虚函数的地址存放于虚函数表之中。运行期多态就是通过虚函数和虚函数表实现的。
类的对象内部会有指向类内部的虚表地址的指针。通过这个指针调用虚函数。
虚函数的调用会被编译器转换为对虚函数表的访问:
ptr->f();
*(ptr->vptr[1])(ptr);
上述代码中,ptr代表一个this指针,ptr指向的vptr是类内部的虚表指针。这个虚表指针会被放在类的最前方(VS2017),1就是虚函数指针在虚函数表中的索引值。在这个索引值表示的虚表的槽中存放的就是f()的地址。
虚表指针的名字也会被编译器更改,所以在多继承的情况下,类的内部可能存在多个虚表指针。通过不同的名字被编译器标识。
虚函数表中可能还存在其他的内容,如用于RTTI的type_info类型。或者直接将虚基类的指针存放在虚表中。
压制多态可以通过域操作符进行。
class A1
{
public:
virtual void f() { cout << "A1::f" << endl; }
};
class C : public A1
{
public:
virtual void f() { cout << "C::f" << endl; }
};
c.A1::f();
c.f();
单继承
这种情况下,派生类中仅有一个虚函数表。这个虚函数表和基类的虚函数表不是一个表(无论派生类有没有重写基类的虚函数),但是如果派生类没有重写基类的虚函数的话,基类和派生类的虚函数表指向的函数地址都是相同的。
class A1
{
public:
A1(int _a1 = 1) : a1(_a1) { }
virtual void f() { cout << "A1::f" << endl; }
virtual void g() { cout << "A1::g" << endl; }
virtual void h() { cout << "A1::h" << endl; }
~A1() {}
private:
int a1;
};
class C : public A1
{
public:
C(int _a1 = 1, int _c = 4) :A1(_a1), c(_c) { }
private:
int c;
};
类C没有重写A的虚函数,所以虚函数表内部的情况如下:
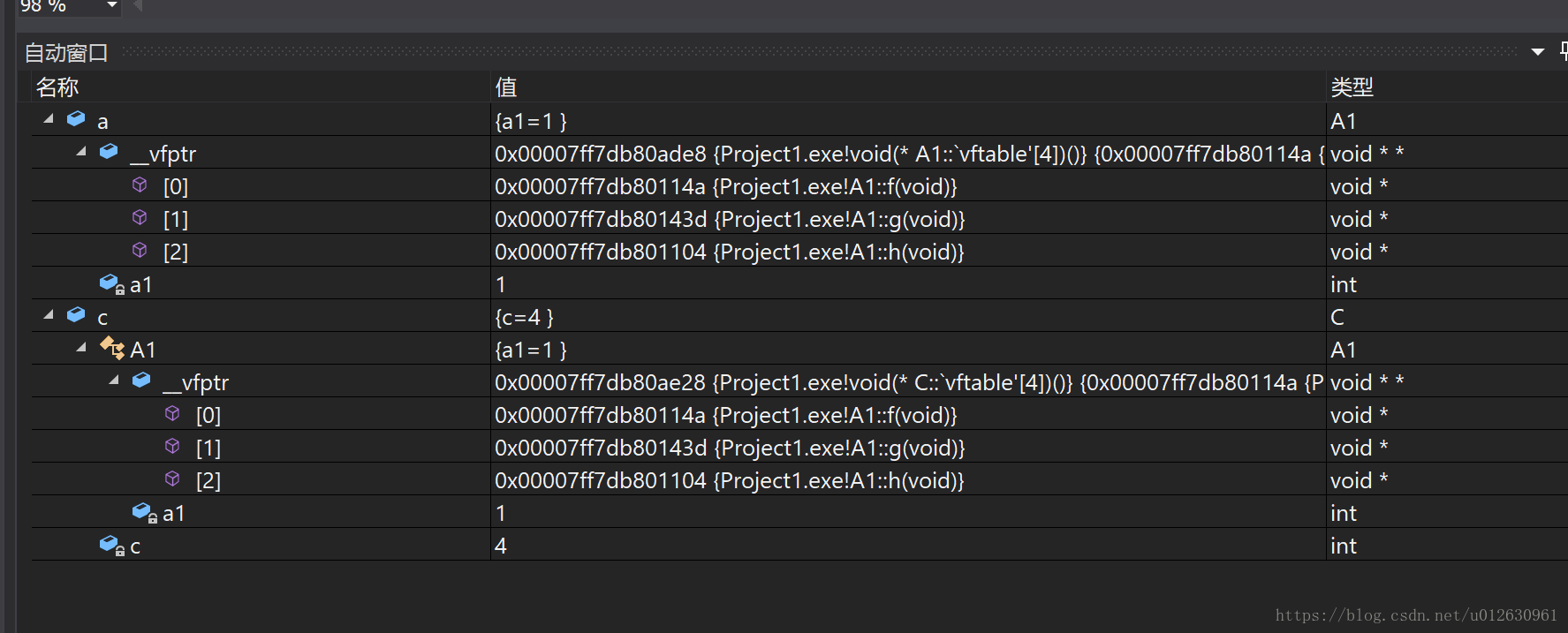
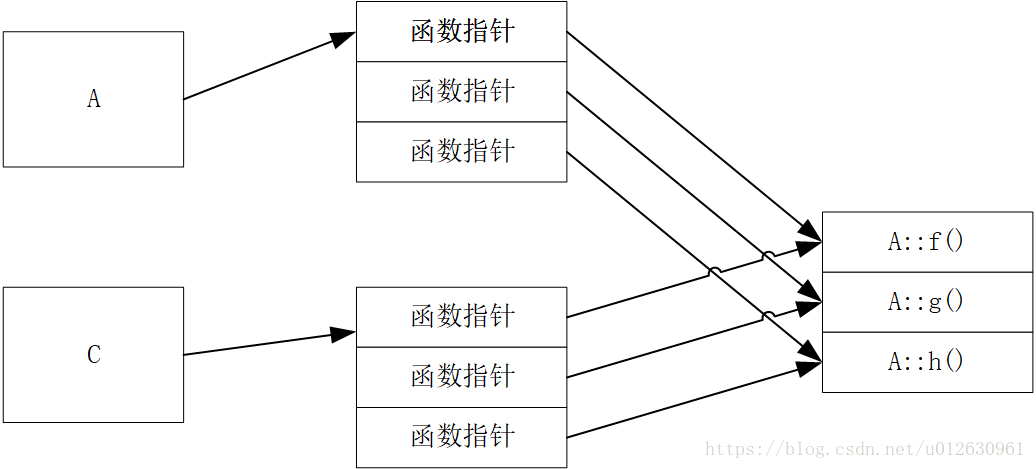
可以看出,两个类的__vfptr的值不同,但是每个槽内部的函数地址都是相同的。
如果类C中重写了A类中的函数:
class C : public A1
{
public:
C(int _a1 = 1, int _c = 4) :A1(_a1), c(_c) { }
virtual void f() { cout << "C::f" << endl; }
virtual void g() { cout << "C::g" << endl; }
virtual void h() { cout << "C::h" << endl; }
private:
int c;
};
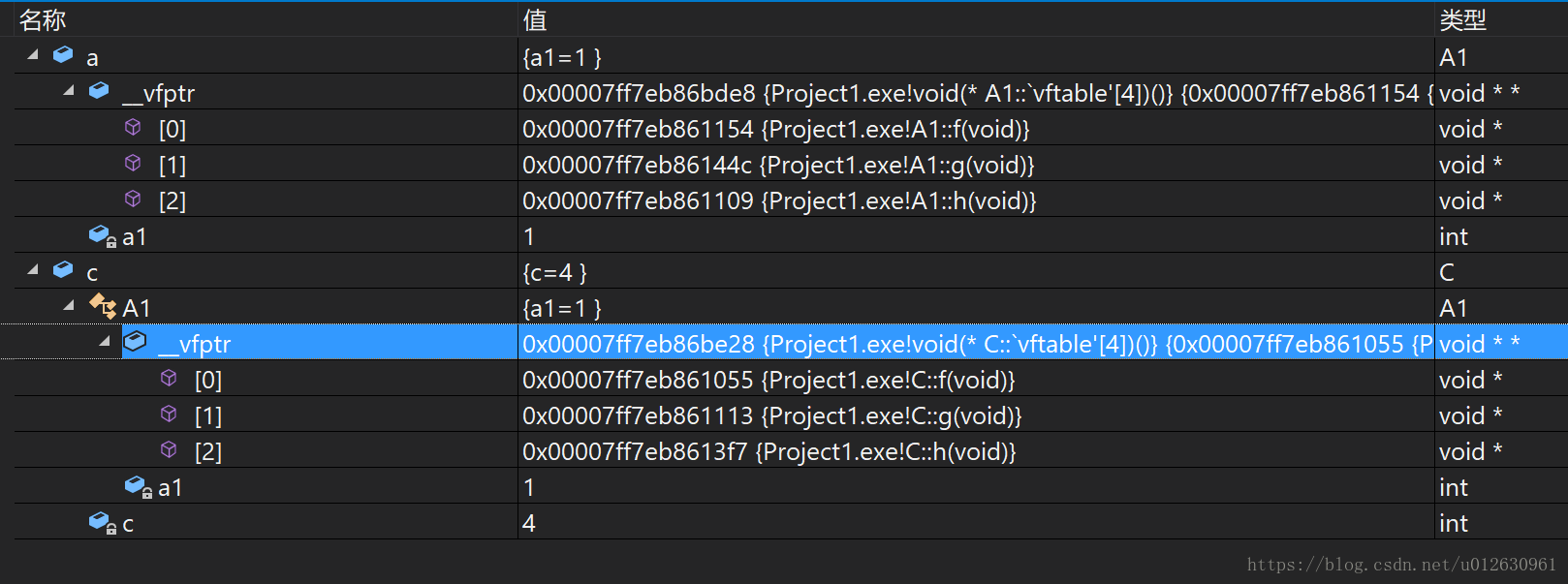
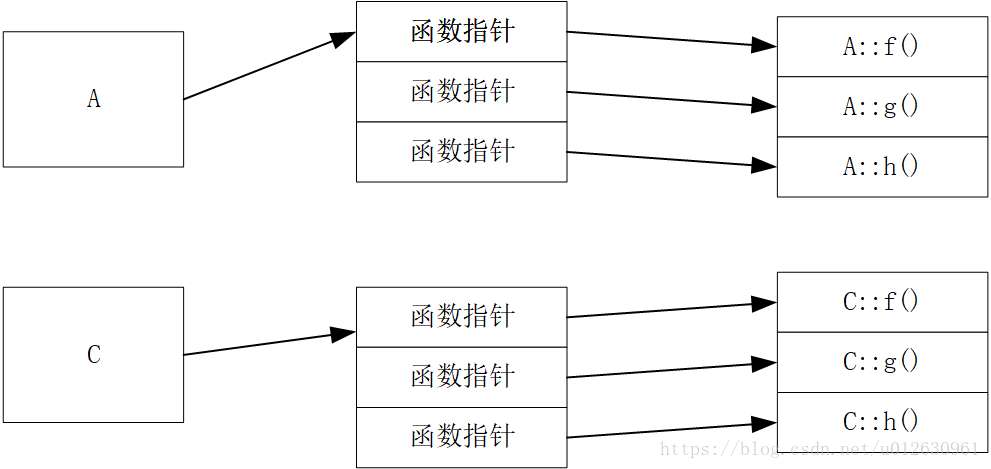
那么就会覆盖A类的虚函数,重写一部分就会覆盖一部分,重写全部就会覆盖全部。
如果C中重新写了一些别的虚函数,那么这些虚函数将排在父类的后面,这里编译器无法显示,可以通过打印虚表来进行。
打印的过程比较简单,通过访问类C的前8字节(64位编译器)找到虚函数表,再一次遍历虚函数表即可。虚函数表最后一项用的是0,代表虚函数表结束。
C c;
long long *p = (long long *)(*(long long*)&c);
typedef void(*FUNC)();
void PrintVTable(long long* vTable)
{
if (vTable == NULL)
{
return;
}
cout << "vtbl:" << vTable << endl;
int i = 0;
for (; vTable[i] != 0; ++i)
{
printf("function : %d :0X%x->", i, vTable[i]);
FUNC f = (FUNC)vTable[i];
f();
}
cout << endl;
}
通过这样的打印可以得知C的虚函数表为:
vtbl:00007FF6CD2CBE68
function : 0 :0Xcd2c115e->A1::f
function : 1 :0Xcd2c146a->A1::g
function : 2 :0Xcd2c1113->A1::h
vtbl:00007FF6CD2CBEA8
function : 0 :0Xcd2c115e->A1::f
function : 1 :0Xcd2c146a->A1::g
function : 2 :0Xcd2c1113->A1::h
function : 3 :0Xcd2c1023->C::f
function : 4 :0Xcd2c132a->C::g
function : 5 :0Xcd2c11d1->C::h
具体的图解为:
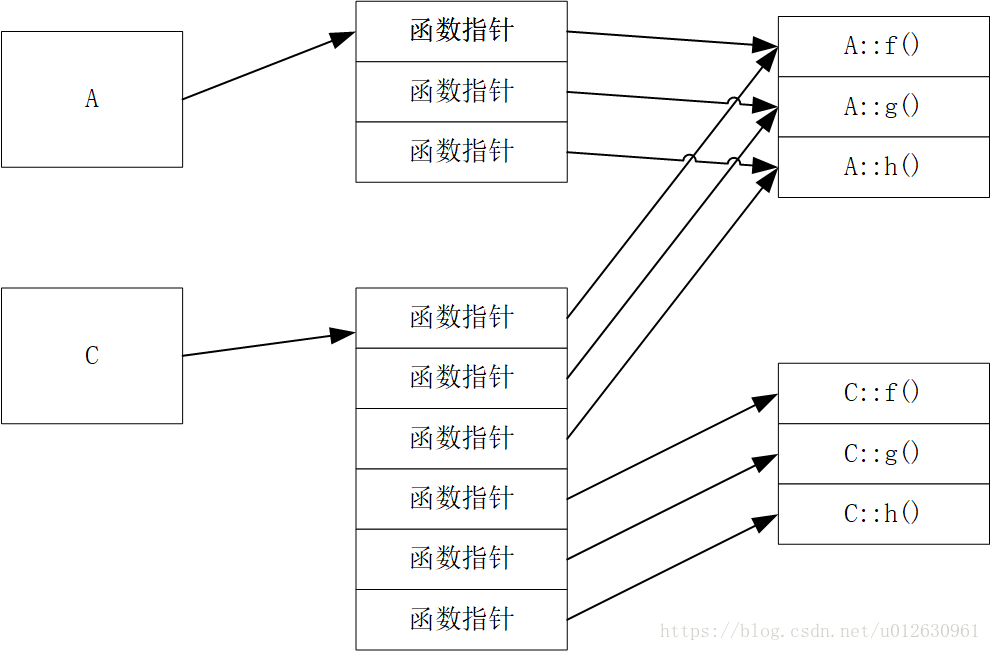
多继承
多继承情况下,派生类中有多个虚函数表,虚函数的排列方式和继承的顺序一致。派生类重写函数将会覆盖所有虚函数表的同名内容,派生类自定义新的虚函数将会在第一个类的虚函数表的后面进行扩充。
class A1
{
public:
A1(int _a1 = 1) : a1(_a1) { }
virtual void f() { cout << "A1::f" << endl; }
virtual void g() { cout << "A1::g" << endl; }
virtual void h() { cout << "A1::h" << endl; }
~A1() {}
private:
int a1;
};
class A2
{
public:
A2(int _a2 = 2) : a2(_a2) { }
virtual void f() { cout << "A2::f" << endl; }
virtual void g() { cout << "A2::g" << endl; }
virtual void h() { cout << "A2::h" << endl; }
~A2() {}
private:
int a2;
};
class A3
{
public:
A3(int _a3 = 3) : a3(_a3) { }
virtual void f() { cout << "A3::f" << endl; }
virtual void g() { cout << "A3::g" << endl; }
virtual void h() { cout << "A3::h" << endl; }
~A3() {}
private:
int a3;
};
class B : public A1, public A2, public A3
{
public:
B(int _a1 = 1, int _a2 = 2, int _a3 = 3, int _b = 4) :A1(_a1), A2(_a2), A3(_a3), b(_b) { }
virtual void f1(){ cout << "B::f" << endl; }
virtual void g1(){ cout << "B::g" << endl; }
virtual void h1(){ cout << "B::h" << endl; }
private:
int b;
};
这里通过编译器的部分可以看出来,未被重写的虚函数指针将和基类指向同一个位置,一旦被重写,函数指针就指向新的位置。
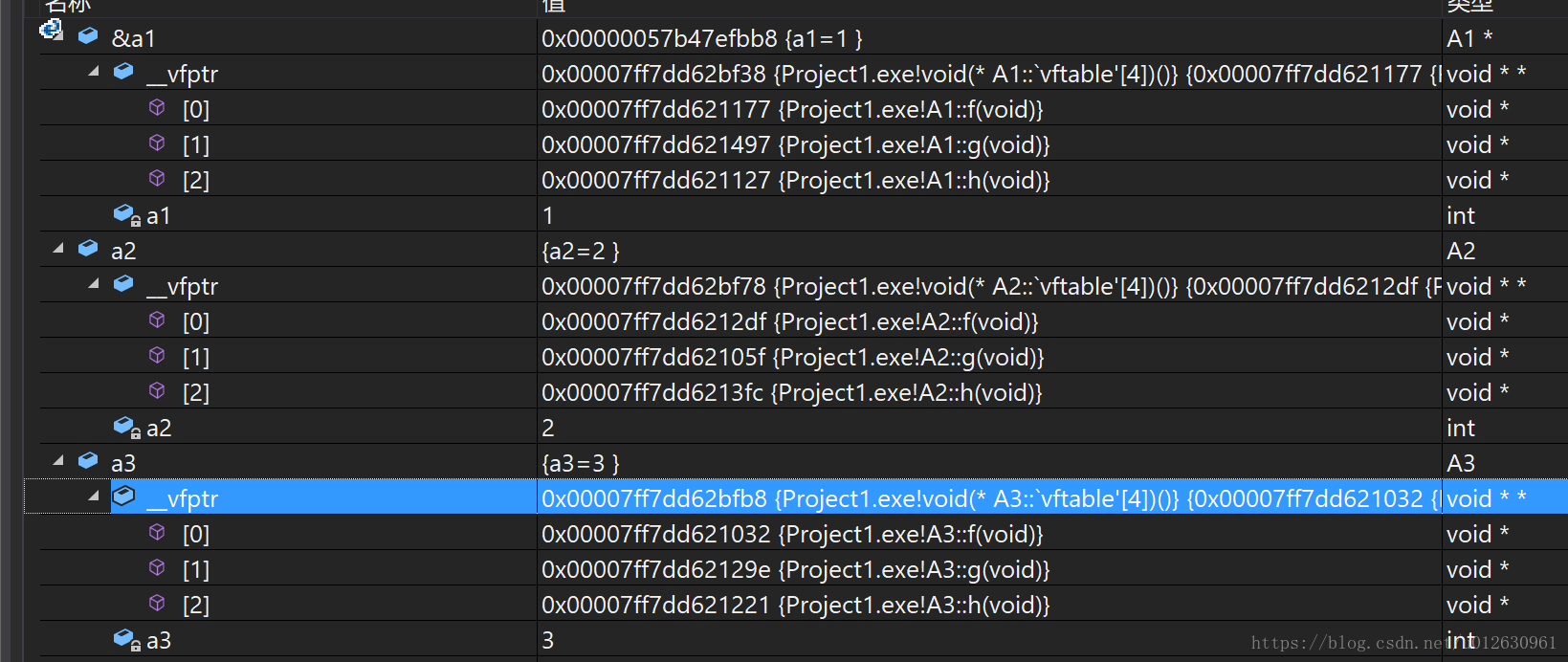
在B类中,函数指针指向的位置不变:
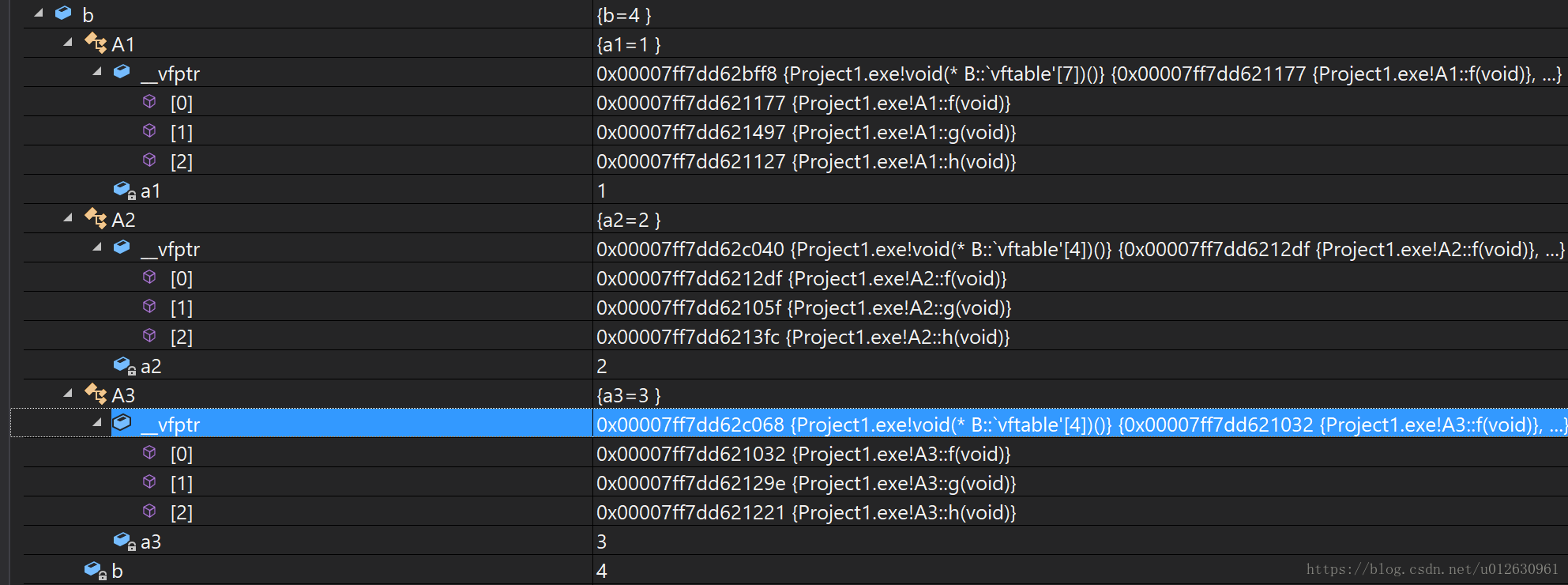
而这时候B类中第一个虚函数表已经增加了新的项,从打印结果可知。
vtbl:00007FF7DD62BF38
function : 0 :0Xdd621177->A1::f
function : 1 :0Xdd621497->A1::g
function : 2 :0Xdd621127->A1::h
vtbl:00007FF7DD62BF78
function : 0 :0Xdd6212df->A2::f
function : 1 :0Xdd62105f->A2::g
function : 2 :0Xdd6213fc->A2::h
vtbl:00007FF7DD62BFB8
function : 0 :0Xdd621032->A3::f
function : 1 :0Xdd62129e->A3::g
function : 2 :0Xdd621221->A3::h
vtbl:00007FF7DD62BFF8
function : 0 :0Xdd621177->A1::f
function : 1 :0Xdd621497->A1::g
function : 2 :0Xdd621127->A1::h
function : 3 :0Xdd62144c->B::f
function : 4 :0Xdd621019->B::g
function : 5 :0Xdd62133e->B::h
而如果B类重写了函数,那么打印结果将是:
vtbl:00007FF720C8BF38
function : 0 :0X20c8117c->A1::f
function : 1 :0X20c814b5->A1::g
function : 2 :0X20c8112c->A1::h
vtbl:00007FF720C8BF78
function : 0 :0X20c812f8->A2::f
function : 1 :0X20c8105a->A2::g
function : 2 :0X20c8141a->A2::h
vtbl:00007FF720C8BFB8
function : 0 :0X20c8102d->A3::f
function : 1 :0X20c812b2->A3::g
function : 2 :0X20c81230->A3::h
vtbl:00007FF720C8BFF8
function : 0 :0X20c814ab->B::f
function : 1 :0X20c81370->B::g
function : 2 :0X20c81393->B::h
并且此时B类的信息为:
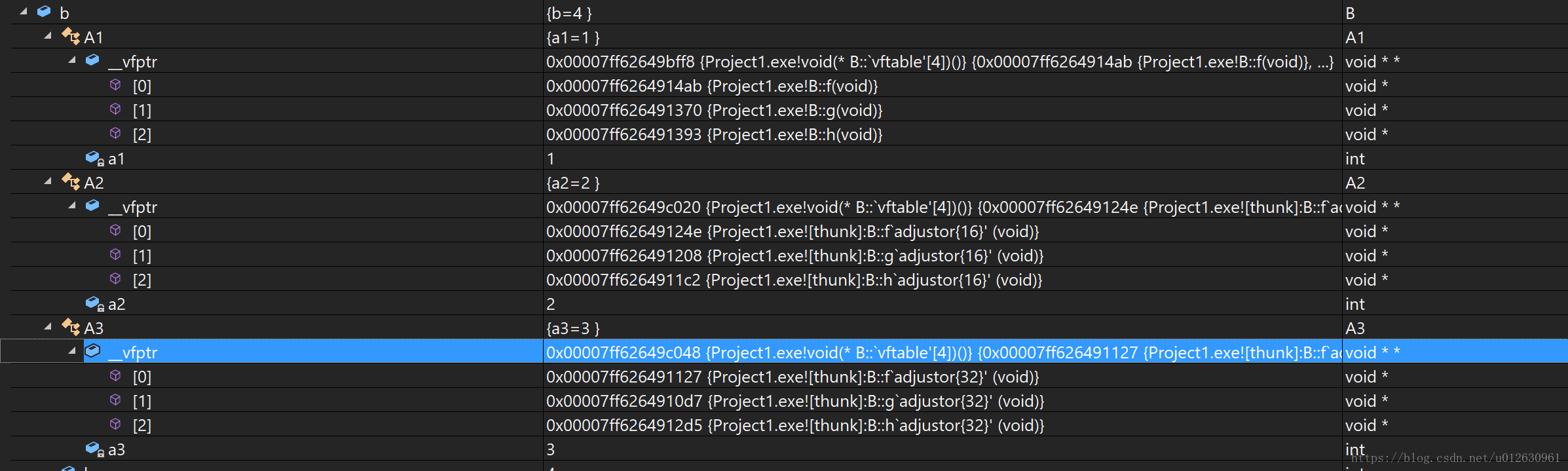
从编译器给出的信息我们可以看到在第二个虚函数表中有adjustor{16}的字样,这就是A类的大小,也就是说,这就是告诉编译器,需要进行16字节的偏移(thunk技术)。这就引出了接下来的一个问题:
B类用不同的基类指针指向的时候,运行的是不同的基类中的虚函数(这就是多态的表现),这里可以知道,当A2类指针指向B的时候,虚函数指针是自动跳到B类中A2类所在的地方的,这个跳转是怎么进行的呢?
首先在编译期,就可以知道一个指针需要偏移多少个字节:
A2 *p = new B;
编译器会将这个代码改为:
B *tmp = new B;
A2 *p = tmp ? tmp + sizoef(A1) : 0;
经过这样的调整A1,A2,A3都会指向正确的类的位置。但是这样还不够。
由上面的编译器信息图我们可以知道,当B类重写了函数之后,A2,A3的虚函数表所指对象已经不再是简单的函数指针了,而是一个thunk对象。这就是C++的thunk技术。
所谓的thunk就是一段汇编代码,这段汇编代码可以以适当的偏移值来调整this指针以跳到对应的虚函数中去,并调用这个函数,也就是说当使用A1的指针指向B的对象,不需要发生偏移,而使用A2的指针指向B则需要进行偏移sizeof(A1)个字节。并跳转到A1中的函数来执行。这就是通过thunk的jmp指令跳转到这个函数。
所以具体的虚函数表中的情况如下:
- 如果两个基类中的虚函数名字不同,派生类只重写了第二个基类的虚函数,则不会产生thunk用以跳转。
- 如果基类中虚函数名字相同,派生类如果重写,将会一次性重写两个基类的虚函数,这时候第二个基类的虚函数表中存放的就是thunk对象,当指针指向此处的时候,会自动跳转到A类的对应虚函数(已经被B重写)执行。
- 第一个基类的虚函数被重写与否都不会产生thunk对象,因为这个类是被别的基类指针跳转的目标,而这个类的指针施行多态的时候是不会发生跳转的。
- 派生类的重新定义的虚函数将会排在第一个虚函数表内部A1虚函数的后面,但是当A2调用这个函数的时候,会通过thunk技术跳转回第一个类的虚函数表以执行相对应的虚函数。
- 除了第一个基类的虚析构函数,其他基类的析构函数都是thunk对象。
综上所述,thunk对象用于所有基类都被派生类重写后,调用虚函数将跳到最开始的基类部分。或者派生类中定义的虚函数也会跳转到第一个基类的虚函数表中。而仅出现在后面的基类的虚函数表中的虚函数,无论被重写与否都不会产生thunk对象。因为这里不会在第一个基类中由对应的虚函数指针。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)