思路:对于输入的的字符串,只有三种可能,ipv4,ipv6,和neither
ipv4:四位,十进制,无前导0,小于256
ipv6:八位,十六进制,无多余0(00情况不允许),不为空
class Solution:
def solve(self , IP: str) -> str:
if '.' in IP: #有可能是IPV4
res = IP.split('.')
if len(res) == 4: #满足4位
for i in res:
try: #满足十进制
a = int(i)
except:
return "Neither"
else:
if len(str(int(i))) != len(i): #前导0判断
return "Neither"
elif int(i) > 255: #255判断
return "Neither"
return "IPv4" #如果没有提前盘错退出,就一定是IPV4
else:
return "Neither"
elif ':' in IP: #有可能是IPV6
res = IP.split(':')
if len(res) == 8: #满足8位
for i in res:
try: #满足16进制
a = int(i,16)
except:
return "Neither"
if i == '' or i.count('0') == len(i) and len(i) != 1 or len(i) > 4: #非空,16比特,0不多余
return "Neither"
return "IPv6"
else:
return "Neither"
else:
return "Neither"
思路:让两个指针i j,分别从两个字符串的最后一位开始向前遍历,设置进位ind,当i j都没有走到-1时,如果当前和a = i+j+ind大于9,那就res.insert(0,a-10),将ind置为1,如果当前和小于等于9,res.insert(0,a),将ind置为0.
跳出循环之后,将剩余的部分和ind继续加和,如果没有剩余,ind为1,就把ind insert到首位。
class Solution:
def solve(self , s: str, t: str) -> str:
ind = 0 #进位
i,j = len(s)-1,len(t)-1
res = []
while i >= 0 and j >= 0:
a = int(s[i]) + int(t[j]) + ind
if a <= 9:
res.insert(0,str(a))
ind = 0
else:
ind = 1
res.insert(0,str(a-10))
i -= 1
j -= 1
if i == -1:
while j >= 0: 继续遍历剩下的
a = int(t[j]) + ind
if a <= 9:
res.insert(0,str(a))
ind = 0
else:
ind = 1
res.insert(0,str(a-10))
j -= 1
if j == -1:
while i >= 0: 继续遍历剩下的
a = int(s[i]) + ind
if a <= 9:
res.insert(0,str(a))
ind = 0
else:
ind = 1
res.insert(0,str(a-10))
i -= 1
if i == -1 and j == -1 and ind != 0: #还有进位
res.insert(0,str(ind))
return ''.join(res)
思路:先将区间按照start进行排序(从小到大),从前往后遍历区间[1,len-1],当前区间和前面的区间比较,有三种可能:当前区间被前面的区间完全覆盖,当前区间start在前一个区间内,end超出了前一个区间。这两种情况都可以直接更新当前的区间i.start = min(i-1.start,i.start),i.end = max(i-1.end,i,end)。最后一种情况是当前区间的start比前一个区间的end大,两个区间不重复,这种情况下就把前一个区间加入res中。(前一个区间是合并后的)。在最后将最后一个区间加入res。
class Solution:
def merge(self , intervals: List[Interval]) -> List[Interval]:
intervals = sorted(intervals,key=lambda x: x.start) #排序
res = []
if len(intervals) <= 1: #特殊判断
return intervals
i = 1
while i < len(intervals):
if intervals[i].start <= intervals[i-1].end: #更新区间
intervals[i].start = min(intervals[i-1].start,intervals[i].start)
intervals[i].end = max(intervals[i-1].end,intervals[i].end)
else: #加入res
res.append(intervals[i-1])
i += 1
res.append(intervals[len(intervals)-1])
return res

思路:用双指针(滑动窗口)和哈希表来做。首先进行特殊判断:如果len(T)>len(S)或者len(T)是空或者len(S)是空,以及T中有元素不在S中,都要输出空。
然后left=0,right=1开始遍历字符串,如果当前S[left:right]包含的每一个key(T中的字符串)的数量都大于等于d[key],就找到了一个符合的子串,left+=1,查看答案ans与right-left+1比较大小,如果小就更新ans。如果窗口不符合,先判断right是否到达了len(S),如果没到达就更新right+=1,到达后,就更新left+=1来改变窗口。
import collections
class Solution:
def minWindow(self , S: str, T: str) -> str:
d1 = collections.Counter(S) #都改成哈希表查找会更快
d2 = collections.Counter(T)
res = [i for i in d2 if i not in d1]
if len(res) or len(S) == 0 or len(T) == 0 or len(T) > len(S): #特殊判断
return ''
left,right = 0,1
ans = S #答案最开始用较长字符串表示
while right > left:
if all(S[left:right].count(key) >= d2[key] for key in d2): #符合的子串窗口出现
if right-left+1 <= len(ans): #判断与答案的大小
ans = S[left:right]
left += 1 #更新窗口
else:
if right < len(S):
right += 1
else:
left += 1
return ans
思路:双指针,滑动窗口,如果当前arr[right]在arr[left:right]中,就更新答案,然后移动左指针,如果不在,就移动右指针。最后要考虑一个情况,就是right一直不在,到len(arr)-1后退出循环,所以在返回前,要再次更新ans = max(ans,right-left)。
class Solution:
def maxLength(self , arr: List[int]) -> int:
if len(arr) <= 1:
return len(arr)
left,right = 0,1
ans = 0
while right < len(arr):
if arr[right] not in arr[left:right]:
right += 1
else:
ans = max(ans,right-left)
left += 1
ans = max(ans,right-left)
return ans

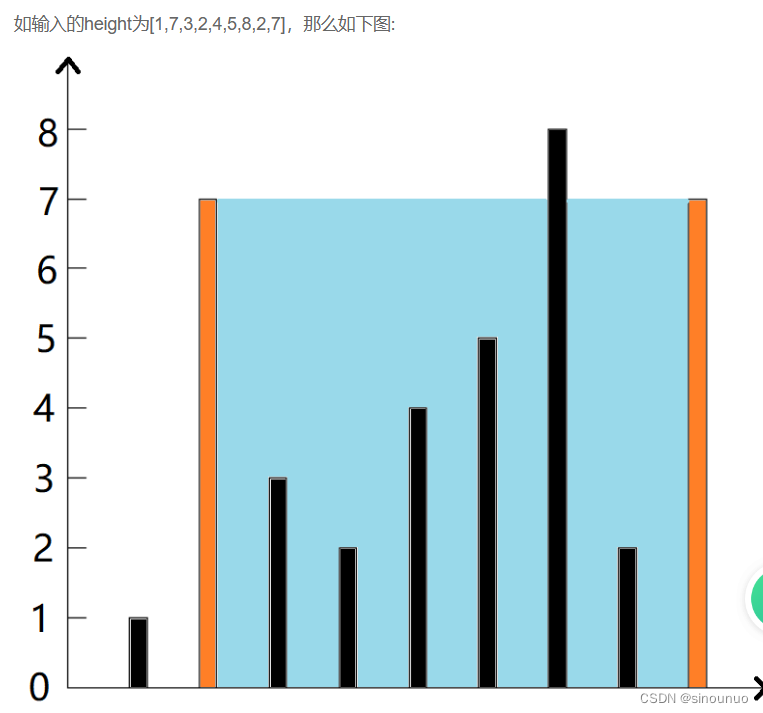
思路:使用贪心算法求解,我们想要求最大的面积,所以要么底边比较大,要么高度高。用相对指针先保证底边最大,然后向里移动,每次移动较小的值,保证长边被保留下来。每次都计算area,并且更新ans。
class Solution:
def maxArea(self , height: List[int]) -> int:
if len(height) < 2: #特殊情况判断
return 0
area = 0
ans = 0
left,right = 0,len(height)-1 #相对指针
while left < right:
area = (right-left)*(min(height[left],height[right])) #计算面积更新答案
ans = max(ans,area)
if height[left] < height[right]: #每次都移动较小的边长
left += 1
else:
right -= 1
return ans

思路:相向双指针,先确定两个边界p1,p2,移动较小边界,如果当前值小于该边界,ans+=差值。如果大于,就更新边界。当left == right时退出
class Solution:
def maxWater(self , arr: List[int]) -> int:
if len(arr) <= 2: #特殊判断
return 0
left,right = 0,len(arr)-1 #相向双指针
ans = 0
p1,p2 = arr[left],arr[right] #设置边界
while left < right:
if p1 < p2: #移动较小的边界
left += 1
if p1 >= arr[left]: #如果当前边界大于当前值,更新ans
ans += p1 - arr[left]
else: #否则更新边界
p1 = arr[left]
else:
right -= 1
if p2 >= arr[right]:
ans += p2 - arr[right]
else:
p2 = arr[right]
return ans
思路:用dp存储每个孩子的糖数,初始化为1,遍历第一遍(从左到右),如果i > i-1那么更新dp[i] = dp[i-1]+1。然后遍历第二遍,如果i > i+1那么更新dp[i] = dp[i+1]+1。最后计算dp的和。
class Solution:
def candy(self , arr: List[int]) -> int:
if len(arr) <= 1: #特殊判断
return len(arr)
dp = [1]*len(arr) #初始化
for i in range(1,len(arr)): #第一次遍历,如果右边比左边大,就更新dp
if arr[i] > arr[i-1]:
dp[i] = dp[i-1] + 1
for i in range(len(arr)-2,-1,-1): #第二次遍历,如果左边比右边大,而且左边的糖果比右边小
if arr[i] > arr[i+1] and dp[i] <= dp[i+1]:
dp[i] = dp[i+1] + 1
return sum(dp)
class Solution:
def minmumNumberOfHost(self , n: int, startEnd: List[List[int]]) -> int:
if n <= 1:
return n
start = [i[0] for i in startEnd]
end = [i[1] for i in startEnd]
start.sort() #排序
end.sort()
j = 0
res = 0
for i in range(n):
if start[i] >= end[j]: #开始的时间比上一个结束的时间大
j += 1
else:
res += 1
return res
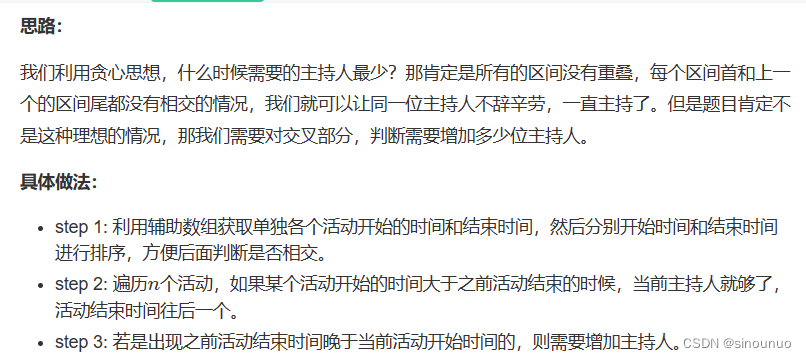
我们是要看有没有区间重叠,如果当前增加了主持人,就可以多一个开始时间,但是依旧要看新的开始时间是否和之前的结束时间重叠。(所以增加主持人的时候j不动)
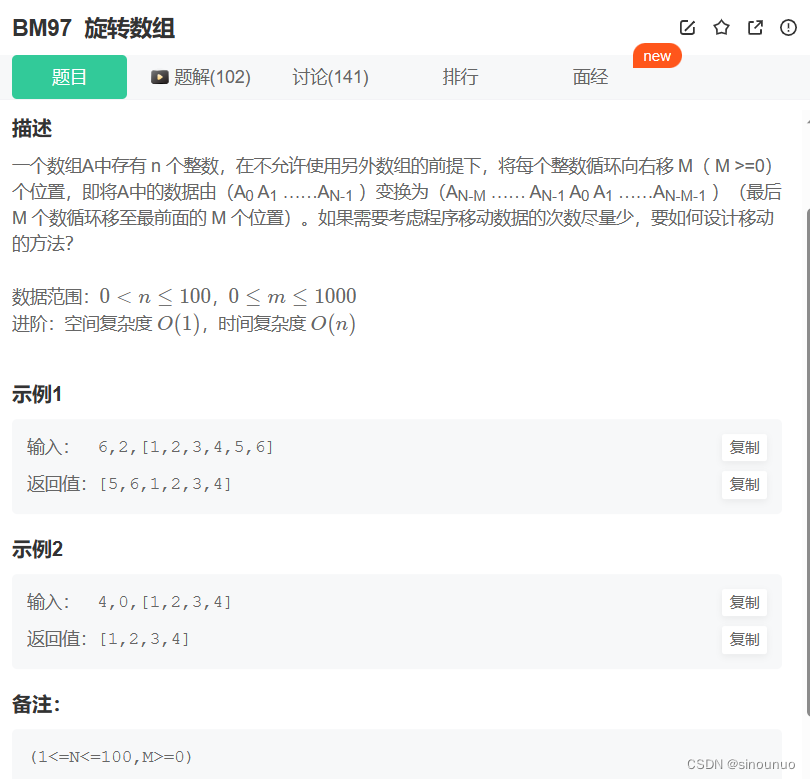
class Solution:
def solve(self , n: int, m: int, a: List[int]) -> List[int]:
if m % n == 0:
return a
else:
x = m%n
a = a[n-x:] + a[:n-x]
return a
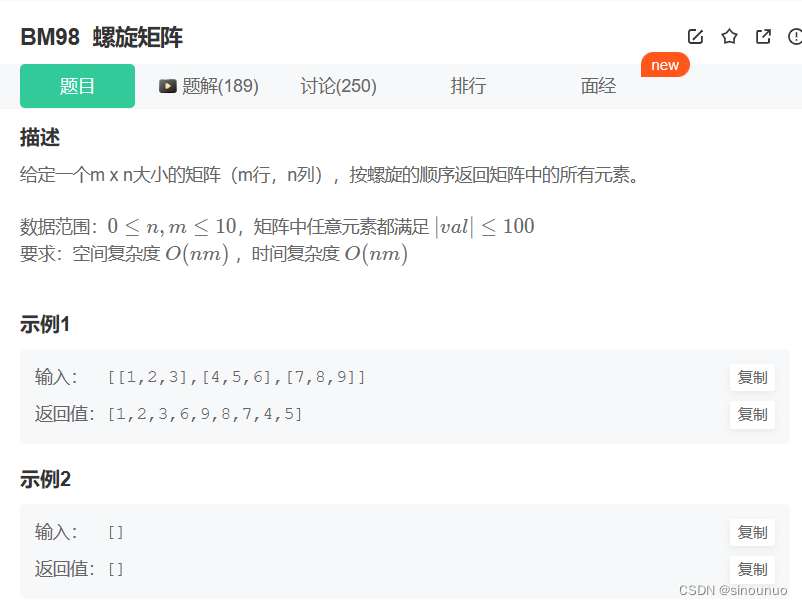
思路:设置上下左右的边界值,然后开始遍历,从左到右遍历一次,更新up的值,然后判断当前是否还有行:up <= down,然后从上到下遍历,更新right值,之后判断当前时候还有列:left <= right。接着从右往左遍历,更新下边界值,从下往上遍历更新左边界值。跳出循环的条件是左>右,上>下。
class Solution:
def spiralOrder(self , matrix: List[List[int]]) -> List[int]:
n = len(matrix)
if n <= 0:
return []
m = len(matrix[0])
if m <= 0:
return []
ans = []
up,down,left,right = 0,n-1,0,m-1 #设置边界值
while up <= down and left <= right:
#从左到右
for i in range(left,right+1):
ans.append(matrix[up][i])
up += 1 #更新上边界
#从上到下
if up <= down: #保证还有行
for i in range(up,down+1):
ans.append(matrix[i][right])
right -= 1 #更新右边界
if left <= right: #保证还有列
#从右到左
for i in range(right,left-1,-1):
ans.append(matrix[down][i])
down -= 1 #更新下边界
#从下到上
for i in range(down,up-1,-1):
ans.append(matrix[i][left])
left += 1 #更新左边界
return ans
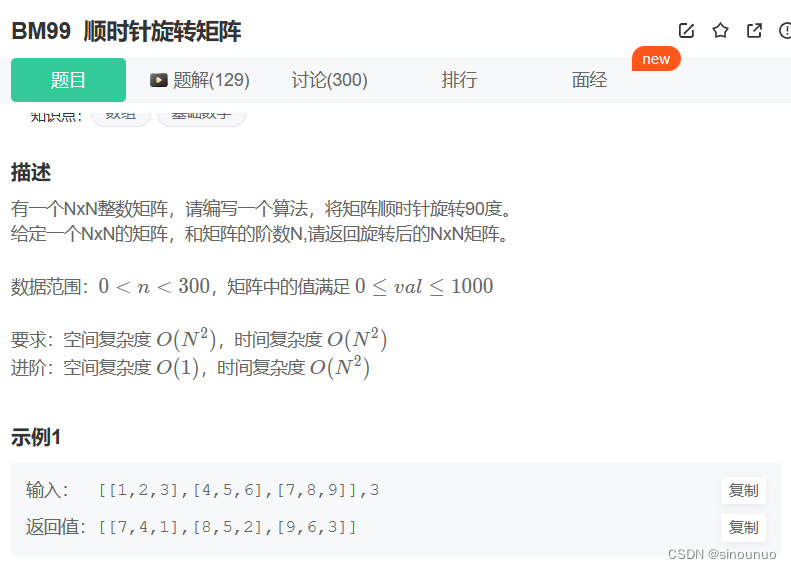
思路:取第一列元素,反转之后作为新数组的第一行。
class Solution:
def rotateMatrix(self , mat: List[List[int]], n: int) -> List[List[int]]:
res = []
m = len(mat[0]) #列
for i in range(m): #遍历列
a = []
for j in range(n): #遍历行
a.append(mat[j][i])
res.append(a[::-1])
return res
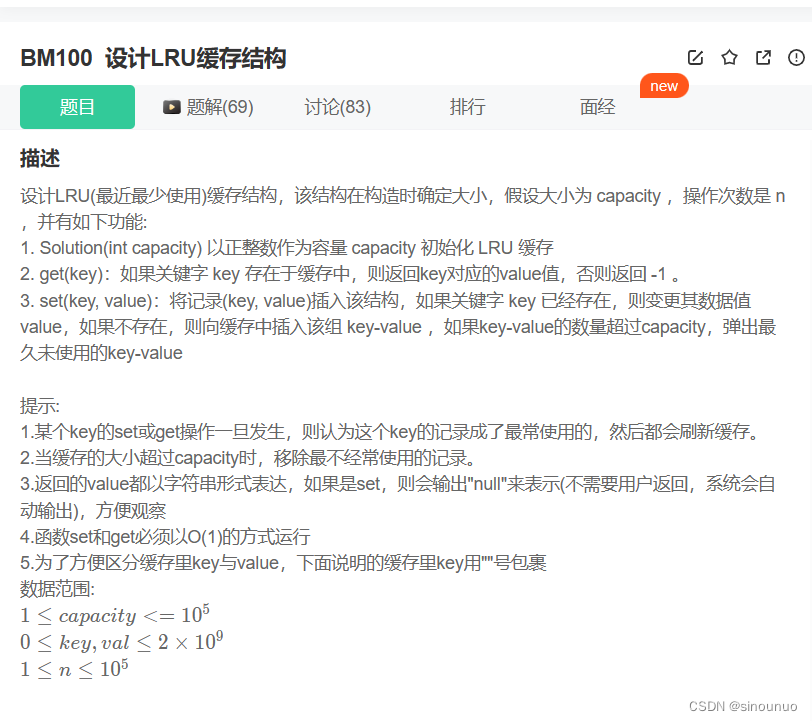
思路:最近最少使用一般用链表或者栈来实现,如果访问或者更新键值对的时候,就先把原来的删掉,把key插入到队头,每次队满之后,直接pop掉队尾。
class Solution:
def __init__(self, capacity: int):
self.res = {} #存储键值对
self.lenght = capacity #缓存结构大小
self.stack = [] #存储键值对的使用频率
def get(self, key: int) -> int:
if key in self.res: #如果key在缓存中,更新stack,然后返回value
self.stack.remove(key)
self.stack.insert(0,key)
return self.res[key]
else: #否则返回0
return -1
def set(self, key: int, value: int) -> None:
if key in self.res: #如果key值在缓存中,更新缓存值,然后更新stack
self.res[key] = value
self.stack.remove(key)
self.stack.insert(0,key)
else: #不在要新增数据
if len(self.stack) == self.lenght: #如果当前缓存满了
a = self.stack.pop() #弹出栈顶
del self.res[a] #删除缓存
self.stack.insert(0,key) #更新stack和res
self.res[key] = value
思路:两个哈希表。key_freq = {key:freq}存储出现的key的次数。缓存cache = {freq:{key:value}}
然后使用minfreq来记录当前的最小次数,如果当前的freq==minfreq并且cache中这个freq的长度已经为0,此时更新最小minfreq+1.
这里要用到两个colletions的内置字典,defaultDict和orderedDict。oderedDict是按照key的插入顺序对key进行的排序。可以pop(key),popitem(last = False)将会弹出第一个key,这个就是最小的使用频率下最久不适用的键值。默认是last = True
弹出最后一个键值对。
import collections
class LFU:
def __init__(self,k) -> None:
self.key_freq={} # 记录key值和当前key出现的频率
self.cache=collections.defaultdict(collections.OrderedDict)# 出现频率:{key:value}
self.lenght = k
self.minfreq = 0 #当前最小频率
def set(self,key,value):
if key in self.key_freq: #存在就更新值,使用次数增加
freq = self.key_freq[key] #取该key的出现频率
self.cache[freq].pop(key) #在cache对应的频率中删除这个key
self.key_freq[key] += 1 #频率加一
self.cache[freq+1][key] = value #修改cache,让频率+1的键值放入键值对
if self.minfreq == freq and len(self.cache[freq]) == 0: #是否要修改最小频率
self.minfreq += 1
else:
if self.lenght == len(self.key_freq): #已满,淘汰
delkey,delvalue = self.cache[self.minfreq].popitem(last=False) #删第一个键值对
self.key_freq.pop(delkey)
#插入
self.key_freq[key] = 1 #第一次出现
self.cache[1][key] = value
self.minfreq = 1
def get(self,key):
if key in self.key_freq:
freq = self.key_freq[key]
val = self.cache[freq].pop(key)
self.key_freq[key] += 1
self.cache[freq+1][key] = val
if freq == self.minfreq and len(self.cache[freq])==0: #修改最小频率
self.minfreq += 1
return val
else:
return -1
class Solution:
def LFU(self , operators: List[List[int]], k: int) -> List[int]:
ans = []
a = LFU(k)
for i in operators:
if i[0] == 1:
a.set(i[1],i[2])
else:
ans.append(a.get(i[1]))
return ans