注:无论是任何一门语言,刚开始入门的时候,语言运行环境的搭建都是一件不轻松的事情。
Python的运行环境
要运行或写Python代码,就需要Python的运行环境,主要的Python有以下三类:
- 原生态的Python:就是直接从Python的官网下载,然后安装使用。这类方法最简单直接,但是后期不容易维护;
- 一些其他类型的Python发行本:这种类型的Python一般与一些package和其他工具整合在一起,类似于定制版的Python,易于安装和使用,例如用的比较多的Anaconda发行版;
- 使用docker来提供Python的运行环境:使用该方法,不用在自己电脑上直接安装Python的,只用在docker中构建好相应的Python的image就好了。
回想自己使用Python的过程,一开始也是直接到Python的官网上下载最新版本的安装包。安装完Python后,添加环境变量,在cmd中用pip一个一个安装需要使用的package。每次都是重复这样的过程,有时候会遇到一些莫名其妙的问题,比如某些package无法安装成功;有时候只能下源码自己编译安装。有时候还会需要不同版本的Python,电脑里就会出现多个版本的Python。
现在后面两类方法用的比较多。
关于开发环境
还记得有段时间接触到Java,一直分不清楚JRE和JDK的区别。现在终于搞明白了,JRE是运行是Java运行环境(Java Runtime Environment),可以用来运行Java的代码;JDK是Java开发工具包(Java Developer's Kit),即Java的开发环境,主要用来写代码。
写代码时,有一个好的集成开发环境(integrated development environment,IDE)会让我们事半功倍,包括但不限于以下这些优点:
- 语法检查;
- 提示及命令补全;
- 好看的配色和字体;
- 强大的debug功能;
- 对大型project的管理功能。
我用的比较多的IDE包括:PyCharm,Spyder和Jupyter notebook.
- PyCharm在开发大型项目时是首选,但是平时分析数据时就显得有些笨重了;
- Spyder主要用于科学计算(与RStudio非常像,可以单行运行);但是对内存要求比较大,数据量比较大的时候容易崩溃;
- Jupyter notebook算是新生代的数据科学界的IDE,非常适合做数据分析。
Anaconda发行版
Anaconda是一种Python语言的免费增值开源发行版,用于进行大规模数据处理, 预测分析, 和科学计算, 致力于简化包的管理和部署。Anaconda使用软件包管理系统Conda进行包管理。——wiki
上面是wiki中对Anaconda Python发行版的介绍,其特点就是:为数据科学而定制的版本,利用conda来管理package比原生态的pip更方便。
完整版本的Anaconda
完整版本的Anaconda比较大,最新版的600多兆(windows, 64-Bit, Python3.6),该版本不仅包括Python,还有预装好的100多个package,省去了自己安装包的麻烦。但是体积比较大,通常很多包都用不到。
下载链接:https://www.anaconda.com/download/
Miniconda
Minicoda只包含conda, Python和少量的包,大小只有50几兆。安装好Miniconda后,可以使用conda install来安装其他python的包
下载链接:https://conda.io/miniconda.html
下面以Miniconda为例,安装和配置Python的运行环境及开发环境(windows 7, 64位)
1. 安装miniconda
打开上面的链接,下载想要安装的版本后进行安装。
更多参考安装指南:https://conda.io/docs/user-guide/install/index.html
安装完成后,在开始菜单可以看到下面的标志:
2. 安装需要的package
点击上面的Anaconda Prompt,打开anaconda的命令行工具。在这个命令行中可以直接使用conda:
- conda info:查看当前虚拟环境的名称和路径,配置文件的位置,channel的列表,Python版本等基本情况;
- conda env list: 列出所有的虚拟环境;
- conda list: 列出当前虚拟环境中已经安装的包;
- conda search packagex: 搜索包packagex,会返回不同版本的包,可以使用"packagex==x.y"来指定安装x.y版;
- conda install packagex: 安装包packagex.
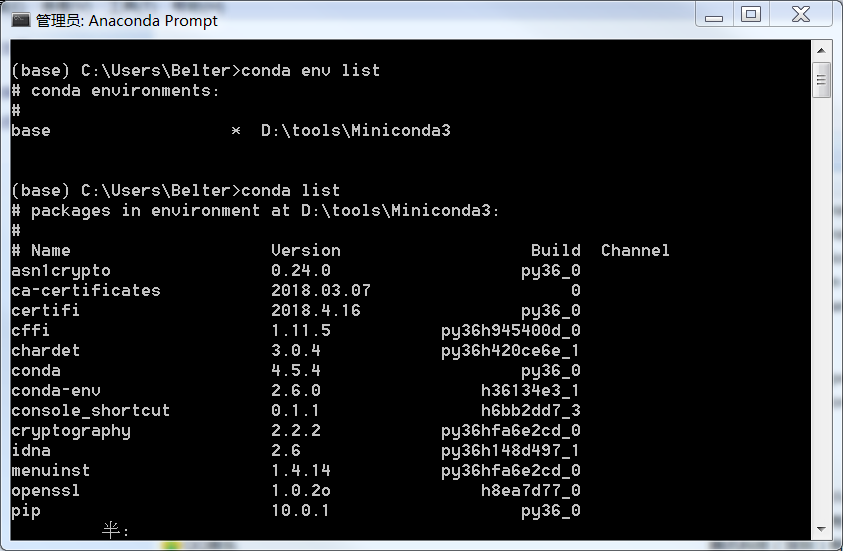
由上图可以看到,现在只有一个虚拟环境——base,在这个环境中有30个预装的包。
下面安装常用的几个用于数据分析的工具包:

指定安装0.19.1版的scikit-learn: conda install scikit-learn==0.19.1
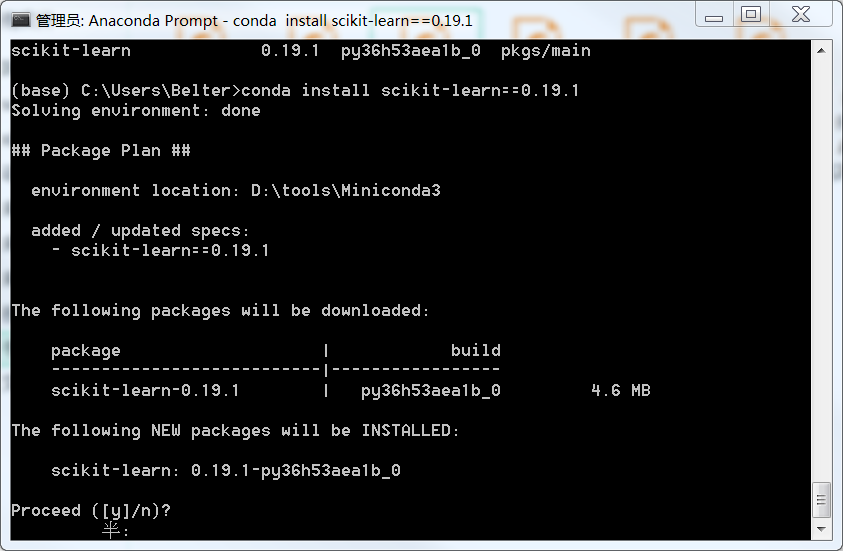
conda作为anaconda中Python包管理工具,还有其他很多功能,可参考:
https://conda.io/docs/commands.html
https://conda.io/docs/_downloads/conda-cheatsheet.pdf
3. 安装jupyter notebook
安装jupyter notebook的命令:conda install jupyter
安装后,可以看到开始菜单多了一个图标:
4. 运行jupyter notebook
使用时,可以直接从开始菜单中的"Jupyter Notebook"启动,或是在命令行中输入jupyter notebook。打开后,会在浏览器中打开一个页面:
链接默认为:http://localhost:8888/tree
界面如下:
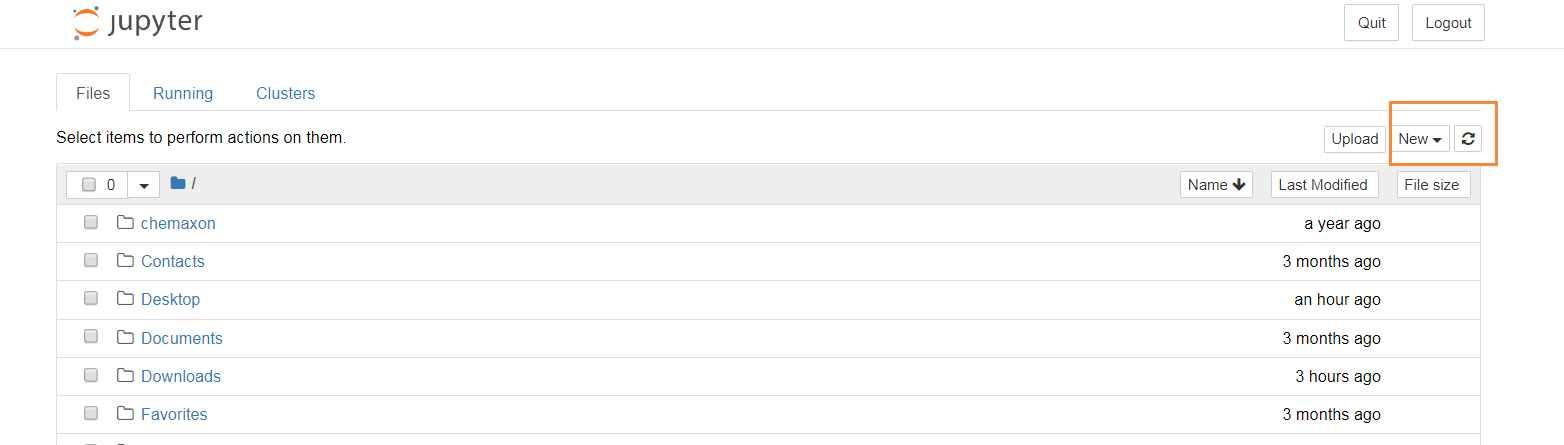
点击图中框出来的"New"菜单,选择"Python 3"就可以打开一个新的notebook
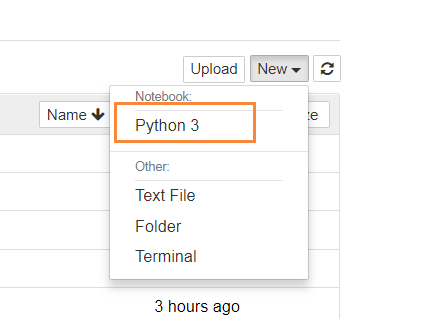
界面如下:

这时就可以写代码了!
退出时,关闭相应的cmd窗口就可以了。
Jupyter Notebook
对于Jupyter Notebook,完全值得单独拿出来说说。
jupyter notebook是一个交互式的IDE,虽然不像PyCharm这种重型IDE那么强大,但是仍然可以当做IDE来用,而且有一些特色非常适合用来进行数据分析:
- 可以单行运行代码,这样就可以一行一行的检查代码,查看运行结果,反复尝试;
- 每次运行后变量都保存在内存中,因此可以重复使用(这对于一些比较耗时的计算过程,尤其有用);
- 可以写markdown格式的注释,这样就可以将整个分析过程非常清晰的表达出来;
- 可以利用Mathjax展示数学公式;
- 可以插入图片等,可以制作出图和代码并茂的非常精致的笔记和文档(有很多已经出版的书都是完全使用notebook来写作的).
但是个人感觉jupyter notebook并不适用代码量比较大的工程类项目。
自己最近几个月一直在使用这个工具,但是还没有系统的研究过。这里先放几个链接,后面再来补充:
- 知乎上的一个介绍:https://www.zhihu.com/question/37490497/answer/212044783(你为什么使用 jupyter ,进行分析,而不是用 python 脚本或仅仅利用 excel ? - 子珂的回答)
- datacamp中介绍Jupyter Notebook的文章(包括如何运行R代码):https://www.datacamp.com/community/tutorials/tutorial-jupyter-notebook
- 另一篇文章(包括快捷键,其他注意事项等):https://www.dataquest.io/blog/jupyter-notebook-tutorial/
此外,JupyterLab:被称为下一代Jupyter,对原来的Jupyter Notebook做了很多改进。
参考文档:https://jupyterlab.readthedocs.io/en/latest/
# 安装
conda install -c conda-forge jupyterlab
# 运行
jupyter lab
由于国内使用默认channel安装包比较慢,安装时可以自己设置其他来源的channel,下面使用了南京大学的镜像:
(更多关于Anaconda 镜像的使用方法,可以参考清华大学开源软件镜像站上的使用帮助)
conda install -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/ jupyterlab
在Anaconda中,添加对R的支持
有时候需要用到R,在anaconda中安装的R默认是由微软的发行版(Microsoft R Open, MRO)
1. 安装MRO
conda create -n mro_env r-essentials # 这里创建了一个新的虚拟环境"mro_env"来安装与R相关的包
2. 安装IRkernel
安装好R的虚拟环境后,需要安装IRKernel才能在在jupyter lab中使用R。第一步结束后进行下面的操作:
conda activate mro_env # 进入新创建的虚拟环境
R # 直接输入R进入R的命令行界面,在R内部安装所需的包和IRkernel
install.packages(c('repr', 'IRdisplay', 'evaluate', 'crayon', 'pbdZMQ', 'devtools', 'uuid', 'digest'))
devtools::install_github('IRkernel/IRkernel')
3. 激活IRkernal
IRkernel::installspec()
完成以上操作之后,再使用之前的命令安装JupyterLab,就可以在JupyterLab中使用R了:
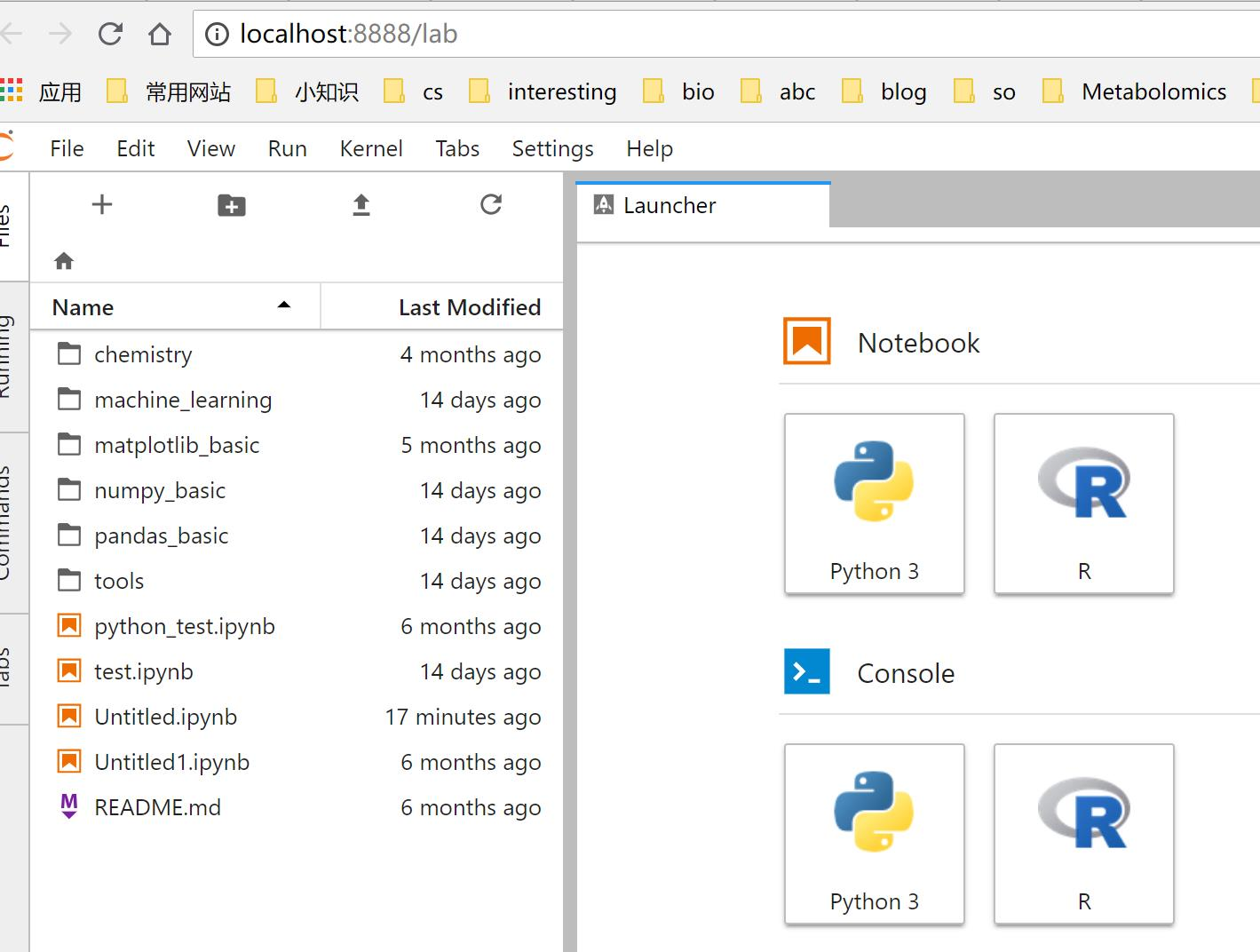
<完>