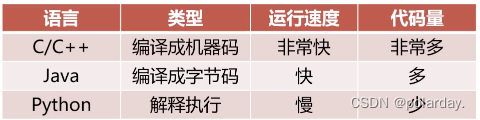
简介
运行效率较低
- 单行注释:以#开头:#注释内容
- 多行注释:以一对三个双引号引起来的内容: “”“注释内容”“”
数据类型
type(被查看类型的数据):查看数据类型
数字(Number)
整数(int)
Python可以处理任意大小的整数
- 二进制整数使用前缀
0b表示,例如:0b110,0b1100
- 十六进制整数使用前缀
0x表示,例如:0x12ef,0xde2431af
浮点数(float)
浮点数可以用正常写法:1.23,3.14,-9.01
也可以使用科学计数法表示:1.23e9(1.23*10^9)
注意:浮点数的运算可能会有误差

复数(complex)
以j结尾表示复数,如4+3j
布尔值(bool)
布尔值只有True,False两种值,可以使用and,or,not进行运算
True本质上是一个数字记作1,False记作0
字符串(String)
描述文本的一种数据类型
字符串可以用’'或""括起来表示
如果字符串本身包含单引号,这时可以用双引号括起来表示,如果包含双引号,就可以用单引号括起来表示,如果字符串既包含单引号也包括双引号,那么需要使用\进行转义。
常用的转义字符还有:
\n表示换行
\t 表示一个制表符
\\表示 \ 字符本身
raw字符串
如果一个字符串包含很多需要转义的字符,对每一个字符都进行转义会很麻烦,我们可以在字符串前面加个r,表示这是一个raw字符串,里面的字符就不需要转义了。
print(r"c:\newfile\test.py")
#c:\newfile\test.py
print("c:\newfile\test.py")
#c:
#ewfile est.py
raw'...',不能表示多行字符串,也不能表示包含’和"的字符串(不能转义)
多行字符串
使用'''...'''表示多行字符串
print('''Line 1
Line 2
Line 3''')
也可以在多行字符串前面添加r,把这个多行字符串也变成raw字符串
字符串切片
前闭后开区间
s = 'ABCDEFG'
s1 = s[0:2]
print(s1) # AB
s2 = s[2:4]
print(s2) # CD
以’'或""括起来的任意文本
字符串拼接
通过+可以将两个字符串拼接在一起
name = "world"
print("hello" + name) # helloworld
字符串格式化
%占位
% 表示:我要占位
s 表示:将变量变成字符串放入占位的地方
综合起来:我先占个位置,等一会有个变量过来,我把它变成字符串放到占位的位置
(%d:将内容转换成整数,放入占位位置;%f:将内容转换成浮点数,放入占位位置)
name = "David"
tel = 1234567
message = "姓名:%s,电话:%d" % (name, tel)
print(message) # 姓名:David,电话:1234567
print("%f" % tel) # 1234567.000000
精度控制
可以使用符号m.n来控制数据的宽度和精度
m控制宽度,要求是数字,设置的宽度小于数字自身,不生效
.n控制小数点精度,要求是数字,会进行小数的四舍五入
print("%5d" % 11) # [空格][空格][空格]11,用三个空格补齐宽度
print("%7.2f" % 11.345) # [空格][空格]11.35,小数部分限制两位四舍五入为.35,用两个空格补齐宽度
print("%.2f" % 11.345) # 11.35,不限制宽度,只设置小数点精度为2
f"内容{变量}"
name = "David"
sex = "male"
age = 20
print(f"我是{name},我的性别是{sex},我的年龄是{age}")
format
print('{} {}'.format("hello", "world")) # hello world
print('{0} {1}'.format("hello", "world")) # hello world
print('{1} {0}'.format("hello", "world")) # world hello
print("hello:{country}, hello:{city}".format(country="china", city="beijing")) # hello:china, hello:beijing
a = 3
b = 4
print('{} + {} = {}'.format(a, b, a+b)) # 3 + 4 = 7
列表(List)
有序的可变序列
元组(Tuple)
有序的不可变序列
集合(Set)
无序不重复集合
字典(Dictionary)
无序Key-Value集合
空值(None)
空值
空值用None表示
- 函数无返回值
- if判断:None等同于False
- 声明无内容变量
数据类型转换
- int(x):将x转换为一个整数
- float(x):将x转换为一个浮点数
- str(x):将对象x转换为字符串
浮点数转换为整数会丢掉小数部分,字符串必须为纯数字才能转换为数字
标识符的命名规则
- 大小写敏感
- 标识符由大小写英文字母、数字、中文和下划线组成(不推荐使用中文)
- 标识符不能由数字开头
- 标识符不能与Python关键字重合(比如:and、or、not)
标识符命名规范
定义变量
变量没有类型,字符串变量表示变量存储了字符串而不是表示变量就是字符串
变量名 = 数据
一个变量可以先后存储多种不同类型的数据
a = 1 # 这个时候a存储的是整数类型
print(a)
a = 'ABC' # 这个时候a存储的是字符串类型
print(a)
运算符
算数运算符
加减乘除
整数与浮点数运算的结果是浮点数
除法的运算结果是浮点数
# 加法
num1 = 10
num2 = 0.5
result = num1 + num2
print(result) # ==> 10.5
# 减法
result = num1 - num2
print(result) # ==> 9.5
# 乘法
result = num1 * num2
print(result) # ==> 5.0
# 除法
result = num1 / num2
print(result) # ==>20.0
取模
print(3 % 2) # ==> 1
print(33 % 10) # ==> 3
print(99 % 30) # ==> 9
地板除
与普通除法相比,会忽略结果的纯小数部分,使用//进行
都为整型则结果也为整型,只要有一个float,则返回float
print(10//4) # ==> 2
print(10//2.5) # ==> 4.0
print(10//3) # ==> 3
保留小数点位数
round(),第一个参数是需要保留小数点位数的数值,第二个参数是保留的位数
print(round(3.344, 2)) # ==> 3.34
print(round(3.345, 2)) # ==> 3.35
指数
a**b:为a的b次方
print(5**2) # ==> 25
赋值运算符
- =:赋值运算符,把 = 右边的结果赋给左边的变量
- +=:c+=a等效于c=c+a
- -=
- *=
- /=
- %=
- **=
- //=
输入输出
数据输出:print()
- print默认换行输出,在print后加上end=‘’,即可实现输出不换行
print("hello", end="")
数据输入:input()
- 使用input()语句可以从键盘获取输入
- 使用一个变量接受input语句获取的键盘输入数据即可
- 在input()的括号中输入语句,会在输入前输出这段提示语句
- 输入的数据都看作是字符串
判断语句
布尔类型
与运算
两个布尔值都为True时,结果为True
True and True # ==> True
True and False # ==> False
False and True # ==> False
False and False # ==> False
或运算
只要有一个值为True,结果就为True
True or True # ==> True
True or False # ==> True
False or True # ==> True
False or False # ==> False
非运算
True变为False,False变为True
not True # ==> False
not False # ==> True
布尔类型也可以与其他类型做运算
Python把0、空字符串和None看成False,其他数值和非空字符串都看成True
print(True and 0 or 99) # ==> 99
要解释以上结果需要涉及到短路计算
- 在计算
a and b时,如果 a 是 False,则根据与运算法则,整个结果必定为 False,因此返回 a;如果 a 是 True,则整个计算结果必定取决与 b,因此返回 b。
- 在计算
a or b时,如果 a 是 True,则根据或运算法则,整个计算结果必定为 True,因此返回 a;如果 a 是 False,则整个计算结果必定取决于 b,因此返回 b
True and 0 or 99:首先计算True and 0,根据短路计算返回0,然后计算0 or 99,根据短路计算返回99
比较运算符
==、!=、>、<、>=、<=
if-else
- 通过缩进表示这行代码是
if/else判断的一个子分支(表示这行代码属于哪个语句)
- 在if/else后有一个
:,表示接下来是分支代码块
score = 59
if score < 60:
print('抱歉,考试不及格')
else:
print('恭喜你,考试及格')
elif 相当于 else if , 可以简化逻辑
score = 59
if score < 60:
print('抱歉,考试不及格')
else:
if score >= 90:
print('恭喜你,拿到卓越的成绩')
else:
if score >= 80:
print('恭喜你,拿到优秀的成绩')
else:
print('恭喜你,考试及格')
score = 59
if score < 60:
print('抱歉,考试不及格')
elif score >= 90:
print('恭喜你,拿到卓越的成绩')
elif score >= 80:
print('恭喜你,拿到优秀的成绩')
else:
print('恭喜你,考试及格')
特别注意: 这一系列条件判断会从上到下依次判断,如果某个判断为 True,执行完对应的代码块,后面的条件判断就直接忽略,不再执行了。
循环语句
while循环
输出0~99
i = 0
while i < 100:
print(f"i = {i}")
i += 1
for循环
for 临时变量 in 待处理数据集:
循环满足条件时执行的代码
将待处理数据集中的数据挨个取出,每一次循环就将当前数据赋予这个临时变量,在循环体中使用
str = "Hello"
for x in str:
print(x)
"""
H
e
l
l
o
"""
- 无法定义循环条件
- 只能从待处理的数据集中,依次取出内容进行处理
- 理论上讲Python的for循环无法构建无限循环(被处理的数据集不可能无限大)
待处理数据集,严格来说称之为:序列类型
序列类型指:其内容可以一个个依次取出的一种类型,包括:
range语句
生成数字序列
- range(num):获取一个从0开始,到num结束的数字序列(不含num本身)
如:range(5)取得的数据是:[0,1,2,3,4]
- range(num1, num2):获取一个从num1开始,到num2结束的数字序列(不含num2本身)
如:range(5, 10)取得的数据是:[5,6,7,8,9]
- range(num1, num2, step):获取一个从num1开始,到num2结束的数字序列(不含num2本身),数字之间的步长为step(step默认为1)
如:range(5, 10, 2)取得的数据是:[5,7,9]
在for循环外部可以访问临时变量,但在编程规范上是不允许这样做的
for x in range(10):
print(f"{x} ",end="")
print(x)
# 0 1 2 3 4 5 6 7 8 9 9
如果想访问for循环内部变量,则应该在for循环外部预先定义
x = 0
for x in range(10):
print(f"{x} ",end="")
print(x)
# 0 1 2 3 4 5 6 7 8 9 9
for循环相当于对x进行了10次内容覆盖
continue和break
- continue:中断本次循环,直接进入下一次循环
- break:直接结束循环
- 在嵌套循环中,只能作用在所在的循环上,无法对上层循环起作用
函数
定义
def 函数名(传入参数):
函数体
return 返回值
- 必须先定义后使用、参数不需要可省略、返回值不需要可省略
传入参数
功能:在函数进行计算的时候,接受外部(调用时)提供的数据
def add(x, y):
result = x + y
print(f"{x} + {y}的计算结果是:{result}")
add(1,2)
- 函数定义中提供的x和y,称之为形式参数,参数之间使用逗号分隔
- 函数调用中提供的1和2,称之为实际参数,按顺序传入,使用逗号分隔
返回值
def add(a, b):
result = a + b
return result
r = add(1, 2)
print(r)
说明文档
在函数体之前通过多行注释的形式,对函数进行说明解释
pycharm在函数名之后输入"""回车会自动补全注释
def add(x, y):
"""
:param x:
:param y:
:return:
"""
result = x + y
return result
def add(x, y):
"""
add函数可以接收2个参数,进行2数相加的功能(整体说明)
:param x:形参x表示相加的其中一个数字(参数说明)
:param y:形参y表示相加的另一个数字
:return:返回值是2数相加的结果(返回值说明)
"""
result = x + y
return result
鼠标悬停可以查看文档

变量作用域
局部变量:在函数体内定义的变量,只能在函数体内使用
全局变量:在函数体外定义的变量,函数体内外都能使用
以下示例中,test函数内部相当于重新定义了一个num变量赋值为500,此时函数外部的num变量并没有被修改
num = 100
def test():
num = 500
print(num)
test()
print(num)
# 500
# 100
要想在函数内部修改全局变量需要使用global关键字
global:在函数内部声明变量为全局变量
此时test()中的num和函数外的num就是同一个变量了
num = 100
def test():
global num
num = 500
print(num)
test()
print(num)
# 500
# 500
数据容器
一种可以容纳多份数据的数据类型,容纳的每一份数据称之为一个元素,每一个元素可以是任意类型的数据,如字符串、数字、布尔等。
列表(list)
可以容纳多个元素(上限为2**63-1)
可以容纳不同类型的元素
数据有序存储(有下标序号)
允许重复数据存在
可以修改、增加或删除元素
基本语法
以[]作为标识,列表内每一个元素之间用逗号隔开
元素可以为不同的数据类型,支持嵌套
# 定义列表
list1 = [1, 2, True, "hello"]
# 定义空列表
list2 = []
list3 = list()
下标索引
从前向后:从0开始,依次递增
从后向前:从-1开始,依次递减
list1 = [1, 2, True, "hello", [1, 2, 3]]
print(list1[0]) # 1
print(list1[-1][1]) # 2
- 列表.index(元素):查找某元素在list中第一次出现的位置
- 列表[下标]=值:修改特定索引的元素值
- 列表.insert(下标,元素):在指定的下标位置,插入指定的元素
- 列表.append(元素):将指定元素追加到列表的尾部
- 列表.extend(其它数据容器):将其它数据容器的内容取出,依次追加到列表尾部
- del 列表[下标]:删除指定位置元素
- 列表.pop(下标):删除指定位置元素并返回
- 列表.remove(元素):删除某元素在列表中的第一个匹配项
- 列表.clear():清空列表内容
- 列表.count(元素):统计某元素在列表内的数量
- len(列表):统计列表内有多少元素
元组(tuple)
元组与列表类似,最大的不同点在于:元组一旦定义完成,就不可修改
基本语法
使用小括号定义,元素之间使用逗号分隔,数据可以是不同的数据类型
# 定义元组
tuple1 = (1, 2, "hello", [1, 2], (3, 4))
# 定义空元组
tuple2 = ()
tuple3 = tuple()
注意:如果元组只有一个数据,这个数据后面要添加逗号,否则不是元组类型
tuple1 = (1)
print(type(tuple1)) # int
tuple2 = (1,)
print(type(tuple2)) # tuple
元组的操作方法和列表相同,但是不能增加/删除/修改元素
注意:元组的内容不能修改,但是可以修改元组中嵌套的list的内容
tuple1 = (1, [1, 2, 3])
tuple1[1][1] = 1
print(tuple1) # (1, [1, 1, 3])
字符串(string)
一个字符串可以存放任意数量的字符
下标索引
从前向后,下标从0开始
从后向前,下标从-1开始
注意:同元组一样,字符串是一个无法修改的容器,如果想要修改/删除/追加字符只能通过建一个新的字符串。
- 字符串.index(字符串):查找特定字符串的下标索引值
- 字符串.replace(字符串1,字符串2):将字符串内的全部字符串1替换为字符串2,这里不是修改字符串本身,而是得到一个新的字符串
- 字符串.split(分隔符字符串):按照指定的分隔符字符串,将字符串划分为多个字符串,并存入列表对象中,字符串本身不变,而是得到了一个列表对象
- 字符串.strip():去掉前后空格
- 字符串.strip(字符串):去除前后指定字符串,这里不是严格按照字符串来去除的,而是把其划分为小字符串,如传入“12”,则字符串前后的“12”和“21”都会被去除
- 字符串.count(字符串):统计字符串内某字符串出现的次数
- len(字符串):统计字符串的字符个数
序列的切片操作
序列:内容连续、有序,可使用下标索引的一类数据容器(列表、元组、字符串)
切片:从一个序列中,取出一个子序列
语法:序列[起始下标:结束下标:步长]
- 起始下标表示从何处开始,留空视作从头开始
- 结束下标表示何处结束(不含),留空视作截取到结尾
- 步长:依次取元素的间隔,步长为负数表示反向取(起始下标和结束下标也要反向标记),省略步长为1
此操作不会影响序列本身,而是会得到一个新的序列
[::-1]:表示将序列反转
集合(set)
不支持重复元素且内容无序
基本语法
使用{}定义
空集合使用set()定义,不能使用{},{}是字典
# 定义集合变量
set1 = {1, 2, "hello"}
# 定义空集合
set2 = set()
不能使用下标取元素,但是集合和列表一样可以修改
- 集合.add(元素):将指定元素添加到集合内,集合本身被修改
- 集合.remove(元素):将指定元素从集合内移除
- 集合.pop():从集合中随机取出一个元素,返回一个元素,同时元素被移除
- 集合.clear():清空集合
- 集合1.difference(集合2):取集合1和集合2的差集(集合1有而集合2没有),得到一个新的集合,集合1和集合2不变
- 集合1.union(集合2):将集合1和集合2合成新集合
- len(集合):统计集合元素数量
集合不支持下标索引,不能用while循环遍历,可以用for循环
set1 = {1, 2, "hello"}
for i in set1:
print(i)
字典(dict)
基本语法
使用{}定义,不过存储的元素是一个个的:键值对
# 定义字典变量
dict1 = {"zhangsan": 30, "lisi": 40, "wangwu": 50}
# 定义空字典
dict2 = {}
dict3 = dict()
字典不允许key重复,重复添加会把前面的覆盖掉
# 定义字典变量
dict1 = {"zhangsan": 30, "zhangsan": 40, "wangwu": 50}
print(dict1["zhangsan"]) # 40
不可以通过下标索引,可以通过key值来取得对应的value
key和value可以是任意数据类型(key不可为字典)
- 字典[key] = value:key不存在新增元素,key存在更新元素
- 字典.pop(key):获取指定key的value,同时key的数据被删除
- 字典.clear():清空字典
- 字典.keys():得到字典中的全部key,可以用来遍历字典
遍历字典:可以首先通过keys获取字典中的全部key进行遍历,也可以for循环遍历每次取得的就是字典的key
总结
- 是否支持下标索引
- 支持:列表、元组、字符串 - 序列类型
- 不支持:集合、字典 - 非序列类型
- 是否支持重复元素:
- 支持:列表、元组、字符串 - 序列类型
- 不支持:集合、字典 - 非序列类型
- 是否可以修改
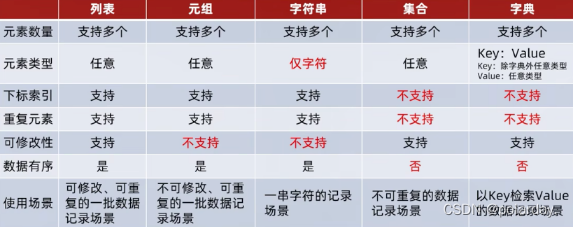
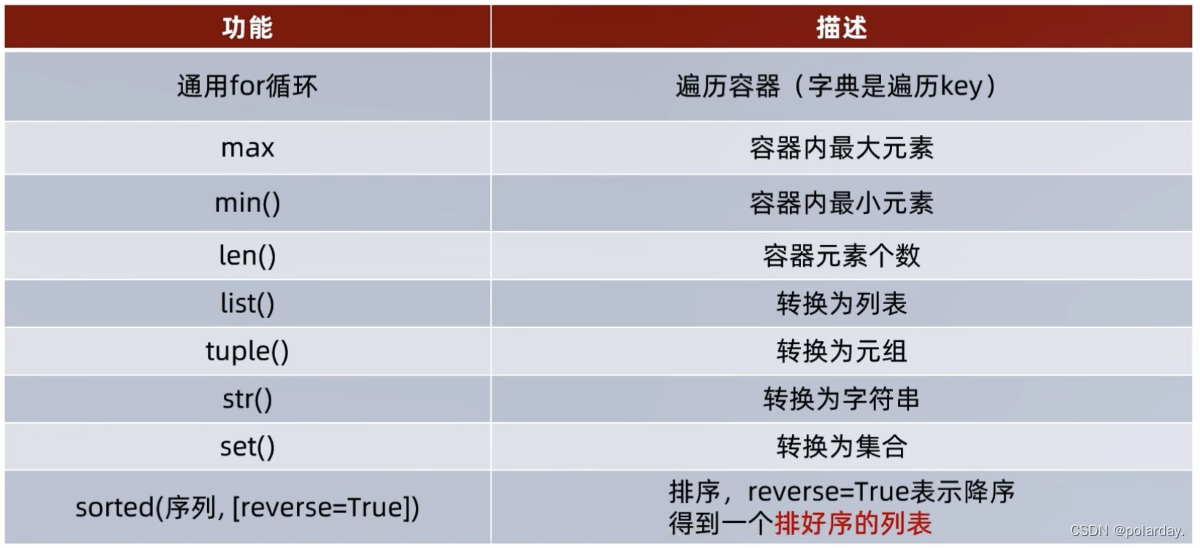
通用操作
遍历
- 五类数据容器都支持for循环遍历
- 列表、元组、字符串支持while循环,集合、字典不支持(无法下标索引)
函数进阶
多返回值
多个返回值之间用逗号隔开
支持不同类型的数据return
- 可以使用1个变量接受多返回值,返回类型为tuple
- 可以使用多个变量分别接受各个返回值,接受变量必须与返回值一一对应
def test_return():
return 1, 2
t = test_return()
print(type(t)) # <class 'tuple'>
print(t) # (1, 2)
x, y = test_return()
print(x, y) # 1 2
传参方式
位置参数
调用函数时根据函数定义的参数位置来传递参数
def user_info(name, age, gender):
print(f'您的名字是{name}, 年龄是{age}, 性别是{gender}')
user_info('TOM', 20, '男')
关键字参数
函数调用时通过“键=值”的形式传递参数
def user_info(name, age, gender):
print(f'您的名字是{name}, 年龄是{age}, 性别是{gender}')
user_info(gender='女', name='Alice', age=25)
可以不固定顺序
可以和位置参数混用,位置参数必须在前,且匹配参数顺序
def user_info(name, age, gender):
print(f'您的名字是{name}, 年龄是{age}, 性别是{gender}')
user_info('Alice', gender='女', age=25)