一、Xpath语法
xpath是一门在XML文档中查找信息的语言
1、 节点(Node)
元素、属性、文本、命名空间、文档(根)节点
2、 节点关系
父(parent)
子 (Children)
同胞 (Sibling)
先辈 (Ancestor)
后代 (Descendant)
3、 xpath语法
| 表达式 | 描述 |
|---|
| nodename | 选取此节点的所有子节点 |
| // | 从任意子节点中选取(第一级) |
| / | 从根节点选取(下级) |
| . | 选取当前节点(同级) |
| … | 选取当前节点的父节点(上级) |
| @ | 选取属性 |
4、 获取信息
text():获取文本信息
[last()-1]:倒数第二个,即最后一个 - 1
@class:选取class属性
position()<5:选取前4个
5、 解析器比较
| 解析器 | 速度 | 难度 |
|---|
| re | 最快 | 难 |
| BeautifulSoup | 慢 | 非常简单 |
| lxml | 快 | 简单 |
6、Xpath练习
from lxml import etree
import requests
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
selector = etree.HTML(html_doc)
links = selector.xpath('//p[@class="story"]/a/@href')
for link in links:
print(link)
r = requests.get('http://iguye.com/books.xml')
se = etree.HTML(r.text)
print(se.xpath('book'))
print(se.xpath('//book'))
print(se.xpath('//bookstore/book/author/text()'))
print(se.xpath('//bookstore/book/title/@lang'))
print(se.xpath('//bookstore/book[1]/title/text()'))
print(se.xpath('//bookstore/book[last()]/title/text()'))
print(se.xpath('//bookstore/book[last()-1]/title/text()'))
print('前2本书',
se.xpath('//bookstore/book[position()<3]/title/text()'))
print('分类为web的书本', se.xpath('//book[@category="web"]/title/text()'))
print('价格大于30.00元的书本', se.xpath('//book[price>35.00]/price/text()'))
print('类名中包含book的书本', se.xpath('//book[contains(@class, "book")]/@class'))
二、Scrapy框架的认识
在掌握了一定的爬虫基础之后,我们就可以使用一些框架来快速搭建起我们的爬虫程序,Scrapy就是一个非常搞笑的爬虫框架。
1、scrapy引擎工作流程
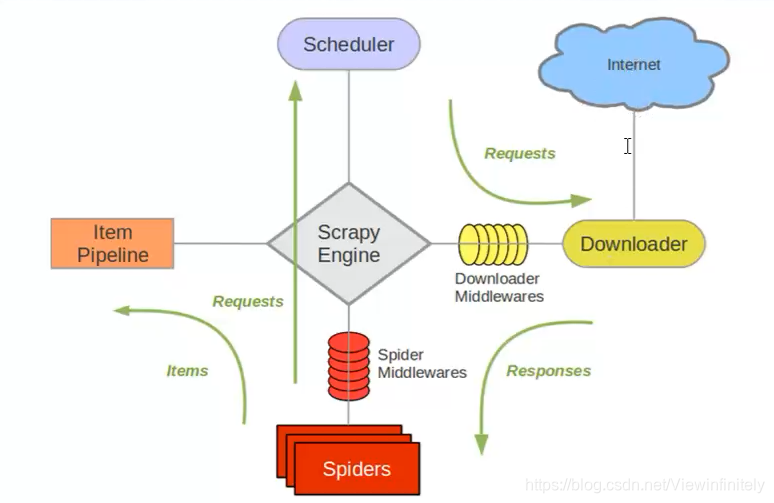
2、名词解释
Downloader (下载器):负责下载Scrapy Engine (引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎), 由引擎交给Spider来处理。
Spider (爬虫) :它负责处理所有Responses, 从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares (下载中间件):可以当作是一一个可以自定义扩展下载功能的组件。
Spider Mi ddlewares(Spider中间件):可以理解为是一- 个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)。
3、制作一个Scrapy爬虫项目的步骤
1)安装Scrapy:pip install scrapy
2)创建项目:在终端输入,scrapy startproject tencentSpider,这里的项目名为tencentSpider
3)进入到项目中:cd tencentSpider
4)创建爬虫:scrapy genspider tencent career.tencent.com
这里的爬虫名为tencent,将来要访问的域名为career.tencent.com
5)运行爬虫:scrapy crawl tencent
这样一个基本的爬虫项目就完成了
4、利用Scrapy抓取数据,我们需要修改以下文件
settings.py:设置
注释了Robots协议;打开了Headers选项并设置了UA;打开了PIPELINES(用来保存文件的)
pipelines.py:保存的逻辑
tencent.py:抓取页面信息和继续跳转的设置
items.py:保存item的映射
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)