k8s_day01_01
1、it发展趋势
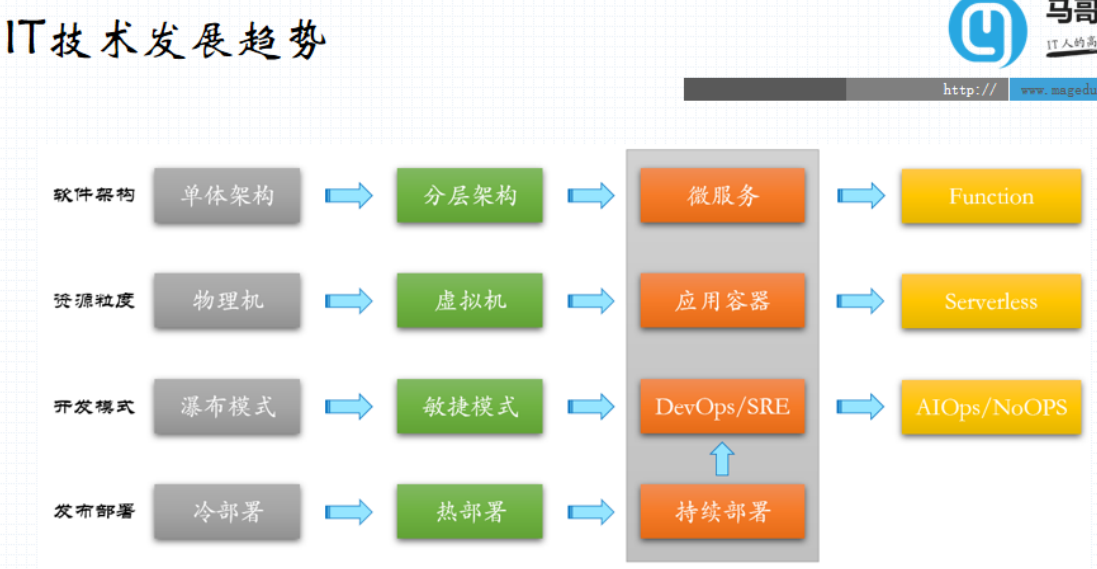
it 的发展趋势中,我们最早的资源粒度从最早的物理机时代 到达十年之前的 kvm 还有xen 为代表的虚拟化代表的虚拟机时代 ,那个时候,VMware是如日中天的时期,vmware 以产品众多且成熟 而且是虚拟化的先行者 ,所以在当时的商业领域中 颇负盛名。
在开源领域中,仍然以xen 为代表的 称之为 准虚拟化或者半虚拟化技术,以及像后来的kvm 严重依赖于cpu ,内部固有的硬件虚拟化技术hvm 也称之为硬件辅助的虚拟化技术 也成为完全虚拟化技术为代表的这2类产品 ,给IT 环境带来了很大的变化。
其实我们之前讲过,运维工程师主要有三大任务之一的就是 资源管理。过去呢,在虚拟机出现之前,只能分配物理机给他们,需要审批上架之类一系列的服务,后来有了虚拟机之类的技术,只要在多台物理服务器之上构建出一个统一的虚拟化管理环境, 一旦测试或开发工程师用到新的主机、实例或者隔离的环境时候,只须申请相对应的工单 ,选择是批复否通过即可,大大的提升了当时的效率。
2013年后,docker的出现 改变了当时一贯的 打包、分发 软件构建逻辑。 对于软件程序来说,尤其是C开发的程序,非常依赖底层的平台环境,一个程序编译完后,如果是x86环境编译的想切换到x64环境运行,只能重新编译。
所以在我们交付一个软件时,客户端可能有各种各样的软件平台 是不一样的,底层硬件平台所构建的操作系统 OS 又是不一样的,必须提供一个巨大的产品矩阵才能满足所有的用户需要,这对于我们程序打包发布来讲是及其麻烦的,所以在学了docker 容器之后,不考虑底层内核操作系统的差异话,一次打包构建之后就能到处运行了。因此极大的便捷了软件的打包发布流程。
2、容器 原理
但是我们知道,容器所实现的这种功能 ,无非就是在底层一个 一层硬件和内核的基础之上,实现了用户空间的切分。在正常情况下一个内核空间之上只有一个用户空间,我们把这个用户空间 进行切分,每个用户空间用来运行一个独立的应用程序及其子进程,这个每一个用户空间就叫做userspace ,就完全把它当作一个容器来对待,只有运行中的叫容器,未运行的在docker 容器的语境中叫镜像。
每个镜像就是一个独立的根文件系统,它拥有一个程序运行所依赖的库文件、运行环境 配置文件等等。这个文件在docker打包构建时,为了能实现镜像层级的复用,它采取了一个非常有创意的技术:分层构建、联合挂载的技术,依赖于高级的文件系统 aufs、overlayfs2 (可以理解为这就是它的存储驱动),有时候把它称为 ‘graphdriver’? ,对于镜像来说是分层构建的,基于某一个应用来讲,要把它所用到的所有镜像 叠加起来 统一挂载在统一的一个用户空间,我们把它称为联合挂载机制 。
容器运行起来之后就是一个独立的用户空间,之所以内存在 就是因为内部有一个进程存在。因为之所以一个用户空间是运行状态的,就意味着内部有一个ID 号为1 的进程,而后呢 其他进程都是该进程的子进程 我们把它称为用户的supervisor 进程, 学习操作系统的都知道这是一个 init 进程(后来叫systemd),而现在呢由于容器内只运行一个进程及其子进程,所以id为1的进程就是应用程序自身,比如通常nginx 容器的id为1 的就是nginx 的master 进程, worker 进程坏了不碍事,如果父进程终止了,其子进程也会终止,这个容器也就宕机了。一个进程接受到singnl term 或 kill 的信号就会终止. 这个id为1的进程能够接受处理 外部的信号。
3、容器技术缺点
简单来说 ,就是把一个内核支撑之上的用户空间 强行分成多个用户空间,让每个用户空间内部只运行一个进程 ,从而产生那种人为的隔离效果。 这种隔离一定是藕断丝连的,因为它底下共享的是统一组内核管理下资源 ,尽管做了各种各样的隔离,但是相比较传统的主机及虚拟化技术 ,还是有很大区别和隔离不好的特点,所以对于那些要求隔离达到严格、苛刻的那种应用程序 ,传统的主机及虚拟化技术仍然有它的用武之地
4、docker三大基础组件
docker 容器技术中有三个非常重要的组件,由docker cllient 、 docker host、 docker registry 所组成的运行环境。部署了docker 的主机叫做docker host ,通常会运行一个进程叫docker daemon 和docker 客户端进行交互, docker 客户端通常部署在本机上,通过本机的127 回环地址建立通信。事实上我们也可以把客户端构建在远程主机之上,叫docker client 与doker daemon 进行基于https 的rpc 通信, 能接收来自客户端的指令 docker start stop … 去管理docker主机上的各种镜像 :容器 container 、image、network、volume … (这些都可以称为docker 镜像)
docker 客户端 就是对这些镜像实现进行增删查改的请求,因为他们是能够通过http 协议 映射到http中post、get 、delete 之类的一些方法去实现。
如果想在docker host 上 启动并且运行一个软件,有个基本要求 ,‘dockergraph ”?上必须存有镜像,docker host 上如果没有 则必须依赖另一个组件registry,称为docker 注册表?可以叫docker 仓库 ,但是这并不是很精确。registry 上可以有很多个厂库,而且一个厂库通常是右一个程序的多个不同版本组成的 ,比如我们称为nginx 厂库,意味厂库内有以nginx标签为区别的各种镜像 镜像的表示由repo + tag 组成。 有名的registry 有 dockerhub Quey
5、容器带来的排障问题
docker 部署: 正常情况下, 单个docker 容器很难发生作用,除了部署起来很方便,但是由于每个容器都是一个隔离的用户环境,对运维没有益处反而有害,原因各位都明白,如果容器内只运行一个一个程序init docker 自身,如果出现bug ,我们想去诊断,在容器内会缺乏各种工具, tcpdump、ls 可能都没有,如果有, 则会被打包在每一个镜像当中,会 使得镜像太大了,分发起来不方便,很难越过文件边界系统去使用。
6、 docker 网络
docker 容器内的2个进程想通信怎么办? 需要用到docker 网络: 3个模型:
参考 :https://blog.csdn.net/mtldswz312/article/details/102901424
overlay的网络模型:也叫叠加网络 vxlan vlan
7、正常情况下跨2个容器宿主机的通信存在的问题:
7.1 隧道 :叠加网络(覆盖网络)模型
H表示主机地址,c 表示容器地址
-
都是 H1 主机上有容器 c1 , H2 上有容器c2
c1访问 c2
c1先要把SANT 源地址转换 成为H1的地址, 访问 H2 的30080端口【容器C2暴露的端口】, H2 则需要通过目标地址转换成c1的地址,所以c1 、 c2 老死都不知道 对方的真实地址。 因为c1 请求 看到的是H2地址 c2请求看到的是 H1 地址。
当容器数量变多时, 访问的关系就变得复杂,且效率低下
叠加网络(覆盖网络)模型 缺点
在两台主机上 ,用ipip 隧道进行通信 ,c1 和c2 请求看到的是对方的真实地址
缺点 传统以太网MTU值是1500 , c1 c2在封装报文时 ,因为多分装了ip头,会产生巨型帧,所以内层c1 c2 的MTU 值必须得设置的小一些 ,这样就降低了传输了效率,每次发报文都要额外占用几十个字节
7.2 路由表:(underlay 承载网络):
容器、主机在一个大二层网络,容器之间都在一个网段下 如10.0.0.0/8 , c1 把H1 当作路由器 ,c2 把H2 当作路由器。 c1 访问c2 时 直接通过宿主机间的路由 H1、H2 当作下一跳,通过路由表直接访问。 缺点: 由于存在太多的容器、主机,且动态变化, 每个主机必须维护 到其他主机的动态路由表。
解决方法 :就是搞一个注册中心 或者路由表的方式通过BGP 路由学习【缺点是当host 过多时或变化屏藩时,产生的路由学习报文会很大】
比如现在有3个主机 ,注册中心给每个主机的网段 是 172.16.1.0/16 、172.16.2.0/16 、172.16.3.0/16 、172.16.X.0/16,每加一个主机就是一个新的子网段。 这个网络分配的结果向注册中心汇报,每个主机上运行一个守护进程 作为客户端始终注册监听着数据信息的改变,一旦注册中心的数据发生改变就会更新自己的路由表。 underlay 模型特点就是1到N ,一台主机到另外其他的所有主机都可能是下一跳。
这种网络模型产生(或者叫引入)的问题就是 : docker 容器天生的轻量便捷性就意味着变动频繁,如果一个docker host 运行一个 nginx 容器 ,后来这台主机挂了,生成新nginx容器 就会产生新的网络配置,客户端就访问不到新的nginx 容器
8、docker 本质
docker 用到容器技术不是创新 ,容器用的是内核技术 ,docker 本身可认为是一个UI或者叫Manager ,调用了内核的功能,之所以大火是因为docker 创造性发明了镜像技术
9、ks 什么是?
ks 就是一个组件 ,把底层物理机的资源集合起来 抽象成为资源池,而后把抽象的结果以接口提供给客户端 ,客户端只要向ks 提前运行容器的请求,容器就能跑起来,至于跑到哪,不用管
10、ks 优点及带来的职业趋势
当单个实例无法承载我们访问 请求时 ,过去的策略是 加机器 上负载均衡。 ks 的话 ,如果容器的数量不够用,会自动创建容器并且添加到负载均衡器,这个过程是自动的,当然也可以手动介入。纯自动的话,可以创建 控制器,控制器会监控容器数量,多一个或少一个都直接添加删除。 而且可以在这个控制器上添加一个二级控制器,二级控制器可以对接到监控系统上,监控系统会采集一级控制器下容器内存、cpu的指标,如果过低,或者过高, 就控制一级(底层的)控制器 添减容器数量,知道这些容器的内存、cpu指标均为达到 监控系统的阈值。
这就是运维工程师的核心职责 ,这听起来很好 ,但是容器大多是有状态的应用 如果mysql 主从 ,就不能随便增减。 在ks上 ,有专业的运维工程师,把特定 集群容器的的管理经验沉淀下来, 代码化, 这个代码在ks 上 叫做 operator ,也就是运维工程师 。如果要运行mysql 主从 ,只要创建 mysql 的operator 即可。可以实现mysql 的搭建、数据备份。 对于有经验的运维开发工程师 ,从事开发operator ,或者对ks 二次开发 更好,也就是SRE【把运维经验工具化】。
11、ks 组件构成
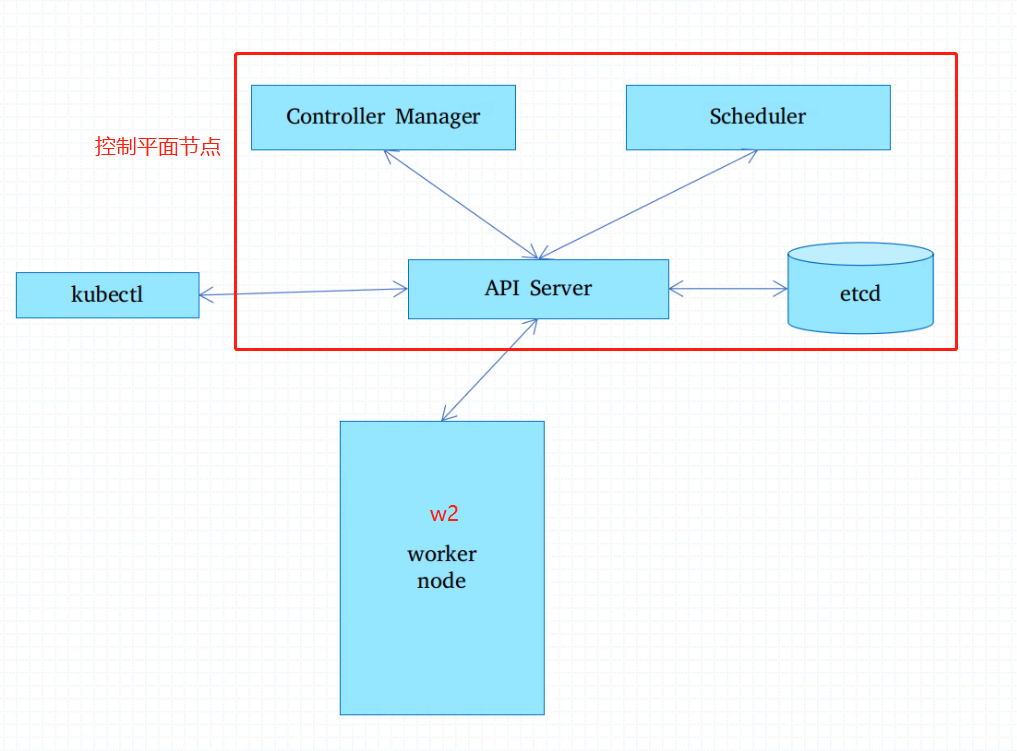
ks 上 的节点有2种角色 master 和 worker
master node 有以下几个组件构成:
- API server
- Contoller Manger 负责管理各种各样的控制器
- scheduler 调度器
- Etcd 强一致性 分布式注册中心 或者叫 kv 存储服务器。本来API server 是要存各种各样的数据的,但是它没有存 ,而是利用ectd 存各种各样的数据
worker node
这3个客户端组件 只会和 apiserver 服务端进行交互。 apiserver 是整体的控制中心,什么事都不干,除了存数据,真正的数据中心是这个Controller Maneger ,cm 并不会直接指挥kubelet 工作, 而是 cm 会查询apiserver 的状态 ,如过 结果不对就请求改变这个结果,而kubelet 会看见apiserver 的改变 ,也就看到了指令
apiserver 借助 etcd 存储状态数据。 kube-proxy kubelet 和 API server 通信的结果 、和scheduler 的下发结果。
12 、容器运行的流程
现在要运行一个容器 ,既可以用controler 运行容器 ,也可以直接请求运行容器。
客户端想请求运行容器 用到kubectl, 提交请求后 scheduler 会发现 这个容器还没有被调度,scheduler 就会从这几个容器中找一个合适运行容器的节点w2 ,scheduler 并不会直接告诉w2 ,而是告诉API server。w2 的kubelet会一直watch API server ,关注其中和自己相关的事件,一旦发现某个调度请求和自己相关,自己就会执行相应的操作。
worker node叫数据节点
master 叫 控制节点