扩充小知识:
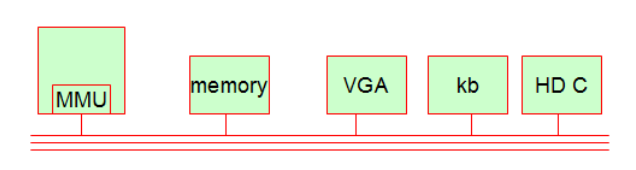
这些硬件设备在一条总线上链接,他们通过这条线进行数据交互,里面的带头大哥就是CPU,拥有最高指挥权。那么它是如何工作的呢?
A.取指单元(从内存中取得指令);
B.解码单元(完成解码[讲内存中取到的数据转换成CPU真正能运行的指令]);
C.执行单元(开始执行指令,根据指令的需求去调用不同的硬件去干活。);
我们通过上面知道了MMU是CPU的一部分,但是CPU有还要其他的部件吗?当然是有的啦,比如指令寄存器芯片,指令计数器芯片,堆栈指针。
指令寄存器芯片:就是CPU用于将内存中的数据取出来存放的地方;
指令计数器芯片:就是CPU为了记录上一次在内存中取数据的位置,方便下一次取值;
堆栈指针:CPU每次取完指令后,就会把堆栈指针指向下一个指令在内存中的位置。
他们的工作周期和CPU是一样快的速度,跟CPU的工作频率是在同一个时钟周期下,因此他的性能是非常好的,在CPU内部总线上完成数据通信。指令寄存器芯片,指令计数器芯片,堆栈指针。这些设备通常都被叫做CPU的寄存器。
寄存器其实就是用于保存现场的。尤其是在时间多路复用尤为明显。比如说CPU要被多个程序共享使用的时候,CPU经常会终止或挂起一个进程,操作系统必须要把它当时的运行状态给保存起来(方便CPU一会回来处理它的时候可以继续接着上次的状态干活。)然后继续运行其他进程(这叫计算机的上下文切换)。
三.计算机的存储体系。
1.对称多处理器SMP
CPU里面除了有MMU和寄存器(接近cpu的工作周期)等等,还有cpu核心,正是专门处理数据的,一颗CPU有多个核心,可以用于并行跑你的代码。工业上很多公司采用多颗CPU,这种结构我们称之为对称多处理器。
2.程序局部性原理
空间局部性:
程序是由指令和数据组成的。空间局部性指的是一个数据被访问到之后,那么离这个数据很近的其他数据随后也可能会被访问到。
时间局部性:
一般而言当一个程序执行完毕后,可能很快会被访问到。数据也是同样的原理,一个数据的被访问到,很可能会再次访问到。
正是因为程序局部性的存在,所以使得无论是在空间局部性或者时间的局部性的角度来考虑,一般而言我们都需要对数据做缓存。
扩充小知识:
由于CPU内部的寄存器存储的空间有限,于是就用了内存来存储数据,但是由于CPU和速度和内存的速度完全不在一个档次上,因此在处理的数据的时候回到多数都在等(CPU要在内存中取一个数据,cpu转一圈的时间就可以处理完,内存可能是需要转20圈)。为了解决使得效率更加提高,就出现了缓存这个概念。
既然我们知道了程序的局部性原理,有知道了CPU为了获得更多的空间其实就是用时间去换空间,但是缓存就是可以直接让cpu拿到数据,节省了时间,所以说缓存就是用空间去换时间
3.就算进存储体系
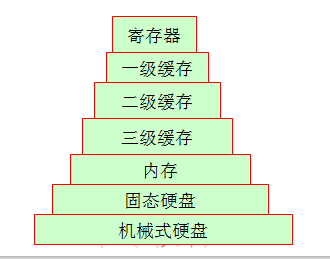
工作时间就的朋友可能见过磁带机,现在基本上都被OUT了,企业很多都用机硬盘来替代磁带机了,所以我们这里就从我们最熟悉的家用电脑的结构来说,存下到上一次存储数据是不一样。我们可以简单举个例子,他们的周存储周期是有很大差距的。尤为明显的是机械硬盘和内存,他们两个存取熟读差距是相当大的。
扩充小知识:
相比自己家用的台式机或是笔记本可能自己拆开过,讲过机械式硬盘,固态硬盘或是内存等等。但是可能你没有见过缓存物理设备,其实他是在CPU上的。因此我们对它的了解可能会有些盲区。
先说说一级缓存和耳机缓存吧,他们的CPU在这里面取数据的时候时间周期基本上查不了多少,因一级缓存和二级缓存都在CPU核心内部资源。(在其他硬件条件相同的情况下。一级缓存128k可能市场价格会买到300元左右,、一级缓存256k可能会买到600元左右,一级缓存512k可能市场价格就得过四位数这个具体价格可以参考京东啊。这足以说明缓存的造价是非常高的!)这个时候你可能会问那三级缓存呢?其实三级缓存就是就是多颗CPU共享的空间。当然多颗cpu也是共享内存的。
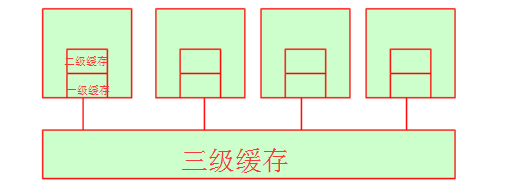
4.非一致性内存访问(NUMA)
我们知道当多颗cpu共享三级缓存或是内存的时候,他们就会出现了一个问题,即资源征用。我们知道变量或是字符串在内存中被保存是有内存地址的。他们是如何去领用内存地址呢?我们可以参考下图:
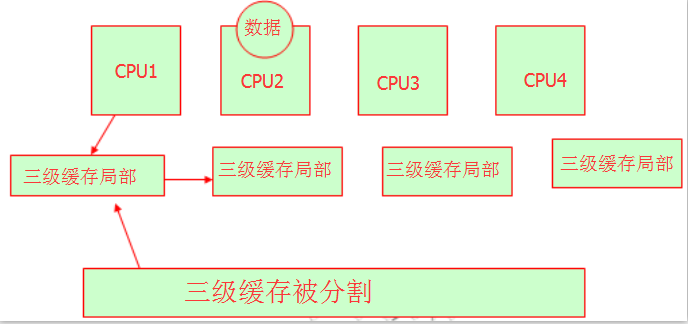
没错,这些玩硬件的大牛们将三级缓存分割,分别让不同的CPU占用不同的内存地址,这样我们可以理解他们都有自己的三级缓存区域,不会存在资源抢夺的问题,但是要注意的是他们还是同一块三级缓存。就好像北京市有朝阳区,丰台区,大兴区,海淀区等等,但是他们都是北京的所属地。我们可以这里理解。这就是NUMA,他的特性就是:非一致性内存访问,都有自己的内存空间。
扩展小知识:
那么问题来了,基于重新负载的结果,如果cpu1运行的进程被挂起,其地址在他自己的它的缓存地址是有记录的,但是当cpu2再次运行这个程序的时候被CPU2拿到的它是如何处理的呢?
这就没法了,只能从CPU1的三级换粗区域中复制一份地址过来一份或是移动过来一份让CPU2来处理,这个时候是需要一定时间的。所以说重新负载均衡会导致CPU性能降低。这个时候我们就可以用进程绑定来实现,让再次处理该进程的时候还是用之前处理的CPU来处理。即进程的CPU的亲缘性。
5.缓存中的通写和回写机制。
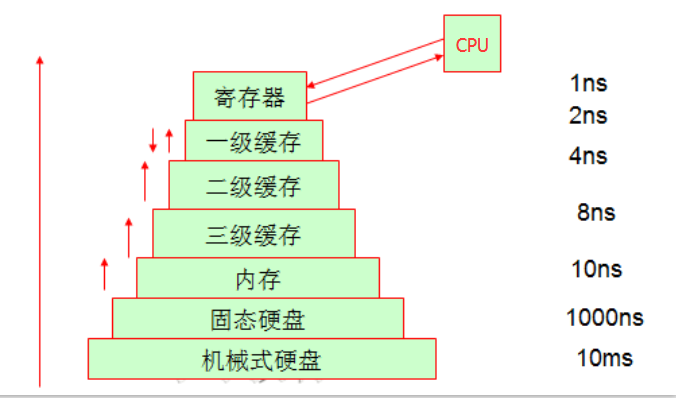
CPU在处理数据的地方就是在寄存器中修改,当寄存器没有要找的数据是,就会去一级缓存找,如果一级缓存中没有数据就会去二级缓存中找,依次查找知道从磁盘中找到,然后在加载到寄存器中。当三级缓存从内存中取数据发现三级缓存不足时,就会自动清理三级缓存的空间。
我们知道数据最终存放的位置是硬盘,这个存取过程是由操作系统来完成的。而我们CPU在处理数据是通过两种写入方式将数据写到不同的地方,那就是通写(写到内存中)和回写(写到一级缓存中)。很显然回写的性能好,但是如果断电的话就尴尬了,数据会丢失,因为他直接写到一级缓存中就完事了,但是一级缓存其他CPU是访问不到的,因此从可靠性的角度上来说通写方式会更靠谱。具体采用哪种方式得你自己按需而定啦。
四.IO设备
1.IO设备由设备控制器和设备本身组成。
设备控制器:集成在主板的一块芯片活一组芯片。负责从操作系统接收命令,并完成命令的执行。比如负责从操作系统中读取数据。
设备本身:其有自己的接口,但是设备本身的接口并不可用,它只是一个物理接口。如IDE接口。
扩展小知识:
每个控制器都有少量的用于通信的寄存器(几个到几十个不等)。这个寄存器是直接集成到设备控制器内部的。比方说,一个最小化的磁盘控制器,它也会用于指定磁盘地址,扇区计数,读写方向等相关操作请求的寄存器。所以任何时候想要激活控制器,设备驱动程序从操作系统中接收操作指令,然后将它转换成对应设备的基本操作,并把操作请求放置在寄存器中才能完成操作的。每个寄存器表现为一个IO端口。所有的寄存器组合称为设备的I/O地址空间,也叫I/O端口空间,
2.驱动程序
真正的硬件操作是由驱动程序操作完成的。驱动程序通常应该由设备生产上完成,通常驱动程序位于内核中,虽然驱动程序可以在内核外运行,但是很少有人这么玩,因为它太低效率啦!
3.实现输入和输出
设备的I/O端口没法事前分配,因为各个主板的型号不一致,所以我们需要做到动态指定。电脑在开机的时候,每个IO设备都要想总线的I/o端口空间注册使用I/O端口。这个动态端口是由所有的寄存器组合成为设备的I/O地址空间,有2^16次方个端口,即65535个端口。
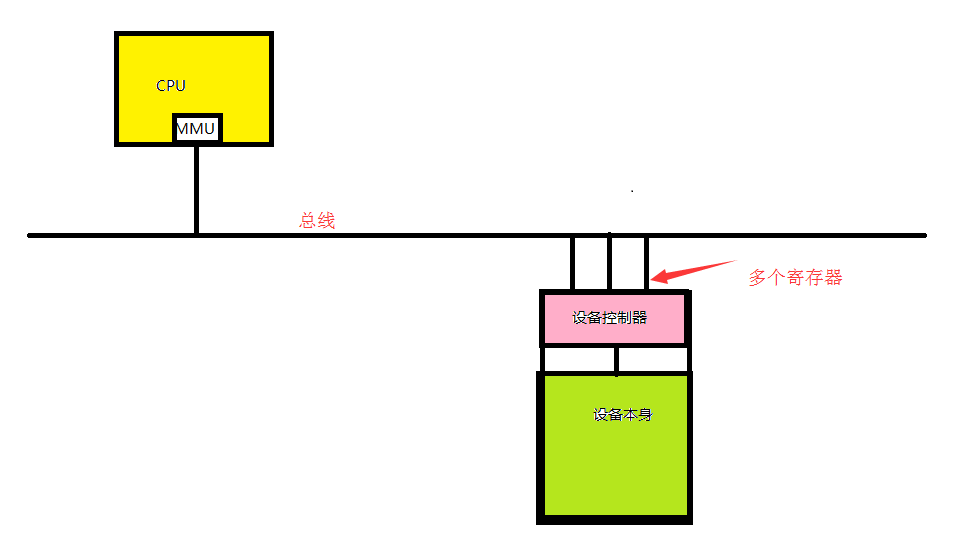
如上图所示,我们的CPU有要想跟指定设备打交道,就需要把指令传给驱动,然后驱动讲CPU的指令转换成设备能理解的信号放在寄存器中(也可以叫套接字,socket).所以说寄存器(I/O端口)是CPU通过总线和设备打交道的地址(I/O端口)。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)