目录
一、数据集介绍
二、问题及分析思路
1、问题
2、分析思路
三、代码
一、数据集介绍
数据集来源于用户在网上的购物行为,涵盖了过去一年有购买行为的64000个用户,这些用户被用于电子邮件营销活动的实验分析。实验的目的是衡量哪个版本的电子邮件营销活动最有效,以及针对哪部分人群最有效。用户被随机地分为以下三组:
- 1/3的用户会收到一封以男士商品为主的电子营销邮件(实验组-男士版)
- 1/3的用户会收到一封以女士商品为主的电子营销邮件(实验组-女士版)
- 1/3的用户不会收到邮件(对照组)
两周后收集实验结果,可用的特征有:
- Recency:距离最近一次购买行为,经过了多少个月
- History:过去一年用户实际花费的金额
- Mens: 1/0,1-过去一年用户购买过男士用品
- Womens: 1/0,1-过去一年用户购买过女士用品
- Zip_Code::地区
- Newbie: 1/0,1-过去一年内的新用户
- Channel: 过去一年用户的购物渠道
用于描述用户的分组信息:
- Segment:有三个枚举值分别是Mens-E-mail、Womens-E-mail和No-E-mail
实验有三个评价指标,分别是:
- Visit:1/0,1-用户在两周内访问了网站
- Conversion:1/0,1-用户在两周内有购买行为
- Spend:用户在两周内实际消费的金额
二、问题及分析思路
1、问题
数据集的提供者提出了8个问题:
- 哪个电子邮件活动最有效,男士版还是女士版?
- 男士版电子邮件活动为每位顾客带来了多少销售额的增加?女士版电子邮件活动为每位顾客带来了多少销售额的增加?
- 如果你只能给10000个顾客发送Email,你会选择哪些顾客?为什么?
- 如果你可以从收到电子邮件的顾客中剔除10000个人,不让他们参加此活动,你会选择哪些顾客?为什么?
- 对于不同的客户群体,男士版本和女士版本的活动效果有差异吗?
- 当选择不同的评价指标,比如访问、转化和消费额时,活动效果有差异吗?
- 你是否观察到任何异常或奇怪的发现?
- 根据实验结果,你会将男士版和女士版的投放定位到哪些顾客?你会用哪些数据来支持你的建议?
2、分析思路
Q1&Q6:
结论:
男士版活动最有效,visit、conversion、spend三个指标均比女士版效果明显。
思路:
这两个Q思路是一样的,本质都是在计算ATE。先做PSM匹配合适的对照样本,然后分别计算vist、conversion和spend三个指标的ATE,比较男士版本和女士版本的差异。
实验结果:

Q2:
思路:
这道题本质是在问,选择spend作为评价指标时的ITE是多少,和第一题的思路差不多,先做PSM,然后计算实验组每个用户的ITE。
Q3&Q4:
思路:
这两个Q本质上是一个问题,即如何按发送邮件的优先级给用户排个序?然后我们只需要取排序后的前10000和后10000个用户即可。

首先,我们可以根据用户的自然行为和受处理后行为这两个维度将用户分成四类,那么第二象限的用户是对营销活动最敏感的,如果发送邮件,应该优先发送给这部分用户。 其次,应该给第一象限的用户发送邮件,邮件对这部分用户也有一定的作用。最后,剩余的用户按照消费间隔(recency)和消费等级(history_segment)综合排序,距离上次购买间隔越久远越优先发送,消费等级越高越优先发送。
Q5&Q8:
结论:
男士版建议投放人群:
1)历史消费段在$350-1000用户群
2)多渠道购物用户群
女士版本建议投放人群:
1)历史消费段在$500-750和$1000+的用户群
2)多渠道购物用户群
3)新用户群
思路:
这两个Q本质都是进行HTE分析,通过比较实验在不同细分群体的效果,从而决定最佳投放人群。我们可以以ATE作为benchmark,如果细分群的CATE明显高于ATE,证明细分群的实验效应是显著的。
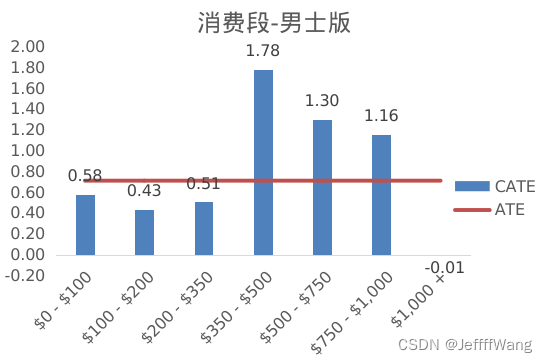
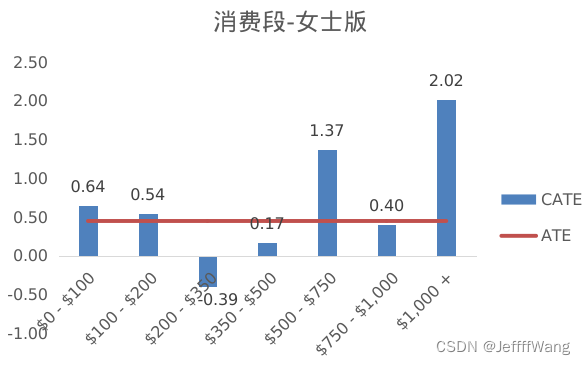
消费段(history_segment)比较,男士版在$350-500,$500-750和$750-1000这三个消费段的uplift是显著的,而女士版则是在$500-750和$1000+这两个消费段显著。说明男士版对中高档消费人群是有效的,而女士版则是对高档消费人群更有效。
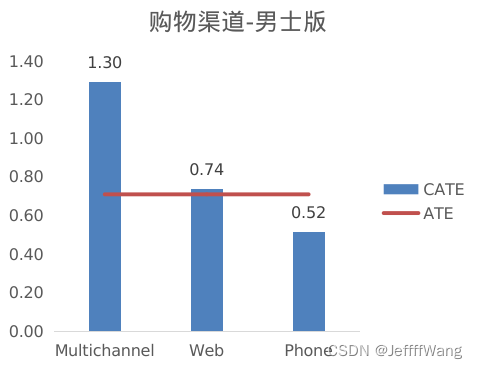
购物渠道(channel)比较,可以看出男士版和女士版都在Multichannel渠道有显著的uplift,说明过去曾在多个渠道有购物行为的用户(各处买买买),对邮件营销更加敏感。

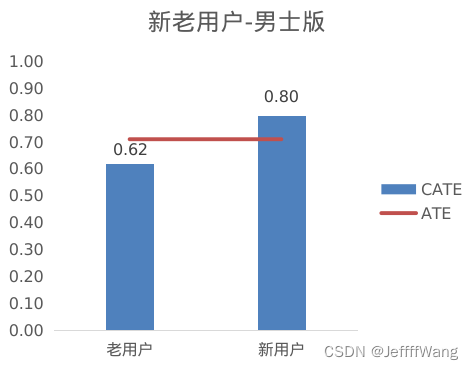
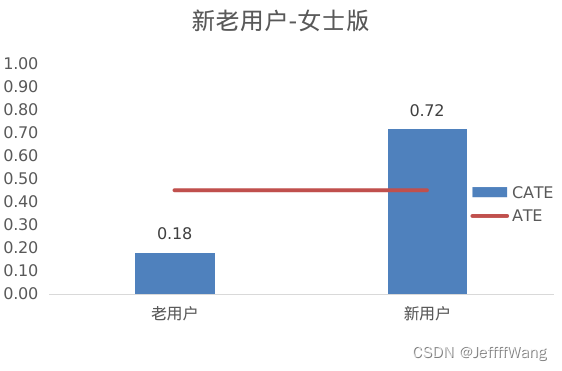
新老用户(Newbie)比较,男士版对新老用户的效果差不多,而女士版显然对新用户更有效果。
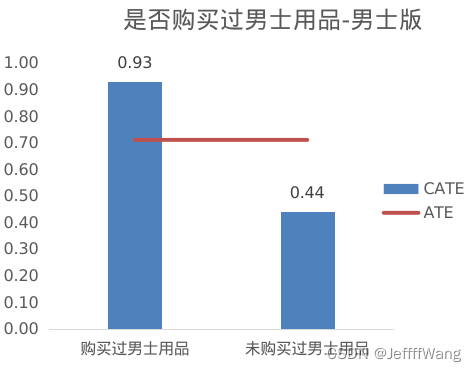
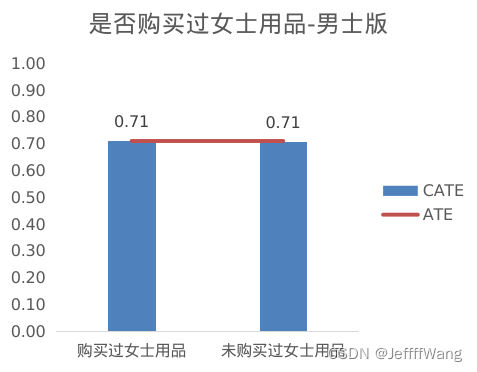
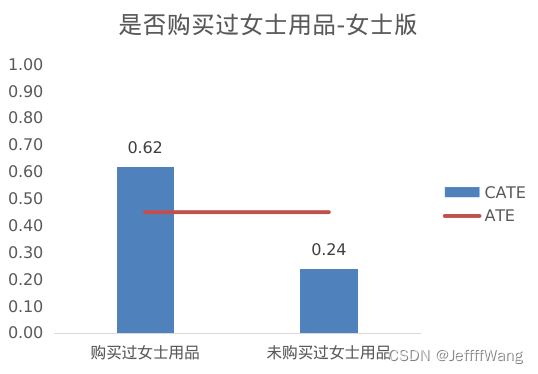
Q7:
这里有一个很有意思的发现:女士版的营销邮件对曾购买过女士用品的顾客效果很好,但对购买过男士用品的顾客效果一般。而男士版本的营销邮件却没有存在这个问题。 这反映了现实中的两个现象:
1)女士一般是家庭购物决策者,所以既会关注女士用品,也会关注男士用品;
2)男士一般很少给女士买东西,除非在一些纪念日、节假日等有意义的日子,所以女士用品的推荐对男士可能起不到太大作用。

三、代码
import pandas as pd
import psmatching.match as psm
import numpy as np
import random
import operator
random.seed(1) # 生成同一个随机数;
road='/home/jeff/data'# 数据存放的地址
###### 函数部分 ######
# 样本数量均衡测试
def sample_test(dt_treat,dt_control):
if len(dt_treat)>len(dt_control):
print('---样本数均衡测试---')
print('实验组样本数:%d,对照组样本数:%d,实验组需要剔除%d个样本' % (len(dt_treat),len(dt_control),len(dt_treat)-len(dt_control)))
l = list(dt_treat.index.values)
sap = random.sample(l, len(dt_treat) - len(dt_control)) # 随机抽取n个元素
dt_treat = dt_treat.drop(sap)
print('删除的数据索引为:%s' % str(sap))
print('Done!')
print('调整后的实验组样本数:%d,对照组样本数:%d' % (len(dt_treat),len(dt_control)))
print('\n')
else:
pass
return dt_treat
# 计算实验效应
def effect_calculate(core,dt):
y_1 = np.average(dt[dt.CASE == 1][core])
y_0 = np.average(dt[dt.CASE == 0][core])
ATE = y_1 - y_0
print('实验组%s:%.4f,对照组%s:%.4f,因果效应:%.4f' % (core, y_1, core, y_0, ATE))
# 用户发送邮件的优先级排序
def send_user(dt):
dt['recency_history'] = dt['recency'] + dt['history_segment']
# 根据spend,筛选第二象限用户群(自然不消费,邮件消费)
spd2=dt[ (dt['ITE_spend']>0) & ( (dt['spend_mch_1']==0) & (dt['spend_mch_2']==0) & (dt['spend_mch_3']==0) ) ]
spd2=spd2.sort_values(by=['ITE_spend'], ascending=False )
# 根据spend,筛选第一象限用户群(自然消费,邮件也消费)
spd1=dt[ (dt['ITE_spend']>0) & ( (dt['spend_mch_1']!=0) | (dt['spend_mch_2']!=0) | (dt['spend_mch_3']!=0) ) ]
spd1=spd1.sort_values(by=['ITE_spend'], ascending=False)
# 根据visit,筛选第二象限用户群(自然不访问,邮件访问)
vit2=dt[ (dt['ITE_spend']==0) & (dt['ITE_visit']>0) & ( (dt['visit_mch_1']==0) & (dt['visit_mch_2']==0) & (dt['visit_mch_3']==0) ) ]
vit2=vit2.sort_values(by=['ITE_visit'], ascending=False)
# 根据visit,筛选第一象限用户群(自然访问,邮件也访问)
vit1=dt[ (dt['ITE_spend']==0) & (dt['ITE_visit']>0) & ( (dt['visit_mch_1']!=0) | (dt['visit_mch_2']!=0) | (dt['visit_mch_3']!=0) ) ]
vit1=vit1.sort_values(by=['ITE_visit'], ascending=False)
# 剩下的用户按照recency和history_segment两个维度综合考虑
rem1=dt[ (dt['ITE_spend']==0) & (dt['ITE_visit']==0)].sort_values(by=['recency_history'], ascending=False)
rem2=dt[ (dt['ITE_spend']==0) & (dt['ITE_visit']<0)].sort_values(by=['recency_history'], ascending=False)
rem3=dt[ dt['ITE_spend']<0 ].sort_values(by=['recency_history'], ascending=False)
# 合并用户群
subs = [spd2, spd1, vit2, vit1, rem1, rem2, rem3]
df = pd.concat(subs).reset_index()
df.drop(columns=['recency_history','index'],inplace=True)
return df
###### 第一部分:数据预处理 ######
# 读取数据集
dt=pd.read_csv(road+'/EmailAnalytics.csv')
# 历史消费区间,文本型转类别型
dt['history_segment']=dt['history_segment'].apply(lambda x: int(x[0])-1)
# 区域,文本型转类别型
zip_mapping={'Rural':0,'Surburban':1,'Urban':2}
dt['zip_code']=dt['zip_code'].map(zip_mapping)
# 实验分组,文本型转类别型
seg_mapping={'No E-Mail':0,'Mens E-Mail':1,'Womens E-Mail':2}
dt['CASE']=dt['segment'].map(seg_mapping)
# 历史购买渠道,one-hot编码
dt=pd.get_dummies(dt,columns=['channel'])
# 删除没用的字段
dt.drop(columns=['history','segment'],inplace=True)
# 划分实验组和对照组
dt_ctl=dt[dt['CASE']==0]
dt_men=dt[dt['CASE']==1]
dt_wom=dt[dt['CASE']==2]
# 检查实验组和对照组样本比例是否均衡
dt_men=sample_test(dt_men,dt_ctl)
dt_wom=sample_test(dt_wom,dt_ctl)
dt_men=pd.concat([dt_men,dt_ctl])
dt_wom=pd.concat([dt_wom,dt_ctl])
dt_wom.loc[dt_wom['CASE']==2,'CASE']=1
# 保存数据集
dt_men.to_csv(road+'/Email_men.csv')
dt_wom.to_csv(road+'/Email_wom.csv')
###### 第二部分:实验分析 ######
# 数据集的地址,默认数据文件是csv格式,其他格式可能会报错
path=road+r'/Email_men.csv'
# 计算倾向性得分的模型格式,格式:Y~X1+X2+...+Xn,其中Y为treatment列,X为协变量列
model = "CASE ~ recency + history_segment + mens + womens + zip_code + newbie " \
"+ channel_Phone + channel_Web + channel_Multichannel"
# k每个实验组样本所匹配的对照组样本的数量
k = "3"
# 初始化PSMatch实例
m = psm.PSMatch(path, model, k)
# 计算倾向得分,为接下来的匹配准备数据
dd=m.prepare_data()
# 根据倾向性得分做匹配,其中caliper代表是否有卡尺,replace代表是否是有放回采样
m.match(caliper = None, replace = True)
# 混淆变量与treatment做卡方检验,检验混淆变量和treatment是不是独立的
# m.evaluate()
# 获取匹配的样本子集
mdt = m.matched_data
mdt['OPTUM_LAB_ID']=mdt.index
mdt.index.rename('index',inplace=True)
# 获取匹配的样本编号
mch = m.matches
# 计算实验的因果效应(ATE)
effect_calculate('visit',mdt)
effect_calculate('conversion',mdt)
effect_calculate('spend',mdt)
# 为每个实验组和对照组样本匹配评价指标
mch=pd.merge(mch,mdt[['OPTUM_LAB_ID','visit','conversion','spend']],left_on='CASE_ID',right_on='OPTUM_LAB_ID',how='left').rename(
columns={'visit':'visit_lab','conversion':'conversion_lab','spend':'spend_lab','OPTUM_LAB_ID':'LAB_ID'})
mch=pd.merge(mch,mdt[['OPTUM_LAB_ID','visit','conversion','spend']],left_on='CONTROL_MATCH_1',right_on='OPTUM_LAB_ID',how='left').rename(
columns={'visit':'visit_mch_1','conversion':'conversion_mch_1','spend':'spend_mch_1'})
mch=pd.merge(mch,mdt[['OPTUM_LAB_ID','visit','conversion','spend']],left_on='CONTROL_MATCH_2',right_on='OPTUM_LAB_ID',how='left').rename(
columns={'visit':'visit_mch_2','conversion':'conversion_mch_2','spend':'spend_mch_2'})
mch=pd.merge(mch,mdt[['OPTUM_LAB_ID','visit','conversion','spend']],left_on='CONTROL_MATCH_3',right_on='OPTUM_LAB_ID',how='left').rename(
columns={'visit':'visit_mch_3','conversion':'conversion_mch_3','spend':'spend_mch_3'})
mch=mch[['LAB_ID','visit_lab','visit_mch_1','visit_mch_2','visit_mch_3',
'conversion_lab','conversion_mch_1','conversion_mch_2','conversion_mch_3',
'spend_lab','spend_mch_1','spend_mch_2','spend_mch_3']]
# 计算实验的个体因果效应(ITE)
mch['ITE_visit']=mch['visit_lab']-(mch['visit_mch_1']+mch['visit_mch_2']+mch['visit_mch_3'])/3
mch['ITE_conversion']=mch['conversion_lab']-(mch['conversion_mch_1']+mch['conversion_mch_2']+mch['conversion_mch_3'])/3
mch['ITE_spend']=mch['spend_lab']-(mch['spend_mch_1']+mch['spend_mch_2']+mch['spend_mch_3'])/3
mch=pd.merge(mch,dt[['OPTUM_LAB_ID','recency','history_segment','mens','womens','zip_code','newbie','channel']],
left_on='LAB_ID', right_on='OPTUM_LAB_ID', how='left').drop(labels=['OPTUM_LAB_ID'],axis=1)
# 优先发送邮件的10000个用户
pri=send_user(mch).head(10000)
# 不应该发送邮件的10000个用户
last=send_user(mch).tail(10000)