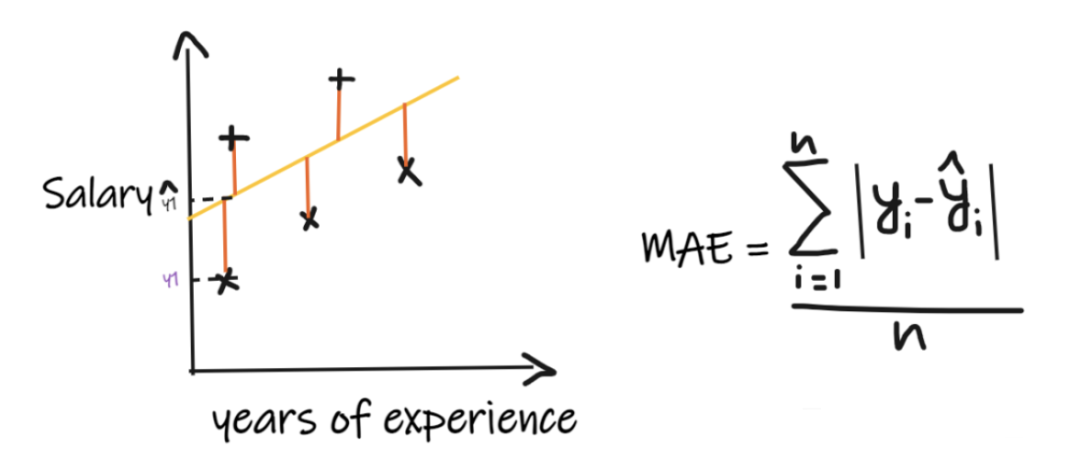
平均绝对误差 (MAE) 是最简单的回归度量。它将每个实际值和预测值的差值相加,最后除以观察次数。为了使回归模型被认为是一个好的模型,MAE 应该尽可能小。
MAE的优点是:简单易懂。结果将具有与输出相同的单位。例如:如果输出列的单位是 LPA,那么如果 MAE 为 1.2,那么我们可以解释结果是 +1.2LPA 或 -1.2LPA,MAE 对异常值相对稳定(与其他一些回归指标相比,MAE 受异常值的影响较小)。
MAE的缺点是:MAE使用的是模函数,但模函数不是在所有点处都可微的,所以很多情况下不能作为损失函数。
指标二:均方误差(MSE)
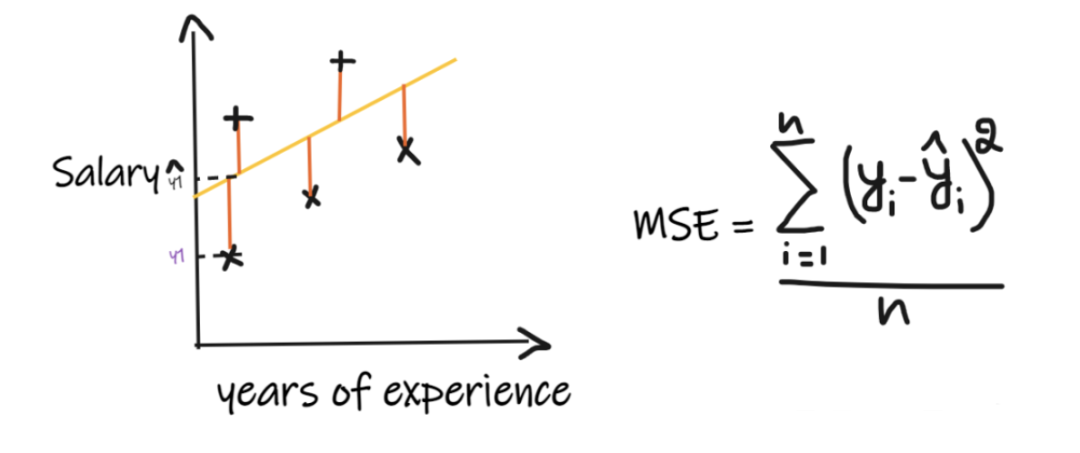
MSE取每个实际值和预测值之间的差值,然后将差值平方并将它们相加,最后除以观测数量。为了使回归模型被认为是一个好的模型,MSE 应该尽可能小。
MSE的优点:平方函数在所有点上都是可微的,因此它可以用作损失函数。
MSE的缺点:由于 MSE 使用平方函数,结果的单位是输出的平方。因此很难解释结果。由于它使用平方函数,如果数据中有异常值,则差值也会被平方,因此,MSE 对异常值不稳定。
指标三:均方根误差 (RMSE)
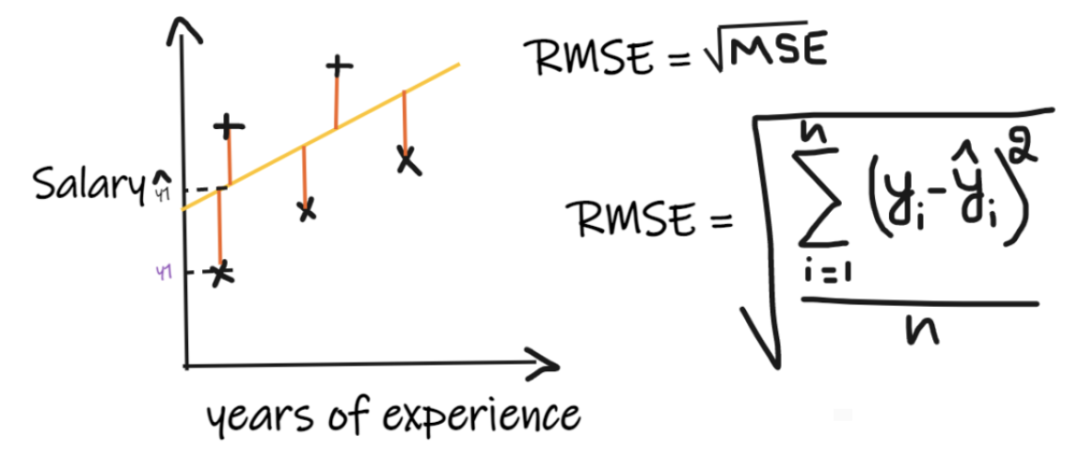
均方根误差(RMSE)取每个实际值和预测值之间的差值,然后将差值平方并将它们相加,最后除以观测数量。然后取结果的平方根。因此,RMSE 是 MSE 的平方根。为了使回归模型被认为是一个好的模型,RMSE 应该尽可能小。
RMSE 解决了 MSE 的问题,单位将与输出的单位相同,因为它取平方根,但仍然对异常值不那么稳定。
上述指标取决于我们正在解决的问题的上下文, 我们不能在不了解实际问题的情况下,只看 MAE、MSE 和 RMSE 的值来判断模型的好坏。
指标四:R2 score
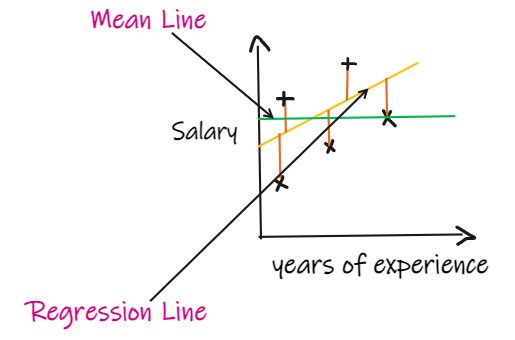
如果我们没有任何输入数据,但是想知道他在这家公司能拿到多少薪水,那么我们能做的最好的事情就是给他们所有员工薪水的平均值。
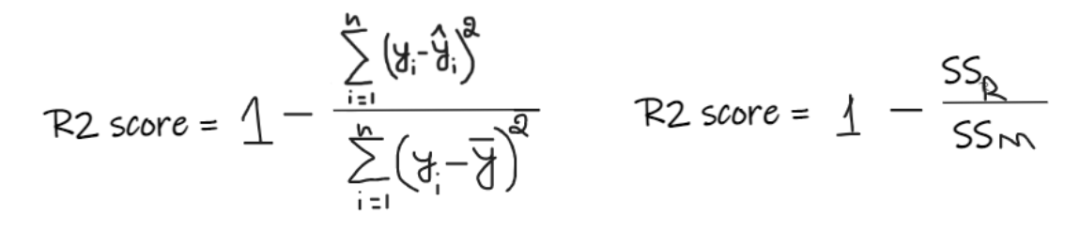
R2 score 给出的值介于 0 到 1 之间,可以针对任何上下文进行解释。它可以理解为是拟合度的好坏。
SSR 是回归线的误差平方和,SSM 是均线误差的平方和。我们将回归线与平均线进行比较。
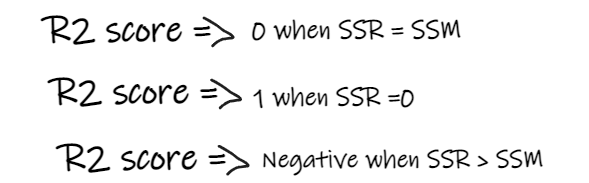
如果 R2 得分为 0,则意味着我们的模型与平均线的结果是相同的,因此需要改进我们的模型。
如果 R2 得分为 1,则等式的右侧部分变为 0,这只有在我们的模型适合每个数据点并且没有出现误差时才会发生。
如果 R2 得分为负,则表示等式右侧大于 1,这可能发生在 SSR > SSM 时。这意味着我们的模型比平均线最差,也就是说我们的模型还不如取平均数进行预测。
如果我们模型的 R2 得分为 0.8,这意味着可以说模型能够解释 80% 的输出方差。也就是说,80%的工资变化可以用输入(工作年限)来解释,但剩下的20%是未知的。
如果我们的模型有2个特征,工作年限和面试分数,那么我们的模型能够使用这两个输入特征解释80%的工资变化。
R2的缺点:
随着输入特征数量的增加,R2会趋于相应的增加或者保持不变,但永远不会下降,即使输入特征对我们的模型不重要(例如,将面试当天的气温添加到我们的示例中,R2是不会下降的即使温度对输出不重要)。
指标五:Adjusted R2 score
上式中R2为R2,n为观测数(行),p为独立特征数。Adjusted R2解决了R2的问题。
当我们添加对我们的模型不那么重要的特性时,比如添加温度来预测工资.....

当添加对模型很重要的特性时,比如添加面试分数来预测工资……


往期精彩回顾
