hw1
任务描述
任务很简单,就是一个回归问题,给你过去四天新冠肺炎感染人数的相关情况,让你预测最后一天的新冠感染人数。

上图展示了特征的解析特征共有117维,首先是37维的关于州的one-hot编码,然后是4维的特征表示是否有新冠相像的疾病,后面8维是行为指标,例如戴口罩,到别的州旅游等等,之后的3维是精神健康指标,例如是否感到焦虑,沮丧等等,最后一维是当天感染的人数。因为一共有五天,所以特征为37+16x5 = 117。最后要预测的就是第五天的Tested Positive Case。
评价指标是mseloss,均方差损失函数,

各个不同的level要求如下:
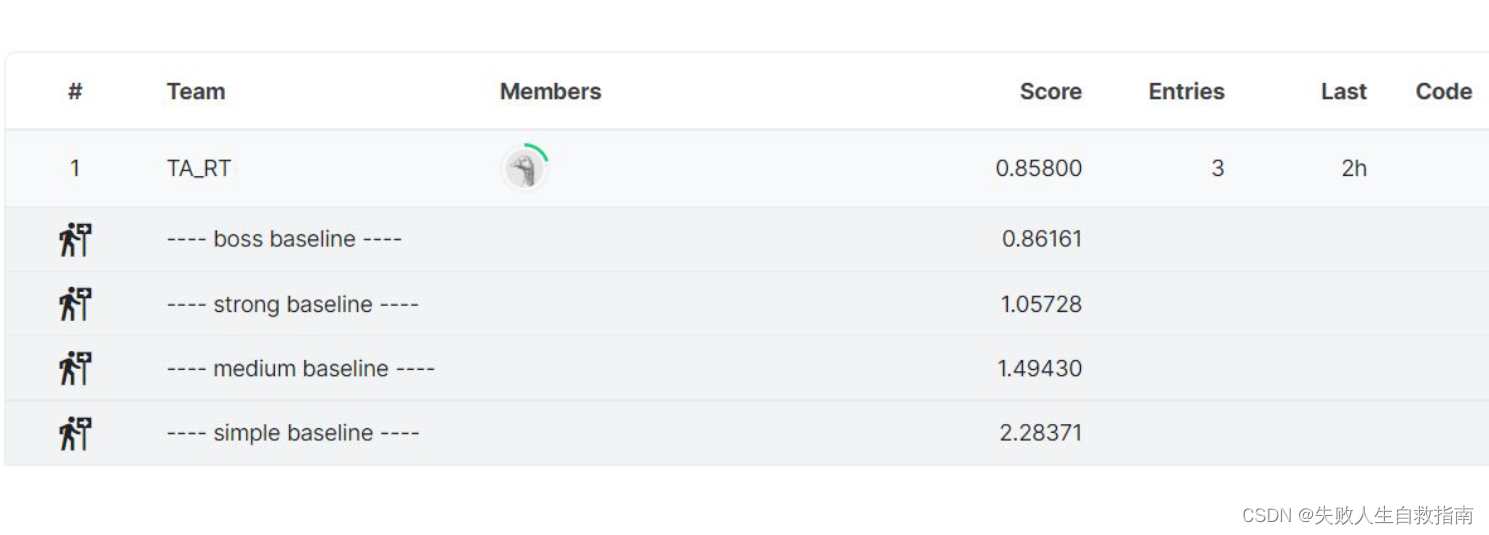
方法分析
这个任务是李宏毅老师的第一个作业,难度不算太大,但想要双榜过boss却很难,模型就是一个简单的线性模型,能改的地方也不太多,加Dropout,BatchNorm,leakyReLU等等。这个题的关键在于数据的处理,要充分利用数据,筛选出关键的特征。
Strong baseline
特征选择:使用skearn的SelectKBest选择出k个最好的特征,代码如下:
train_data, test_data = pd.read_csv('./covid.train.csv').values, pd.read_csv('./covid.test.csv').values
x_data, y_data = train_data[:,1:117], train_data[:,-1]
k=24
selector = SelectKBest(score_func=f_regression, k=k)
result = selector.fit(x_data, y_data)
idx = np.argsort(result.scores_)[::-1]
slected_ids =list(np.sort(idx[:k]))
print(slected_ids)
//输出
[37, 38, 39, 40, 52, 53, 54, 55, 56, 68, 69, 70, 71, 72, 84, 85, 86, 87, 88, 100, 101, 102, 103, 104]
对于数据要进行归一化处理,把它们全归一化到0-1的范围内。
x_train, x_valid, x_test, y_train, y_valid = select_feat(train_data, valid_data, test_data, slected_ids, config['select_all'])
all_data =np.concatenate((x_train, x_valid, x_test), axis=0)
x_min, x_max = all_data.min(axis=0), all_data.max(axis=0)
x_train = (x_train - x_min) / (x_max - x_min)
x_valid = (x_valid - x_min) / (x_max - x_min)
x_test = (x_test - x_min) / (x_max - x_min)
训练细节:
//模型结构
class My_Model(nn.Module):
def __init__(self, input_dim):
super(My_Model, self).__init__()
# TODO: modify model's structure, be aware of dimensions.
#input_dim is the num of features we selected
self.layers = nn.Sequential(
nn.Linear(input_dim, 64),
nn.LeakyReLU(0.2),
nn.BatchNorm1d(64),
nn.Dropout(0.2),
nn.Linear(64, 16),
nn.LeakyReLU(0.2),
nn.BatchNorm1d(16),
nn.Dropout(0.1),
nn.Linear(16, 1)
)
def forward(self, x):
x = self.layers(x)
x = x.squeeze(1) # (B, 1) -> (B)
return x
//只展示关键的设置
config = {
'seed': 520, # Your seed number, you can pick your lucky number. :)
'select_all': False, # Whether to use all features.
'valid_ratio': 0.2, # validation_size = train_size * valid_ratio
'n_epochs': 3000, # Number of epochs.
'batch_size': 128,
'learning_rate': 1e-5,
'weight_decay': 1e-4,
'early_stop': 500, # If model has not improved for this many consecutive epochs, stop training.
'save_path': './models/model.ckpt' # Your model will be saved here.
}
optimizer = torch.optim.Adam(model.parameters(), lr=config['learning_rate']*100,
weight_decay=1e-4)
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer,
T_0=2, T_mult=3, eta_min=0)
提交结果:

虽然过了strong baseline 但和boss baseline还有很大差距。
Boss Baseline
之前说了本题的关键在于数据处理,如果结果不够好,那一定是数据处理得还不够好。
之前使用sklearn 选择出了与结果相关性最大的24个特征,找到这24个特征对应的列,可以发现其实就是每天的COVID-like illness(4)和Tested Positive Cases (1) ,四天20+最后一天4=24。其实也可以想想,得不得新冠最相关的指标其实就是你有没有新冠相关的症状,以及你前几天的感染人数,这才是最关键的,至于是否外出以及沮丧等其实关系并不太大。
ok知道了这个之后,我们还是无法提高,因为我们的Strong baseline已经试过了,数据处理除了进行好的特征选择外,我们还可以选择进行数据扩充,训练数据量对模型的提高起着关键作用。我们不再使用前四天的数据来预测今天的感染人数,而是只用前一天的确诊加上今天的COVID-like illness(4)来预测感染人数,这样训练数据量就可以扩充4倍,还可以加上测试数据中可以利用的部分来进一步扩充数据量。
最终得到的训练数据的shape为:(14030, 9)
而Strong baseline 训练数据的shape为:(2699,24)
数据量扩充了近五倍!
实验细节代码如下:
class My_Model(nn.Module):
def __init__(self, input_dim):
super(My_Model, self).__init__()
# TODO: modify model's structure, be aware of dimensions.
self.layers = nn.Sequential(
nn.Linear(input_dim, 256),
# nn.LeakyReLU(),
# nn.BatchNorm1d(256),
nn.Dropout(0.4),
nn.Linear(256, 1),
)
def forward(self, x):
x = self.layers(x)
x = x.squeeze(1) # (B, 1) -> (B)
return x
optimizer = torch.optim.AdamW(model.parameters(), weight_decay=5e-5) # 5e-5
具体的完整代码等我整理好之后会上传到github,这里只讲明实验过程及展示核心部分。
实验结果
