1.spark sql数据类型
数字类型
● ByteType:代表一个字节的整数。范围是-128到127
● ShortType:代表两个字节的整数。范围是-32768到32767
● IntegerType:代表4个字节的整数。范围是-2147483648到2147483647
● LongType:代表8个字节的整数。范围是-9223372036854775808到9223372036854775807
● FloatType:代表4字节的单精度浮点数 DoubleType:代表8字节的双精度浮点数
● DecimalType:代表任意精度的10进制数据。通过内部的java.math.BigDecimal支持。BigDecimal由一个任意精度的整型非标度值和一个32位整数组成
● StringType:代表一个字符串值
● BinaryType:代表一个byte序列值
● BooleanType:代表boolean值
日期类型
● TimestampType:代表包含字段年,月,日,时,分,秒的值
● DateType:代表包含字段年,月,日的值
复杂类型
● ArrayType(elementType, containsNull):代表由elementType类型元素组成的序列值。containsNull用来指明ArrayType中的值是否有null值
● MapType(keyType, valueType, valueContainsNull):表示包括一组键 - 值对的值。通过keyType表示key数据的类型,通过valueType表示value数据的类型。valueContainsNull用来指明MapType中的值是否有null值
● StructType(fields):表示一个拥有StructFields (fields)序列结构的值
StructField(name, dataType, nullable):代表StructType中的一个字段,字段的名字通过name指定,dataType指定field的数据类型,nullable表示字段的值是否有null值。
2.spark sql和scala数据类型对比
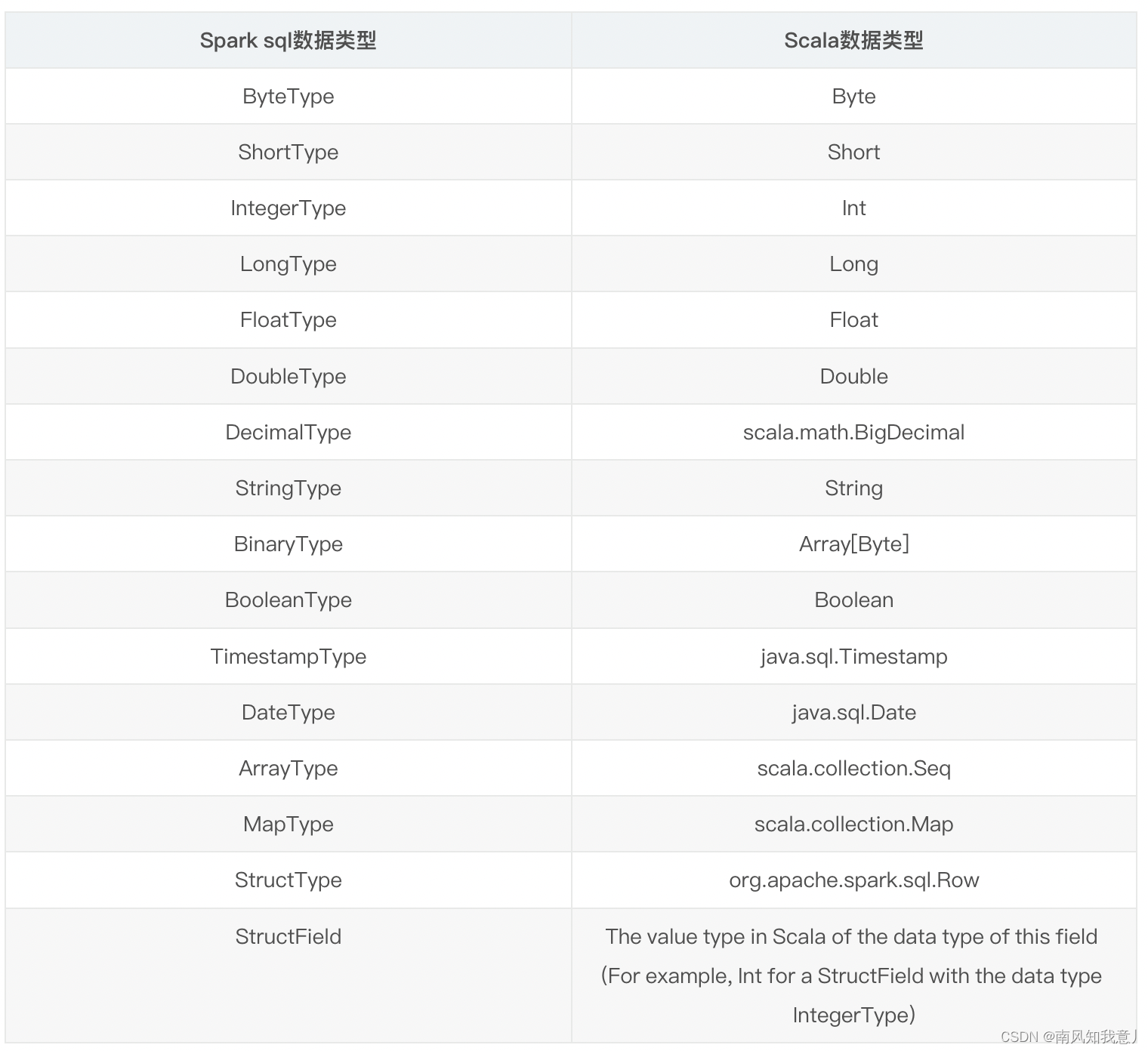
3.spark sql数据类型转换示例
● 三种方式
● withColumn (推荐)
● selectExpr
● sql
代码
package com.lzx.sparktuning.dataType
import org.apache.spark.SparkContext
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types.{BooleanType, DateType, StringType}
import org.apache.spark.sql.{DataFrame, SparkSession}
object ModifyDataType {
def main(args: Array[String]): Unit = {
val session: SparkSession = SparkSession.builder().appName(this.getClass.getSimpleName).master("local[*]").getOrCreate()
val sc: SparkContext = session.sparkContext
val list: List[(String, Int, String, String, String, Double)] =
List(
("James", 34, "2006-01-01", "true", "M", 3000.60),
("Michael", 33, "1980-01-10", "true", "F", 3300.80),
("Robert", 37, "1992-06-01", "false", "M", 5000.50)
)
import session.implicits._
val df: DataFrame = sc.parallelize(list).toDF("name", "age", "birthday", "isGraduated", "sex", "salary")
df.printSchema()
df.show(false)
//1.withColumn
println("withColumn---")
val df2: DataFrame = df.withColumn("age", col("age").cast(StringType))
.withColumn("isGraduated", col("isGraduated").cast(BooleanType))
.withColumn("birthday", col("birthday").cast(DateType))
df2.printSchema()
df2.show(false)
//2.selectExpr
println("selectExpr----")
val df3: DataFrame = df.selectExpr(
"cast(age as string) age",
"cast(isGraduated as boolean) isGraduated",
"cast(birthday as date) birthday"
)
df3.printSchema()
df3.show(false)
//3.sql
println("sql---")
df.createOrReplaceTempView("tmp")
val df4: DataFrame = session.sql(
s"""
|SELECT STRING(age),BOOLEAN(isGraduated),DATE(birthday)
|from tmp
|""".stripMargin)
df4.printSchema()
df4.show(false)
}
}
输出
root
|-- name: string (nullable = true)
|-- age: integer (nullable = false)
|-- birthday: string (nullable = true)
|-- isGraduated: string (nullable = true)
|-- sex: string (nullable = true)
|-- salary: double (nullable = false)
+-------+---+----------+-----------+---+------+
|name |age|birthday |isGraduated|sex|salary|
+-------+---+----------+-----------+---+------+
|James |34 |2006-01-01|true |M |3000.6|
|Michael|33 |1980-01-10|true |F |3300.8|
|Robert |37 |1992-06-01|false |M |5000.5|
+-------+---+----------+-----------+---+------+
1.withColumn---
root
|-- name: string (nullable = true)
|-- age: string (nullable = false)
|-- birthday: date (nullable = true)
|-- isGraduated: boolean (nullable = true)
|-- sex: string (nullable = true)
|-- salary: double (nullable = false)
+-------+---+----------+-----------+---+------+
|name |age|birthday |isGraduated|sex|salary|
+-------+---+----------+-----------+---+------+
|James |34 |2006-01-01|true |M |3000.6|
|Michael|33 |1980-01-10|true |F |3300.8|
|Robert |37 |1992-06-01|false |M |5000.5|
+-------+---+----------+-----------+---+------+
2.selectExpr----
root
|-- age: string (nullable = false)
|-- isGraduated: boolean (nullable = true)
|-- birthday: date (nullable = true)
+---+-----------+----------+
|age|isGraduated|birthday |
+---+-----------+----------+
|34 |true |2006-01-01|
|33 |true |1980-01-10|
|37 |false |1992-06-01|
+---+-----------+----------+
3.sql---
root
|-- age: string (nullable = false)
|-- isGraduated: boolean (nullable = true)
|-- birthday: date (nullable = true)
+---+-----------+----------+
|age|isGraduated|birthday |
+---+-----------+----------+
|34 |true |2006-01-01|
|33 |true |1980-01-10|
|37 |false |1992-06-01|
+---+-----------+----------+
本文写于北京海淀五道口目田青年旅舍,由于疫情原因家被偷(封)了,无家可归
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)