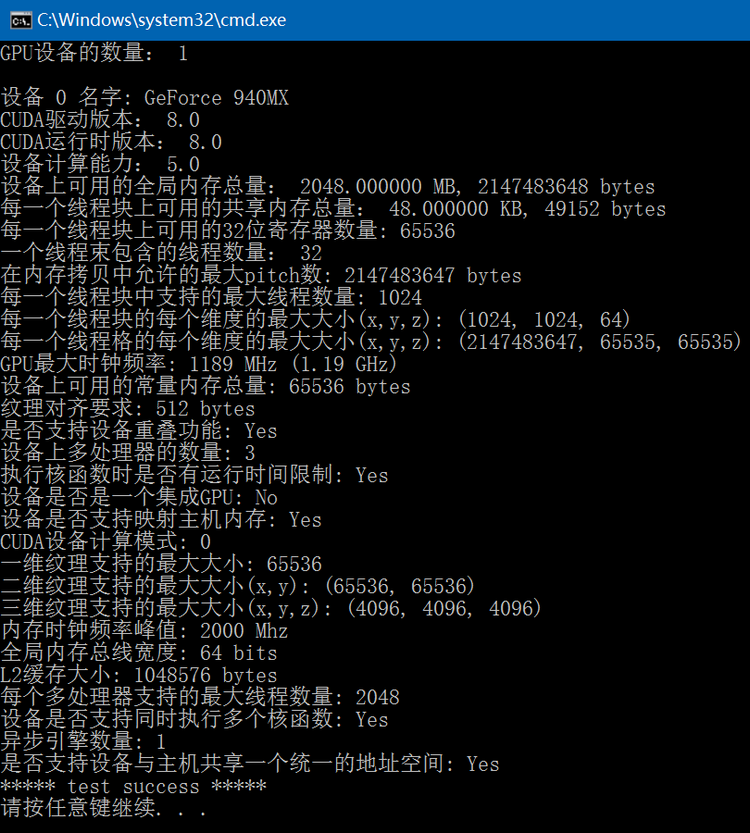
通过调用CUDA的cudaGetDeviceProperties函数可以获得指定设备的相关信息,此函数会根据GPU显卡和CUDA版本的不同得到的结果也有所差异,下面code列出了经常用到的设备信息:
#include "funset.hpp"
#include <iostream>
#include <cuda_runtime.h> // For the CUDA runtime routines (prefixed with "cuda_")
#include <device_launch_parameters.h>
/* reference:
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\1_Utilities\deviceQuery
*/
int get_device_info()
{
int device_count{ 0 };
// cudaGetDeviceCount: 获得计算能力设备的数量
cudaGetDeviceCount(&device_count);
fprintf(stdout, "GPU设备的数量: %d\n", device_count);
for (int dev = 0; dev < device_count; ++dev) {
int driver_version{ 0 }, runtime_version{ 0 };
/* cudaSetDevice: 设置GPU执行时使用的设备,0表示能搜索到的第一
个设备号,如果有多个设备,则编号为0,1,2... */
cudaSetDevice(dev);
/* cudaDeviceProp: 设备属性结构体
name: 设备名字,如GeForce 940MX
totalGlobalMem: 设备上可用的全局内存总量(字节)
sharedMemPerBlock: 每一个线程块上可用的共享内存总量(字节)
regsPerBlock: 每一个线程块上可用的32位寄存器数量
warpSize: 一个线程束包含的线程数量,在实际运行中,线程块会被分割成更小的线程束(warp),
线程束中的每个线程都将在不同数据上执行相同的命令
memPitch: 在内存拷贝中允许的最大pitch数(字节)
maxThreadsPerBlock: 每一个线程块中支持的最大线程数量
maxThreadsDim[3]: 每一个线程块的每个维度的最大大小(x,y,z)
maxGridSize: 每一个线程格的每个维度的最大大小(x,y,z)
clockRate: GPU最大时钟频率(千赫兹)
totalConstMem: 设备上可用的常量内存总量(字节)
major: 设备计算能力主版本号,设备计算能力的版本描述了一种GPU对CUDA功能的支持程度
minor: 设备计算能力次版本号
textureAlignment: 纹理对齐要求
deviceOverlap: GPU是否支持设备重叠(Device Overlap)功能,支持设备重叠功能的GPU能够
在执行一个CUDA C核函数的同时,还能在设备与主机之间执行复制等操作,
已废弃,使用asyncEngineCount代替
multiProcessorCount: 设备上多处理器的数量
kernelExecTimeoutEnabled: 指定执行核函数时是否有运行时间限制
integrated: 设备是否是一个集成GPU
canMapHostMemory: 设备是否支持映射主机内存,可作为是否支持零拷贝内存的判断条件
computeMode: CUDA设备计算模式,可参考cudaComputeMode
maxTexture1D: 一维纹理支持的最大大小
maxTexture2D[2]:二维纹理支持的最大大小(x,y)
maxTexture3D[3]: 三维纹理支持的最大大小(x,y,z)
memoryClockRate: 内存时钟频率峰值(千赫兹)
memoryBusWidth: 全局内存总线宽度(bits)
l2CacheSize: L2缓存大小(字节)
maxThreadsPerMultiProcessor: 每个多处理器支持的最大线程数量
concurrentKernels: 设备是否支持同时执行多个核函数
asyncEngineCount: 异步引擎数量
unifiedAddressing: 是否支持设备与主机共享一个统一的地址空间
*/
cudaDeviceProp device_prop;
/* cudaGetDeviceProperties: 获取指定的GPU设备属性相关信息 */
cudaGetDeviceProperties(&device_prop, dev);
fprintf(stdout, "\n设备 %d 名字: %s\n", dev, device_prop.name);
/* cudaDriverGetVersion: 获取CUDA驱动版本 */
cudaDriverGetVersion(&driver_version);
fprintf(stdout, "CUDA驱动版本: %d.%d\n", driver_version/1000, (driver_version%1000)/10);
/* cudaRuntimeGetVersion: 获取CUDA运行时版本 */
cudaRuntimeGetVersion(&runtime_version);
fprintf(stdout, "CUDA运行时版本: %d.%d\n", runtime_version/1000, (runtime_version%1000)/10);
fprintf(stdout, "设备计算能力: %d.%d\n", device_prop.major, device_prop.minor);
fprintf(stdout, "设备上可用的全局内存总量: %f MB, %llu bytes\n",
(float)device_prop.totalGlobalMem / (1024 * 1024), (unsigned long long)device_prop.totalGlobalMem);
fprintf(stdout, "每一个线程块上可用的共享内存总量: %f KB, %lu bytes\n",
(float)device_prop.sharedMemPerBlock / 1024, device_prop.sharedMemPerBlock);
fprintf(stdout, "每一个线程块上可用的32位寄存器数量: %d\n", device_prop.regsPerBlock);
fprintf(stdout, "一个线程束包含的线程数量: %d\n", device_prop.warpSize);
fprintf(stdout, "在内存拷贝中允许的最大pitch数: %d bytes\n", device_prop.memPitch);
fprintf(stdout, "每一个线程块中支持的最大线程数量: %d\n", device_prop.maxThreadsPerBlock);
fprintf(stdout, "每一个线程块的每个维度的最大大小(x,y,z): (%d, %d, %d)\n",
device_prop.maxThreadsDim[0], device_prop.maxThreadsDim[1], device_prop.maxThreadsDim[2]);
fprintf(stdout, "每一个线程格的每个维度的最大大小(x,y,z): (%d, %d, %d)\n",
device_prop.maxGridSize[0], device_prop.maxGridSize[1], device_prop.maxGridSize[2]);
fprintf(stdout, "GPU最大时钟频率: %.0f MHz (%0.2f GHz)\n",
device_prop.clockRate*1e-3f, device_prop.clockRate*1e-6f);
fprintf(stdout, "设备上可用的常量内存总量: %lu bytes\n", device_prop.totalConstMem);
fprintf(stdout, "纹理对齐要求: %lu bytes\n", device_prop.textureAlignment);
fprintf(stdout, "是否支持设备重叠功能: %s\n", device_prop.deviceOverlap ? "Yes" : "No");
fprintf(stdout, "设备上多处理器的数量: %d\n", device_prop.multiProcessorCount);
fprintf(stdout, "执行核函数时是否有运行时间限制: %s\n", device_prop.kernelExecTimeoutEnabled ? "Yes" : "No");
fprintf(stdout, "设备是否是一个集成GPU: %s\n", device_prop.integrated ? "Yes" : "No");
fprintf(stdout, "设备是否支持映射主机内存: %s\n", device_prop.canMapHostMemory ? "Yes" : "No");
fprintf(stdout, "CUDA设备计算模式: %d\n", device_prop.computeMode);
fprintf(stdout, "一维纹理支持的最大大小: %d\n", device_prop.maxTexture1D);
fprintf(stdout, "二维纹理支持的最大大小(x,y): (%d, %d)\n", device_prop.maxTexture2D[0], device_prop.maxSurface2D[1]);
fprintf(stdout, "三维纹理支持的最大大小(x,y,z): (%d, %d, %d)\n",
device_prop.maxTexture3D[0], device_prop.maxSurface3D[1], device_prop.maxSurface3D[2]);
fprintf(stdout, "内存时钟频率峰值: %.0f Mhz\n", device_prop.memoryClockRate * 1e-3f);
fprintf(stdout, "全局内存总线宽度: %d bits\n", device_prop.memoryBusWidth);
fprintf(stdout, "L2缓存大小: %d bytes\n", device_prop.l2CacheSize);
fprintf(stdout, "每个多处理器支持的最大线程数量: %d\n", device_prop.maxThreadsPerMultiProcessor);
fprintf(stdout, "设备是否支持同时执行多个核函数: %s\n", device_prop.concurrentKernels ? "Yes" : "No");
fprintf(stdout, "异步引擎数量: %d\n", device_prop.asyncEngineCount);
fprintf(stdout, "是否支持设备与主机共享一个统一的地址空间: %s\n", device_prop.unifiedAddressing ? "Yes" : "No");
}
return 0;
}
执行结果如下:
GitHub:https://github.com/fengbingchun/CUDA_Test