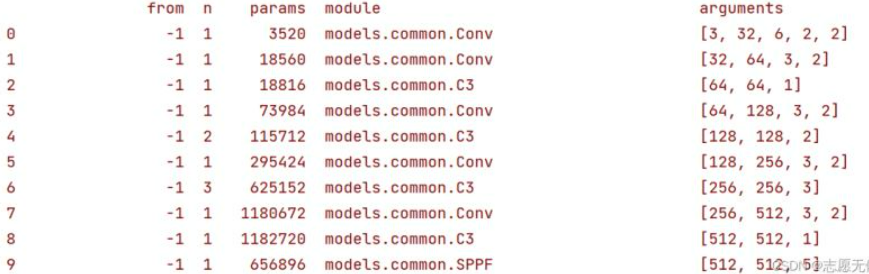
Backbone概览及参数
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
yolov5 的 Backbone 部分的网络结构使用 yaml 文件配置,通过 yolo.py 解析文件加了一个输入构成的网络模块。
Backbone:主干网络,是用来提取特征的网络,其作用就是提取图片中的信息,以供后面的网络使用。
这些网络如 ResNet、VGG,并非是自己设计的,因为这些网络已经证明,在分类等问题上的特征提取能力是很强的。在用这些网络作为 Backbone 的时候,直接加载官方训练好的模型参数,后面接着自己的网络。在训练过程中,对其微调,使得更适合于我们的任务。
Param
nc: 80 # 数据集上的类别个数
depth_multiple: 0.33
width_multiple: 0.5
"""
以下两个参数为缩放因子,通过这两个参数就能够实现不同复杂度的模型设计
depth_multiple: 0.33
用来控制模型的深度(BottleneckCSP数), 在number≠1时启用;
第一个C3层的参数设置为[-1, 3, C3, [128]], number=3表示含有1个C3(3*0.33)
width_multiple: 0.5
用来控制模型的宽度, 作用于args中的ch_out;
第一个Conv层, ch_out=64, 运算中会将卷积核设为64x0.5, 输出32通道的特征图
"""
backbone
backbone:
"""
[from, number, module, args]
from列参数: 当前模块输入来源, -1表示从上一层获得取
number列参数:模块重复的次数, 1表示只有一个, 3表示有三个相同模块
"""
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
"""
[-1, 1, Conv, [64, 6, 2, 2]
input:3x640x640
[ch_out, kernel, stride, padding]=[64, 6, 2, 2]
新通道数为64x0.5=32
特征图计算公式: Feature_new = (Feature_old - kernel + 2 * padding) / stride + 1
新特征图尺寸为: Feature_new = (640 - 6 + 2 * 2) / 2 + 1 = 320
"""
Backbone组成
YOLOv6.0 版本的 Backbone 去除了 Focus 模块(便于模型导出部署),Backbone主要由CBL、BottleneckCSP/C3以及SPP/SPPF等组成,具体如下图所示:
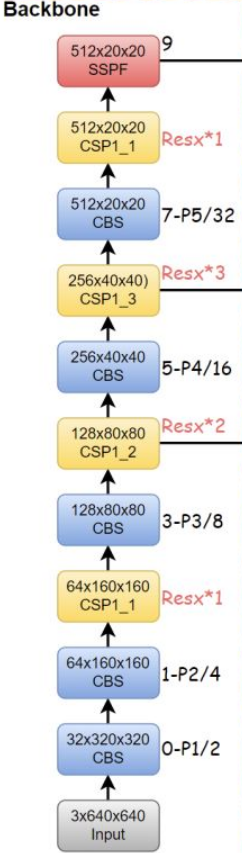
Input(3×640×640) -> CBS(32×320×320) -> CBS(64×160×160) -> CSP1_1(64×160×160) -> CBS(128×80×80) -> CSP1_2(128×80×80) -> CBS(256×40×40) -> CSP1_3(256×40×40) -> CBS(512×20×20) -> CSP1_1(512×20×20) -> SSPF(512×20×20)
CBS模块

class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # 初始化构造函数
"""
Standard convolution: Conv + BN + SiLU
:params c1 : 输入的channel值
:params c2 : 输出的channel值
:params k : 卷积的kernel_size
:params s : 卷积的stride
:params p : 卷积的padding, 一般是None, 可通过autopad自行计算需要的padding数
:params g : 卷积的groups数, =1是普通的卷积, >1是深度可分离卷积
:params act: 激活函数类型, False就是不使用激活函数, 类型是nn.Module, 使用传进的激活函数类型
"""
super().__init__()
# 不使用bias偏置,Conv2d和BatchNorm2d结合使用以后,会进行融合操作,融合时卷积的bias值会被消掉
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
# 激活函数改进,近年较火且效果较好的激活函数
# nn.Identity()是网络中的占位符, 无实际操作, 在增减网络过程中, 可使整个网络层数据不变, 便于迁移权重数据;
# self.act = nn.Tanh() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = nn.Sigmoid() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = nn.ReLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = nn.LeakyReLU(0.1) if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = nn.Hardswish() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = Mish() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = FReLU(c2) if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = AconC(c2) if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = MetaAconC(c2) if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = DyReLUA(c2, conv_type='2d') if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
# self.act = DyReLUB(c2, conv_type='2d') if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x): # 网络的执行顺序根据forward函数来决定的
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""
用于Model类的fuse函数
没有bn,减少推理时间,一般用于测试/验证阶段
"""
return self.act(self.conv(x))
padding
def autopad(k, p=None): # kernel, padding
"""
根据卷积核大小k自动计算卷积核padding数(0填充),让特征图大小不变
v5有两种卷积:
1、下采样卷积: conv3x3 s=2 p=k//2=1
2、feature size不变的卷积: conv1x1 s=1 p=k//2=1
:params k: 卷积核的kernel_size
:return p: 自动计算需要的pad值(0填充)
"""
if p is None:
# 如果k是整数, p为k与2整除后向下取整; 如果k是列表等, p对应的是列表中每个元素整除2
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # 自动计算pad数
return p
groups
分组卷积
当groups = 1时, 所有输入都卷积到所有输出
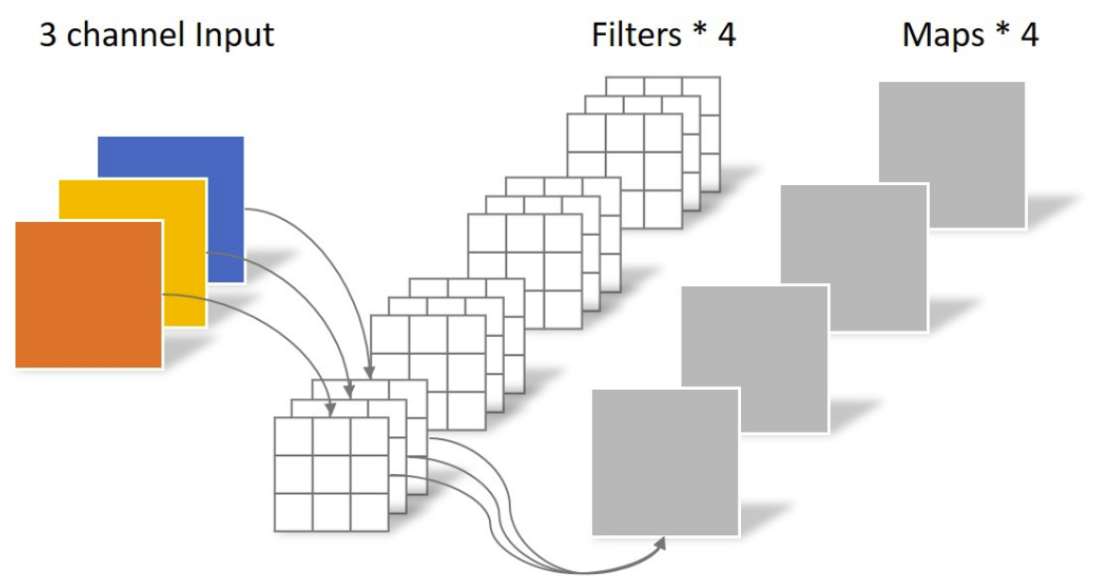
当groups = 2时, 该操作等效于两个并排的卷积层, 每个层看到一半的输入通道, 产生一半的输出通道, 并且两者随后连接在一起。
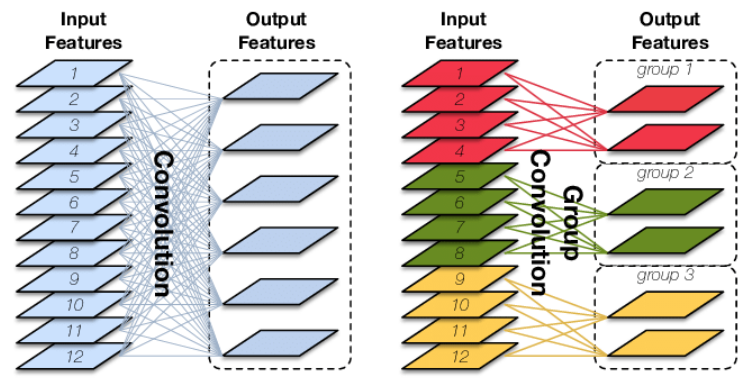
在groups= in_channels时(深度可分离卷积), 每个输入通道都使用自己的滤波器进行卷积, 其大小为: out_channels/in_channels
activate(待补充)
决定是否对特征图进行激活操作, SiLU表示使用Sigmoid进行激活
CSP/C3
CSP 即 Backbone 中的 C3,因为在 Backbone 中 C3 存在 shortcut,而在 Neck 中 C3 不使用 shortcut,所以 backbone 中的 C3 层使用 CSP1_x 表示,Neck 中的 C3 使用 CSP2_x 表示。
CSP结构
class C3(nn.Module):
# 简化版的BottleneckCSP, 除Bottleneck只有3个卷积,所以取名C3, 它更简单、更快、更轻,具有相似的性能
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
"""
在 C3TR 模块和 yolo.py 的 parse_model 模块调用
:params c1: 整个BottleneckCSP的输入channel
:params c2: 整个BottleneckCSP的输出channel
:params n : 有n个Bottleneck
:params shortcut: bool Bottleneck中是否有shortcut,默认True
:params g : Bottleneck中的3x3卷积类型 =1普通卷积 >1深度可分离卷积
:params e : expansion ratio c2*e=中间其他所有层的卷积核个数/中间所有层的输入输出channel数
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
# 实验性 CrossConv
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
从源码中得:输入特征图一条分支先经过 cv1,再经过 m,得到子特征图1;另一分支经过 cv2 后得到子特征图2。最后将子特征图1和子特征图2拼接后输入 cv3 得到C3层的输出。CV操作即前面的 Conv2d + BN + SiLU,关键是 m 操作。
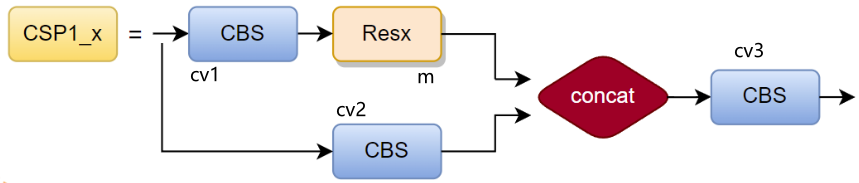
m操作:使用 nn.Sequential 将多个 Bottleneck( Resx )串接到网络中,for 循环中的n 即网络配置文件 args 中的 number,即将 number × depth_multiple 个 Bottleneck 串接到网络中。
Bottleneck
在 Resnet 出现之前,人们认为网络越深获取信息也越多,模型泛化效果越好。
然而网络深度到达一定程度后,模型的准确率反而降低。这并不是过拟合造成的,而是由于反向传播过程中的梯度爆炸和梯度消失。即网络越深,模型越难优化,而不是学习不到更多的特征。
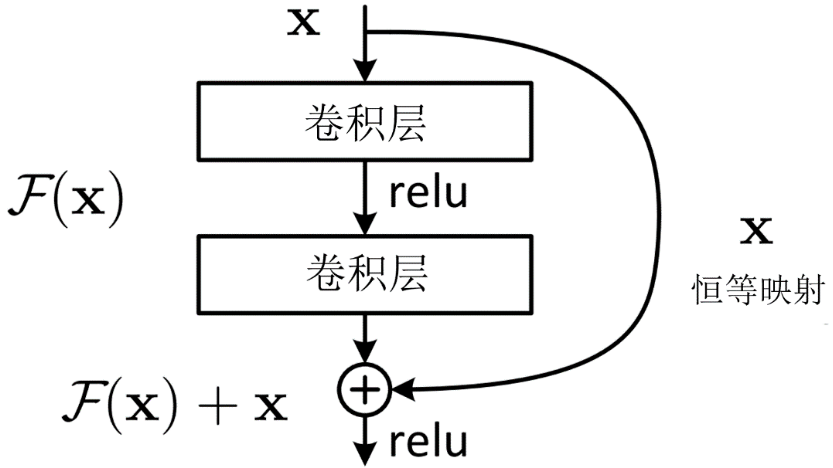
为了让深层次的网络模型达到更好的训练效果,残差网络提出了残差映射替换以往的基础映射。
对于输入 x,期望输出 H(x),网络利用恒等映射将 x 作为初始结果,将原来的映射关系变成 F(x)+x。与其让多层卷积去近似估计 H(x) ,不如近似估计 H(x)-x,即近似估计残差 F(x)。
因此,ResNet 相当于将学习目标改变为目标值 H(x) 和 x 的差值,后面的训练目标就是要将残差结果逼近于 0。
目前要求解的映射为:H(x),将这个问题转换为求解网络的残差映射函数,即F(x),其中F(x) = H(x)-x。残差:观测值与估计值之间的差。H(x)是观测值,x就是估计值(即上一层ResNet输出的特征映射)。
残差模块优点
1、梯度弥散方面。加入ResNet中的shortcut结构在反传时,每两个block之间不仅传递梯度,还加上了求导之前的梯度,相当于把每一个block中向前传递的梯度人为加大,就会减小梯度弥散的可能性。
2、特征冗余方面。正向卷积时,对每一层做卷积其实只提取了图像的一部分信息,越到深层,原始图像信息的丢失越严重,仅仅是对原始图像中的一小部分特征做提取。这会发生类似欠拟合的现象,加入shortcut结构,相当于在每个block中又加入了上一层图像的全部信息,一定程度上保留了更多的原始信息。
在resnet中,人们使用带有shortcut的残差模块搭建几百层甚至上千层的网络,浅层的残差模块被命名为Basicblock(18、34),深层网络使用的的残差模块,被命名为Bottleneck(50+)。
Bottleneck 与 Basicblock 最大的区别是卷积核的组成。
Basicblock由两个3x3的卷积层组成,Bottleneck由两个1x1卷积层夹一个3x3卷积层组成:其中1x1卷积层降维后再恢复维数,让3x3卷积在计算过程中的参数量更少、速度更快。
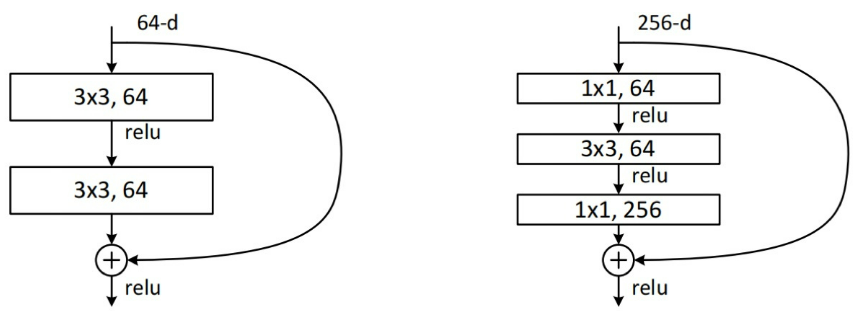
第一个1x1的卷积把256维channel降到64维,然后在最后通过1x1卷积恢复,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,而不使用bottleneck的话就是两个3x3x256的卷积,参数数目: 3x3x256x256x2 = 1179648,差了16.94倍。
Bottleneck减少了参数量,优化了计算,保持了原有的精度。
# Standard bottleneck(True/False) Conv + Conv + shortcut(True/False)
class Bottleneck(nn.Module):
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5):
"""
在BottleneckCSP和yolo.py的parse_model中调用
:params c1: 第一个卷积的输入channel
:params c2: 第二个卷积的输出channel
:params shortcut: bool 是否有shortcut连接 默认是True
:params g : 卷积分组的个数 =1就是普通卷积
:params e : expansion ratio c2*e=第一个卷积的输出channel=第二个卷积的输入channel
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1) # 1x1
self.cv2 = Conv(c_, c2, 3, 1, g=g) # 3x3
self.add = shortcut and c1 == c2 # shortcut=True and c1 == c2 才能做shortcut
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
CSP中的Bottleneck与ResNet类似,先是1x1的卷积层(CBS),然后再是3x3的卷积层,最后通过shortcut与初始输入相加。
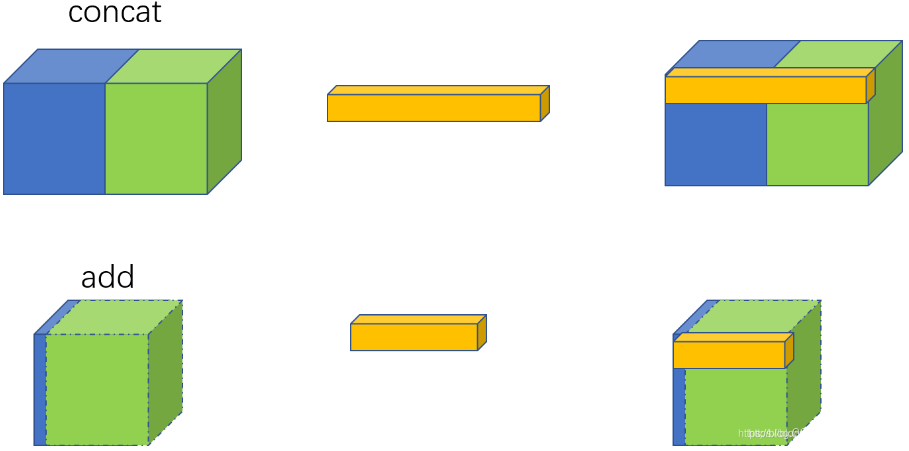
与ResNet的不同在于:CSP将输入维度减半运算后并,未再使用1x1卷积核进行升维,而是将原始输入x也降了维,采取concat的方法进行张量的拼接,得到与原始输入相同维度的输出。
ResNet中的shortcut通过add实现,是特征图对应位置相加而通道数不变;
CSP中的shortcut通过concat实现,是通道数的增加。


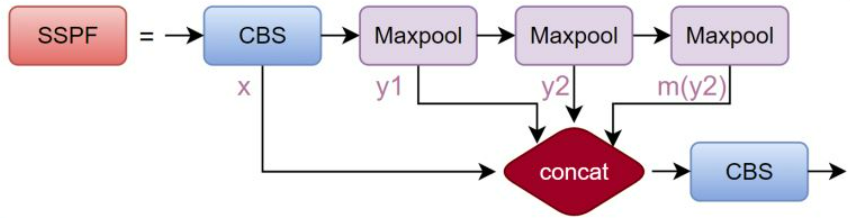
SSPF
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
"""
:params c1: 第一个卷积的输入channel
:params c2: 第二个卷积的输出channel
:params k : 初始化的kernel size
"""
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1) # 对应第一个CBS
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x) # 先通过CBS进行通道数减半
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
# 上述两次最大池化
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))
SSPF模块将经过CBS的x、一次池化后的y1、两次池化后的y2和三次池化后的self.m(y2)先进行拼接,然后再CBS提取特征。
虽然SSPF对特征图进行了多次池化,但特征图尺寸并未变化,通道数更不会变化,所以后续的4个输出能在channel维度进行融合。
这一模块的主要作用是对高层特征进行提取并融合,在融合的过程中作者多次运用最大池化,尽可能多的去提取高层次的语义特征。
YOLOv5s的Backbone总览
参考
YOLOv5 Backbone详解
分组卷积(Group Convolution)与深度可分离卷积(Depthwise Separable Convolution)
YOLOV5-5.x 源码讲解
ResNet详解——通俗易懂版
YOLOv5中的SPP/SPPF结构详解