第一次运行必须带上定义:import pandas as pd,故意报错展现
pd.read_excel(1)
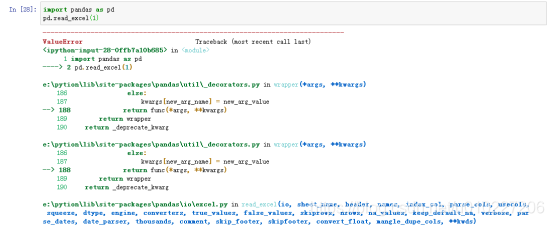
read_excel(io, sheet_name, header, names, index_col, parse_cols, usecols, squeeze, dtype, engine, converters, true_values, false_values, skiprows, nrows, na_values, keep_default_na, verbose, parse_dates, date_parser, thousands, comment, skip_footer, skipfooter, convert_float, mangle_dupe_cols, **kwds)
这函数有**kwds,函数在调用时,可以有任意数量和种类的命名参数,或者称关键字参数。这个就是决定了,pd.read_excel除了第一个路径外,后面参数顺序随便可换;
这个函数有效参数一共有26个,下文开始逐个描述,其中有3个问题,持续思考中~
Squeeze单列从Series变DataFrame的直观体现~
Thousands=","针对文本的差异如何直观体现~
mangle_dupe_cols=False的报错
整体初始模式:
read_excel(io,sheet_name=0,header=0,names=None,index_col=None,parse_cols=None,Nrows=None,usecols=None,skiprows=0,skipfooter=0,Squeeze=False,Dtype=None,Engine=None,Converters=None,true_values=None,false_values=None,na_values=None,keep_default_na=False,Verbose=False,parse_dates=False,date_parser=None,thousands=None,Comment=None,convert_float=True,mangle_dupe_cols=True)
注意:目前python中,skipfooter和skip_footer不能共存,所以上面只有25个参数。
1、io :excel路径
默认就是C:\Users\XXX XXX是用户名:pd.read_excel("test1.xlsx")


2、sheet_name:默认是sheet_name=0; 也可以使用sheetname
1)sheetname=’sheet2’ 返回指定名字的表;2)返回多表使用sheet_name=[0,1,2] 代表返回第几张,0默认第一张,0,1,2代表返回第一张、第二张、第三张;3)若sheet_name=None是返回全表。
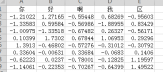



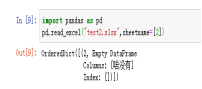

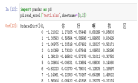

3、header :指定作为列名的行,默认header=0,即取第一行,数据为默认从这一行下面开始读取;若数据想不含列名,则设定header=None;
案例1:pd.read_excel("test2.xlsx",header=1)
案例2:pd.read_excel("test2.xlsx",header=None)
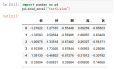

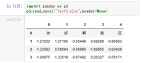
4、names要使用的列名列表,默认names=None;匹配header进行使用,会覆盖原因的表头文字。指定的名字出现重复的话,会出现.1,.2
案例1:pd.read_excel("test2.xlsx",header=0,names='54321')
案例2:pd.read_excel("test2.xlsx",header=0,names='54333')
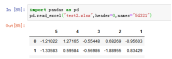
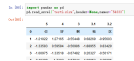
5、index_col指定列为索引列,默认index_col=None,index_col=0,选择第一列为索引
案例:pd.read_excel("test2.xlsx",index_col=0)
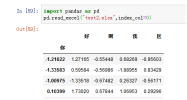
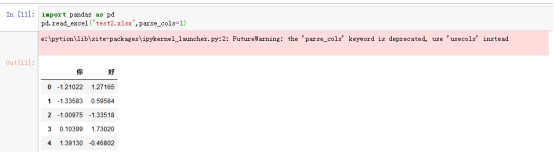
6、parse_cols,默认parse_cols=None,相关于usecols,显示多少列,None是显示全部列,parse_cols=1,显示2列
案例:pd.read_excel("test2.xlsx",parse_cols=1)
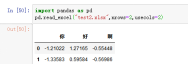
7、Nrows,8、usecols需要展示的行列数进行指定,默认Nrows=None,usecols=None,这里意思就是展示全部的有数据的行和列,nrows=2,usecols=2,意思就是需求2行,3列
案例:pd.read_excel("test2.xlsx",nrows=2,usecols=2)
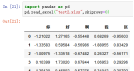
9、skiprows省略指定行数的数据,默认skiprows=0,从表头开始省略的行数,表头也算是数据。
案例:pd.read_excel("test2.xlsx",skiprows=1)
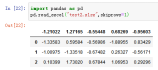

10、skipfooter省略从尾部数的行数据,默认skipfooter=0,设置0就是省略0行。
11、skip_footer是一样的
案例:pd.read_excel("test2.xlsx",skipfooter=28)
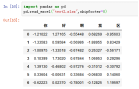


12、Squeeze,如果文件值包含一列,则返回一个Series,默认Squeeze=False;这里及哪怕只有一列也是按照默认的输出为dataframe,Squeeze=True,在只有一列的时候就是为Series;
#Pandas各个数据类型的关系:0维单值变量->1维Series->2维DataFrame->3维层次化
#Time- Series:以时间为索引的Series,它是由index(索引)和value(数值)组成
#DataFrame:二维的表格型数据结构。很多功能与R中的data.frame类似。
#Panel :三维的数组,可以理解为DataFrame的容器。
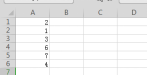
针对只有1列的案例如下,但是实际的直观差异需要进一步跟进。
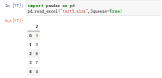
案例:pd.read_excel("test3.xlsx",Squeeze=True)
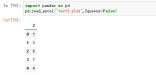
13、Dtype,每列数据的数据类型。例如 {‘a’: np.float64, ‘b’: np.int32},默认Dtype=None;也就是按照初始的数据类型进行输出;这里需要匹配np,需要额外定意思import numpy as np
这里把第一类的类型进行了改变
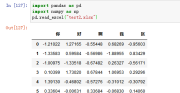
案例:pd.read_excel("test2.xlsx",dtype={'你':np.int32,'好':np.float64,'啊':np.float64,'我':np.float64,'区':np.float64})
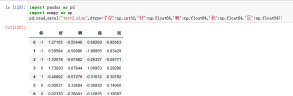
14、Engine,使用的分析引擎。可以选择C或者是python。C引擎快但是Python引擎功能更加完备。默认Engine=None;就是使用python。
案例:pd.read_excel("test2.xlsx",Engine="C")


15、Converters,在某些列中转换值的函数的命令默认Converters=None;也就是不进行转化。这个可以是公式转换,也可以是字符类型转化,默认的数字是int格式,案例改为tsr。
#Python的数字类型有int整型、long长整型、float浮点数、complex复数、以及布尔值(0和1)
#对于布尔值,只有两种结果即True和False,其分别对应与二进制中的0和1。
#文本类型str类。
案例:pd.read_excel("test7.xlsx",converters={'str':str})
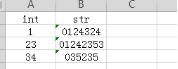
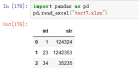
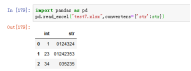
16、true_values,指定字符变为true,默认true_values=None,默认没有字符转化为true
17、false_values,指定字符变为false,默认false_values=None,默认没有字符转化为true
18、na_values,指定字符变为NaN,默认false_values=None,默认没有字符转化为NaN
这3个模块可以一起理解。
案例pd.read_excel("test4.xlsx",true_values='你',false_values='好',na_values='无')
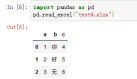
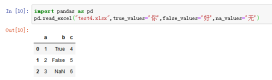
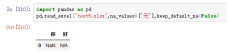
19、keep_default_na,如果指定na_values参数,并且keep_default_na=False,那么默认的NaN将被覆盖,否则添加。默认keep_default_na=True;默认不会被新定义的NaN影响默认的NaN规则
默认的NaN定义'-1.#IND', '1.#QNAN', '1.#IND', '-1.#QNAN', '#N/A N/A','#N/A', 'N/A', 'NA', '#NA', 'NULL', 'NaN', '-NaN', 'nan', '-nan', ''转换为NaN
案例pd.read_excel("test5.xlsx",na_values=['无'],keep_default_na=False)



20、Verbose,是否显示各种解析器的输出信息,例如:“在非数字列中显示插入的na值的数目”等。默认Verbose=False;默认不显示,python默认使用紧凑的正则表达式(即普通的正则表达式),但为了提高正则表达式的可读性,我们可以使用松散的。这个模块主要是意思理解。
21、parse_dates,分析日期,默认=False;也就是不分析日期,适用于表格里面没有日期的。如果为true,需要指定将哪一列解析为时间索引。如果列或索引包含不可分析的日期,则整个列或索引将作为对象数据类型原封不动地返回。对于非标准的日期时间分析,请在pd.read_excel之后使用pd.to_datetime。注意:对于ISO8601格式的日期,存在一个快速路径。
[1, 2, 3] -> 解析1,2,3列的值作为独立的日期列;
[[1, 3]] -> 合并1,3列作为一个日期列使用dict,
{‘foo’ : [1, 3]} -> 将1,3列合并,并给合并后的列起名为"foo"
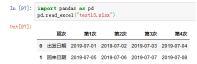
案例1:pd.read_excel("test13.xlsx",parse_dates=['第1次'])
案例2:pd.read_excel("test13.xlsx",parse_dates=[['第1次','第2次']])
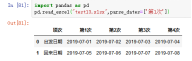
案例3:pd.read_excel("test13.xlsx",parse_dates={'foo':['第1次','第3次']})


22、date_parser,日期分析器,默认=None;也就是不开启,适用于表格里面没有日期的。用于解析日期的函数,默认使用dateutil.parser来做转换。dateutil.parser 顾名思意 就是与日期相关库里的一个日期解析器,能够将字符串转换为日期格式,我们来看看具体的用法。
需要在线安装 pip install python-dateutil;一般要分析的情况下,就开启就可以了。
案例:pd.read_excel("test13.xlsx",date_parser=True)

23、Thousands,设置默认的数字千分符号,默认thousands =None;默认不设置。此参数仅对Excel中存储为文本的列是必需的,无论显示格式如何,都将自动分析任何数值列,这里读取excel的时候,不管excel有没有千分符,都会默认无。
数据格式的展示
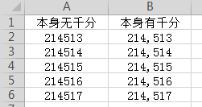
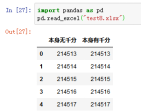
案例:pd.read_excel("test12.xlsx",Thousands=",")
但是好像没有直接的明显差异,需要持续跟进
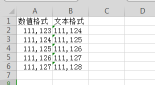

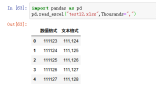
24、Comment,标识着多余的行不被解析。如果该字符出现在行首,这一行将被全部忽略。这个参数只能是一个字符,空行;默认Comment=None。表示不按照这个方式忽略
案例:pd.read_excel("test11.xlsx",comment='#')

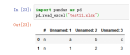
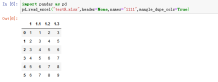
25、convert_float,转换浮点数,默认convert_float=True ;将整数浮点转换为int(即1.0–>1)将整数浮点转换为int(即1.0–>1)。如果为False,则所有数值数据都将作为浮点数读取:Excel将所有数字作为浮点数存储在内部。
案例:pd.read_excel("test10.xlsx",convert_float=False)




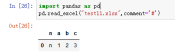
26、mangle_dupe_cols,默认mangle_dupe_cols=True;则重复列将指定为“x.0”…“x.n”,如果设定为false则会将所有重名列覆盖,但是实际测试会报错!



此处可能是Pandas包的问题,持续跟进~
直接读取和设置True均正常
案例:pd.read_excel("test9.xlsx",mangle_dupe_cols=True)
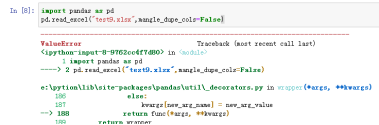
换个思路,自己设置标题,也是一样
案例:pd.read_excel("test9.xlsx",header=None,names="1111",mangle_dupe_cols=False)

参考资料:https://blog.csdn.net/u010801439/article/details/80052677