目录
1.scrapy是什么?
2.安装scrapy
3. scrapy项目的创建以及运行
(1)创建scrapy项目:
(2)项目组成:
(3)创建爬虫文件:
①跳转到spiders文件夹中去创建爬虫文件
②scrapy genspider爬虫文件的名字 网页的域名
(4)爬虫文件的基本组成:
(5)运行爬虫文件:
(6)实例
①百度
②58同城
③汽车之家
4.scrapy架构组成
(1)引擎
(2)下载器
(3)spiders
(4)调度器
(5)管道(Item pipeline)
5.scrapy工作原理
6.日志信息和日志等级
(1)日志级别:
(2)settings.py文件设置:
7.scrapy的post请求
(1)重写start_requests方法:
(2)start_requests的返回值:
8.代理
(1)到settings.py中,打开一个选项
(2)到middlewares.py中写代码
1.scrapy是什么?
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理 或存储历史数据等一系列的程序中。
2.安装scrapy
pip install scrapy
安装过程中出错:
如果安装有错误!!!!
pip install Scrapy
building 'twisted.test.raiser' extension
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual‐cpp‐build‐tools
解决方案:
http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
下载twisted对应版本的whl文件(如我的Twisted‐17.5.0‐cp36‐cp36m‐win_amd64.whl),cp后面是 python版本,amd64代表64位,运行命令:
pip install C:\Users\...\Twisted‐17.5.0‐cp36‐cp36m‐win_amd64.whl
pip install Scrapy
如果再报错
python ‐m pip install ‐‐upgrade pip
如果再报错 win32
解决方法:
pip install pypiwin32
再报错:使用anaconda
使用步骤:
打开anaconda
点击environments
点击not installed
输入scrapy apply
在pycharm中选择anaconda的环境
3. scrapy项目的创建以及运行
(1)创建scrapy项目:
终端输入 scrapy startproject 项目名称
注意:项目的名字不允许使用数字开头 也不能包含中文
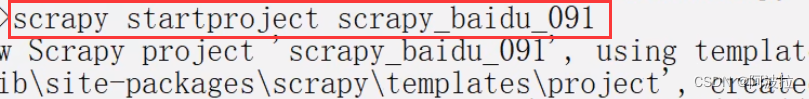
(2)项目组成:
项目名字
项目名字
spiders(存储的是爬虫文件)
__init__.py
自定义的爬虫文件.py ‐‐‐》由我们自己创建,是实现爬虫核心功能的文件 __init__.py
items.py ‐‐‐》定义数据结构的地方,爬取的数据都包含哪些,是一
个继承自scrapy.Item的类
middlewares.py ‐‐‐》中间件 代理
pipelines.py ‐‐‐》管道文件,里面只有一个类,用于处理下载数据的后
续处理默认是300优先级,值越小优先级越高(1‐1000)
settings.py ‐‐‐》配置文件 比如:是否遵守robots协议,User‐Agent
定义等

(3)创建爬虫文件:
①跳转到spiders文件夹中去创建爬虫文件
cd 目录名字/目录名字/spiders
例如:cd scrapy_baidu_091\scrapy_baidu_091\spiders

②scrapy genspider爬虫文件的名字 网页的域名
scrapy genspider 爬虫文件的名字 网页的域名
例如:scrapy genspider baidu http://www.baidu.com
注:一般情况下不需要添加http协议 因为start_urls的值是根据allowed_domains修改的 所以添加了http的话 那么start_urls就需要我们手动去修改了

(4)爬虫文件的基本组成:
继承scrapy.Spider类
name = 'baidu' ‐‐‐》 运行爬虫文件时使用的名字
allowed_domains ‐‐‐》 爬虫允许的域名,在爬取的时候,如果不是此域名之下的 url,会被过滤掉
start_urls ‐‐‐》 声明了爬虫的起始地址,可以写多个url,一般是一个
parse(self, response) ‐‐‐》解析数据的回调函数
response.text ‐‐‐》响应的是字符串
response.body ‐‐‐》响应的是二进制文件
response.xpath() ‐‐‐》xpath方法的返回值类型是selector列表
可以直接是xpath方法来解析response中的内容
extract() ‐‐‐》提取的是selector对象的是data
extract_first() ‐‐‐》提取的是selector列表中的第一个数据
(5)运行爬虫文件:
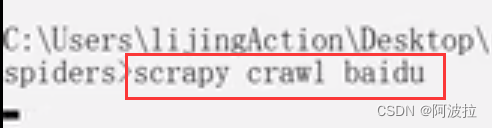
scrapy crawl 爬虫名称
例如: scrapy crawl baidu
注意:应在spiders文件夹内执行
(6)实例
①百度
import scrapy
class BaiduSpider(scrapy.Spider):
# 爬虫的名字 用于运行爬虫的时候 使用的值
name = 'baidu'
# 允许访问的域名
allowed_domains = ['http://www.baidu.com']
# 起始的url地址 指的是第一次要访问的域名
# start_urls 是在allowed_domains的前面添加一个http://
# 在 allowed_domains的后面添加一个/
start_urls = ['http://www.baidu.com/']
# 是执行了start_urls之后 执行的方法 方法中的response 就是返回的那个对象
# 相当于 response = urllib.request.urlopen()
# response = requests.get()
def parse(self, response):
print('苍茫的天涯是我的爱')
②58同城
import scrapy
class TcSpider(scrapy.Spider):
name = 'tc'
allowed_domains = ['https://bj.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91']
start_urls = ['https://bj.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91']
def parse(self, response):
# 字符串
# content = response.text
# 二进制数据
# content = response.body
# print('===========================')
# print(content)
span = response.xpath('//div[@id="filter"]/div[@class="tabs"]/a/span')[0]
print('=======================')
print(span.extract())
③汽车之家
import scrapy
class CarSpider(scrapy.Spider):
name = 'car'
allowed_domains = ['https://car.autohome.com.cn/price/brand-15.html']
# 注意如果你的请求的接口是html为结尾的 那么是不需要加/的
start_urls = ['https://car.autohome.com.cn/price/brand-15.html']
def parse(self, response):
name_list = response.xpath('//div[@class="main-title"]/a/text()')
price_list = response.xpath('//div[@class="main-lever"]//span/span/text()')
for i in range(len(name_list)):
name = name_list[i].extract()
price = price_list[i].extract()
print(name,price)
4.scrapy架构组成
(1)引擎
‐‐‐》自动运行,无需关注,会自动组织所有的请求对象,分发给下载器。
(2)下载器
‐‐‐》从引擎处获取到请求对象后,请求数据。
(3)spiders
‐‐‐》Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例 如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及 分析某个网页(或者是有些网页)的地方。
(4)调度器
‐‐‐》有自己的调度规则,无需关注。
(5)管道(Item pipeline)
‐‐‐》最终处理数据的管道,会预留接口供我们处理数据。
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。 每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方法的Python类。他们接收到Item并通过它执行 一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。 以下是item pipeline的一些典型应用:
- 清理HTML数据
- 验证爬取的数据(检查item包含某些字段)
- 查重(并丢弃)
- 将爬取结果保存到数据库中
5.scrapy工作原理


6.日志信息和日志等级
(1)日志级别:
CRITICAL:严重错误
ERROR: 一般错误
WARNING: 警告
INFO: 一般信息
DEBUG: 调试信息
默认的日志等级是DEBUG
只要出现了DEBUG或者DEBUG以上等级的日志
那么这些日志将会打印
(2)settings.py文件设置:
默认的级别为DEBUG,会显示上面所有的信息
在配置文件中 settings.py
LOG_FILE : 将屏幕显示的信息全部记录到文件中,屏幕不再显示,注意文件后缀一定是.log
LOG_LEVEL : 设置日志显示的等级,就是显示哪些,不显示哪些
7.scrapy的post请求
(1)重写start_requests方法:
def start_requests(self)
(2)start_requests的返回值:
scrapy.FormRequest(url=url, headers=headers, callback=self.parse_item, formdata=data)
url: 要发送的post地址
headers:可以定制头信息
callback: 回调函数
formdata: post所携带的数据,这是一个字典
8.代理
(1)到settings.py中,打开一个选项
DOWNLOADER_MIDDLEWARES = {
'postproject.middlewares.Proxy': 543,
}
(2)到middlewares.py中写代码
def process_request(self, request, spider):
request.meta['proxy'] = 'https://113.68.202.10:9999'
return None