sleuth:英 [slu:θ] 美 [sluθ] n.足迹,警犬,侦探vi.做侦探
微服务架构是一个分布式架构,它按业务划分服务单元,一个分布式系统往往有很多个服务单元。由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很难去定位。主要体现在,一个请求可能需要调用很多个服务,而内部服务的调用复杂性,决定了问题难以定位。所以微服务架构中,必须实现分布式链路追踪,去跟进一个请求到底有哪些服务参与,参与的顺序又是怎样的,从而达到每个请求的步骤清晰可见,出了问题,很快定位。
举几个例子:
1、在微服务系统中,一个来自用户的请求,请求先达到前端A(如前端界面),然后通过远程调用,达到系统的中间件B、C(如负载均衡、网关等),最后达到后端服务D、E,后端经过一系列的业务逻辑计算最后将数据返回给用户。对于这样一个请求,经历了这么多个服务,怎么样将它的请求过程的数据记录下来呢?这就需要用到服务链路追踪。
2、分析微服务系统在大压力下的可用性和性能。
Zipkin可以结合压力测试工具一起使用,分析系统在大压力下的可用性和性能。
设想这么一种情况,如果你的微服务数量逐渐增大,服务间的依赖关系越来越复杂,怎么分析它们之间的调用关系及相互的影响?
spring boot对zipkin的自动配置可以使得所有RequestMapping匹配到的endpoints得到监控,以及强化了RestTemplate,对其加了一层拦截器,使得由它发起的http请求也同样被监控。
Google开源的 Dapper链路追踪组件,并在2010年发表了论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,这篇文章是业内实现链路追踪的标杆和理论基础,具有非常大的参考价值。
目前,链路追踪组件有Google的Dapper,Twitter 的Zipkin,以及阿里的Eagleeye (鹰眼)等,它们都是非常优秀的链路追踪开源组件。
本文主要讲述如何在Spring Cloud Sleuth中集成Zipkin。在Spring Cloud Sleuth中集成Zipkin非常的简单,只需要引入相应的依赖和做相关的配置即可。
一、简介
Spring Cloud Sleuth 主要功能就是在分布式系统中提供追踪解决方案,并且兼容支持了 zipkin,你只需要在pom文件中引入相应的依赖即可。
二、服务追踪分析
微服务架构上通过业务来划分服务的,通过REST调用,对外暴露的一个接口,可能需要很多个服务协同才能完成这个接口功能,如果链路上任何一个服务出现问题或者网络超时,都会形成导致接口调用失败。随着业务的不断扩张,服务之间互相调用会越来越复杂。

随着服务的越来越多,对调用链的分析会越来越复杂。它们之间的调用关系也许如下:

三、术语
Spring Cloud Sleuth采用的是Google的开源项目Dapper的专业术语。
- Span:基本工作单元,例如,在一个新建的span中发送一个RPC等同于发送一个回应请求给RPC,span通过一个64位ID唯一标识,trace以另一个64位ID表示,span还有其他数据信息,比如摘要、时间戳事件、关键值注释(tags)、span的ID、以及进度ID(通常是IP地址)
span在不断的启动和停止,同时记录了时间信息,当你创建了一个span,你必须在未来的某个时刻停止它。
- Trace:一系列spans组成的一个树状结构,例如,如果你正在跑一个分布式大数据工程,你可能需要创建一个trace。
- Annotation:用来及时记录一个事件的存在,一些核心annotations用来定义一个请求的开始和结束
- cs - Client Sent -客户端发起一个请求,这个annotion描述了这个span的开始
- sr - Server Received -服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网络延迟
- ss - Server Sent -注解表明请求处理的完成(当请求返回客户端),如果ss减去sr时间戳便可得到服务端需要的处理请求时间
- cr - Client Received -表明span的结束,客户端成功接收到服务端的回复,如果cr减去cs时间戳便可得到客户端从服务端获取回复的所有所需时间
将Span和Trace在一个系统中使用Zipkin注解的过程图形化:

四、sleuth与Zipkin关系?
spring cloud提供了spring-cloud-sleuth-zipkin来方便集成zipkin实现(指的是Zipkin Client,而不是Zipkin服务器),该jar包可以通过spring-cloud-starter-zipkin依赖来引入。
五、Zipkin
Zipkin是什么
Zipkin分布式跟踪系统;它可以帮助收集时间数据,解决在microservice架构下的延迟问题;它管理这些数据的收集和查找;Zipkin的设计是基于谷歌的Google Dapper论文。
每个应用程序向Zipkin报告定时数据,Zipkin UI呈现了一个依赖图表来展示多少跟踪请求经过了每个应用程序;如果想解决延迟问题,可以过滤或者排序所有的跟踪请求,并且可以查看每个跟踪请求占总跟踪时间的百分比。
为什么使用Zipkin
随着业务越来越复杂,系统也随之进行各种拆分,特别是随着微服务架构和容器技术的兴起,看似简单的一个应用,后台可能有几十个甚至几百个服务在支撑;一个前端的请求可能需要多次的服务调用最后才能完成;当请求变慢或者不可用时,我们无法得知是哪个后台服务引起的,这时就需要解决如何快速定位服务故障点,Zipkin分布式跟踪系统就能很好的解决这样的问题。
Zipkin原理
针对服务化应用全链路追踪的问题,Google发表了Dapper论文,介绍了他们如何进行服务追踪分析。其基本思路是在服务调用的请求和响应中加入ID,标明上下游请求的关系。利用这些信息,可以可视化地分析服务调用链路和服务间的依赖关系。
对应Dpper的开源实现是Zipkin,支持多种语言包括JavaScript,Python,Java, Scala, Ruby, C#, Go等。其中Java由多种不同的库来支持
Spring Cloud Sleuth是对Zipkin的一个封装,对于Span、Trace等信息的生成、接入HTTP Request,以及向Zipkin Server发送采集信息等全部自动完成。Spring Cloud Sleuth的概念图见上图。
Zipkin架构
跟踪器(Tracer)位于你的应用程序中,并记录发生的操作的时间和元数据,提供了相应的类库,对用户的使用来说是透明的,收集的跟踪数据称为Span;将数据发送到Zipkin的仪器化应用程序中的组件称为Reporter,Reporter通过几种传输方式之一将追踪数据发送到Zipkin收集器(collector),然后将跟踪数据进行存储(storage),由API查询存储以向UI提供数据。
架构图如下:
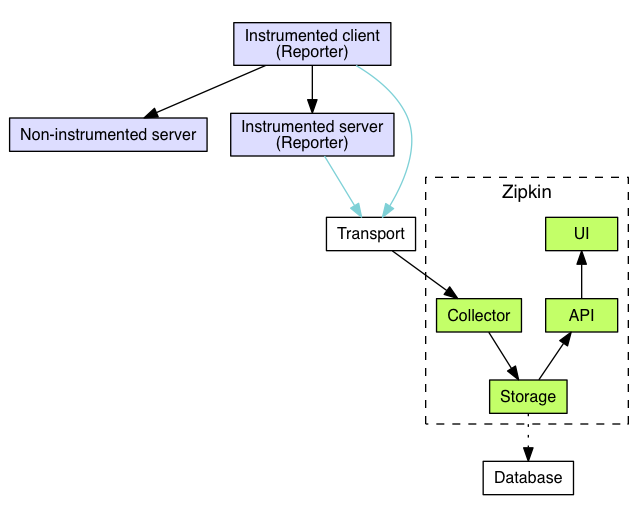
1.Trace
Zipkin使用Trace结构表示对一次请求的跟踪,一次请求可能由后台的若干服务负责处理,每个服务的处理是一个Span,Span之间有依赖关系,Trace就是树结构的Span集合;
2.Span
每个服务的处理跟踪是一个Span,可以理解为一个基本的工作单元,包含了一些描述信息:id,parentId,name,timestamp,duration,annotations等,例如:
{
"traceId": "bd7a977555f6b982",
"name": "get-traces",
"id": "ebf33e1a81dc6f71",
"parentId": "bd7a977555f6b982",
"timestamp": 1458702548478000,
"duration": 354374,
"annotations": [
{
"endpoint": {
"serviceName": "zipkin-query",
"ipv4": "192.168.1.2",
"port": 9411
},
"timestamp": 1458702548786000,
"value": "cs"
}
],
"binaryAnnotations": [
{
"key": "lc",
"value": "JDBCSpanStore",
"endpoint": {
"serviceName": "zipkin-query",
"ipv4": "192.168.1.2",
"port": 9411
}
}
]
}
traceId:标记一次请求的跟踪,相关的Spans都有相同的traceId;
id:span id;
name:span的名称,一般是接口方法的名称;
parentId:可选的id,当前Span的父Span id,通过parentId来保证Span之间的依赖关系,如果没有parentId,表示当前Span为根Span;
timestamp:Span创建时的时间戳,使用的单位是微秒(而不是毫秒),所有时间戳都有错误,包括主机之间的时钟偏差以及时间服务重新设置时钟的可能性,出于这个原因,Span应尽可能记录其duration;
duration:持续时间使用的单位是微秒(而不是毫秒);
annotations:注释用于及时记录事件;有一组核心注释用于定义RPC请求的开始和结束;
cs:Client Send,客户端发起请求;
sr:Server Receive,服务器接受请求,开始处理;
ss:Server Send,服务器完成处理,给客户端应答;
cr:Client Receive,客户端接受应答从服务器;
binaryAnnotations:二进制注释,旨在提供有关RPC的额外信息。
3.Transport
收集的Spans必须从被追踪的服务运输到Zipkin collector,有三个主要的传输方式:HTTP, Kafka和Scribe;
4.Components
有4个组件组成Zipkin:collector,storage,search,web UI
collector:一旦跟踪数据到达Zipkin collector守护进程,它将被验证,存储和索引,以供Zipkin收集器查找;
storage:Zipkin最初数据存储在Cassandra上,因为Cassandra是可扩展的,具有灵活的模式,并在Twitter中大量使用;但是这个组件可插入,除了Cassandra之外,还支持ElasticSearch和MySQL; 存储,zipkin默认的存储方式为in-memory,即不会进行持久化操作。如果想进行收集数据的持久化,可以存储数据在Cassandra,因为Cassandra是可扩展的,有一个灵活的模式,并且在Twitter中被大量使用,我们使这个组件可插入。除了Cassandra,我们原生支持ElasticSearch和MySQL。其他后端可能作为第三方扩展提供。
search:一旦数据被存储和索引,我们需要一种方法来提取它。查询守护进程提供了一个简单的JSON API来查找和检索跟踪,主要给Web UI使用;
web UI:创建了一个GUI,为查看痕迹提供了一个很好的界面;Web UI提供了一种基于服务,时间和注释查看跟踪的方法。
Zipkin下载和启动
有三种安装方法:
Zipkin的使用比较简单,官网有说明几种方式:
1、容器
Docker Zipkin项目能够建立docker镜像,提供脚本和docker-compose.yml来启动预构建的图像。最快的开始是直接运行最新镜像:
docker run -d -p 9411:9411 openzipkin/zipkin
2、下载jar
如果你有java 8或更高版本,上手最快的方法是把新版本作为一个独立的可执行jar,Zipkin使用springboot来构建的:
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar
3、下载源代码运行
Zipkin可以从源运行,如果你正在开发新的功能。要实现这一点,需要获取Zipkin的源代码并构建它。
# get the latest source
git clone https://github.com/openzipkin/zipkin
cd zipkin
# Build the server and also make its dependencies
./mvnw -DskipTests --also-make -pl zipkin-server clean install
# Run the server
java -jar ./zipkin-server/target/zipkin-server-*exec.jar
1、使用官网自己打包好的Jar运行,Docker方式或下载源代码自己打包Jar运行(因为zipkin使用了springboot,内置了服务器,所以可以直接使用jar运行)。zipkin推荐使用docker方式运行,我后面会专门写一遍关于docker的运行方式,而源码运行方式好处是有机会体验到最新的功能特性,但是可能也会带来一些比较诡异的坑,所以不做讲解,下面我直接是使用官网打包的jar运行过程:
官方提供了三种方式来启动,这里使用第二种方式来启动;
wget -O zipkin.jar 'https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec'
java -jar zipkin.jar
首先下载zipkin.jar,我下载的是zipkin-server-2.10.2-exec.jar,然后直接使用-jar命令运行,要求jdk8以上版本;
D:\workspace\zipkin>java -jar zipkin-server-2.10.2-exec.jar
********
** **
* *
** **
** **
** **
** **
********
****
****
**** ****
****** **** ***
*********


