本文主要介绍层次聚类法的基本原理、距离计算方法、算法的优缺点,以及R语言实战。
一、概述
层次聚类(Hierarchical Clustering)试图在不同层次上对数据集进行划分,从而形成树形的聚类结构。数据集的划分可采用“自底向上”的聚合策略和“自顶向下”的分裂策略。分裂方法一个很大的问题是如何把一个大簇分成几个较小的簇。N个对象的集合可以划分成两个互斥的
2n−1−1
种方法,当n很大时,计算量是非常大的,因此分裂方法通常采用启发式方法进行划分,但是导致结果不准确,而且为了效率,分裂方法不对已经做出的划分决策回溯。由于这些原因,聚合方法一般比分裂方法用的多。本文也将主要介绍聚合层次聚类。
AGNES(AGglomerative NESting)是一种采用自底向上聚合的层次聚类算法。其原理为:开始将每个样本看作一个初始聚类簇,然后将距离最近的两类合并成一个新类,计算新类与其他类的距离;重复进行最近两个类的合并,直至所有的样本都聚成一个类。
二、距离计算
从上述算法原理中可以看出算法的关键在于如何计算聚类簇之间的距离。给定聚类簇
Ci
与
Cj
,有以下几种常用的方法计算距离:

其中,最小距离由两个簇的最近样本决定,最大距离由两个簇的最远样本决定,平均距离由两个簇的所有样本共同决定。当簇类间距离由最小距离、最大距离和平均距离计算时,AGNES算法被相应的称为“单链接”、“全链接”和“均链接”算法。
除此之外,还有中间距离法、重心法、离差平方和法(Ward方法)等距
离计算方法,在此不一一展开。
三、优缺点
1.优点
- 可以通过设置不同的相关参数值,得到不同粒度上的多层次聚类结构;
- 不需要事先设定好类的个数,常常可以用作其他聚类算法的前期探索。
2.缺点
- 计算量比较大,因为要每次都要计算多个cluster内所有数据点的两两距离;
- 层次聚类过程最明显的特点就是不可逆性,由于对象在合并或分裂之后,下一次聚类会在前一次聚类基础之上继续进行合并或分裂,也就是说,一旦聚类结果形成,想要再重新合并来优化聚类的性能是不可能的;
- 聚类结果过度依赖于建模过程中距离计算方法的选择,也就是说,不同的距离计算方法会造成结果的极大差异性,往往需要多次试探,选择最优结果。
四、实例
1.R语言函数介绍
在R语言中,
hclus()
函数提供层次聚类的计算,
plot()
函数可画出系统聚类的树形图(又称谱系图)。
rect.hclust()
函数则可以在谱系图中清晰的画出分类。具体用法如下:
hclust(d,method="complete",members=NULL)
其中d是由“dist”构成的距离结构,method是系统聚类的方法,缺省值是最长距离法,其参数有:
- single–最短距离法
- complete–最长距离法
- median–中间距离法
- mcquitty–Mcquitty相似法
- average–类平均法
- centroid–重心法
plot(x,labels=NULL,hang=0.1,axes=TRUE,frame.plot=FALSE,ann=TRUE,main=“ClusterDendrogram”,sub=NULL,xlab=NULL,ylab=“Height”,…)
其中x是由hclust()函数生成的对象,hang是表明谱系图中各类所在的位置,当hang取负值时,谱系图中的类从底部画起。
rect.hclust(tree,k=NULL,which=NULL,x=NULL,h=NULL,border=2,cluster=NULL)
其中tree是由hclust生成的结构,k是类的个数。
2.R语言实战
本文采用iris数据集进行聚类,由于层次聚类法用R语言实现比较简单,直接上代码。
#生成距离矩阵
d <- dist(iris[, 1:4])
#建模,这里采用中间距离法
hc <- hclust(d, method = "median")
#可视化聚类结果
plot(hc)
rect.hclust(hc, k=3)
#将聚类结果与源数据集进行比较
result <- cutree(hc, k=3) #用来将聚类结果读取出来
table(result, iris$Species)
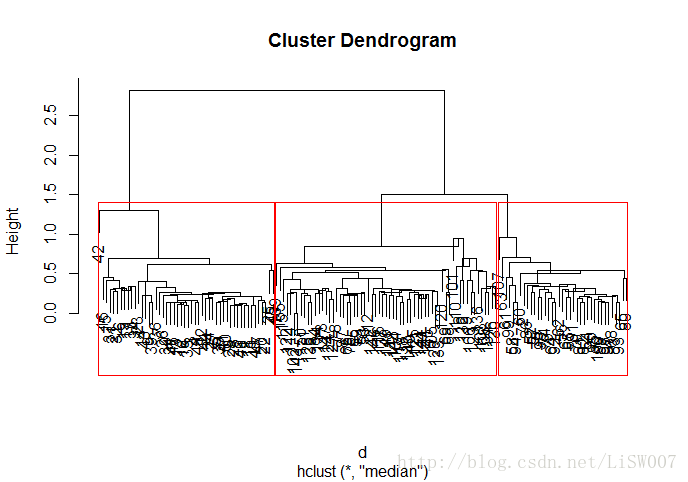
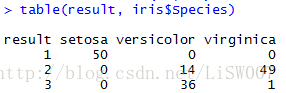
从聚类结果可以看出,结果基本与原种属一致。如果在没有样本标注的情况下,可以以聚类结果为参考,进行后续的分类。
参考资料:
【1】周志华.机器学习[M].北京:清华大学出版社,2016.
【2】统计建模与R软件,ISBN:9787302143666,作者:薛毅
【3】R语言的三种聚类方法
【4】聚类分析-R语言
【5】层次聚类的介绍