需求:
从http://www.kanunu8.com/book3/6879爬取《动物农场》所有章节的网址,再通过一个多线程爬虫将每一章的内容爬取下来。在本地创建一个“动物农场”文件夹,并将小说中的每一章分别保存到这个文件夹中。每一章保存为一个文件。
涉及到的知识点
1、requests爬虫网站内容
2、正则表达式提取内容
3、文件写入
4、多线程
插话:做这类需求,最好还是先自己想,自己实现,实现后再去看自己跟书上的有什么不一样。
单线程实现
#使用requests获取网页源代码
import requests
import re
import time
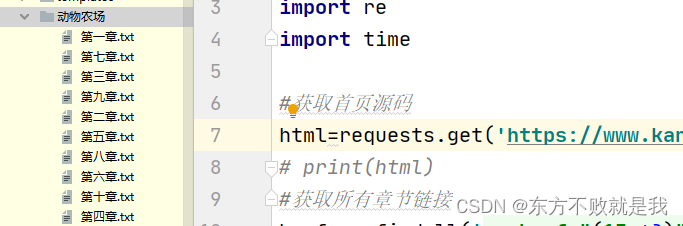
#获取首页源码
html=requests.get('https://www.kanunu8.com/book3/6879/').content.decode(encoding='gbk')
# print(html)
#获取所有章节链接
herf=re.findall('<a href="(13.*?)">',html,re.S)
print(herf)
start=time.time()
for i in herf:
#通过链接获取每一章的源码
chapter_html=requests.get('https://www.kanunu8.com/book3/6879/'+i).content.decode(encoding='gbk')
# print(chapter_html)
title=re.search('size="4">(.*?)<',chapter_html,re.S).group(1)#获取章节名称
content=re.findall('<p>(.*?)</p>',chapter_html,re.S)#获取每一张p标签内的内容,结果返回为列表
content_str="\n".join(content).replace("<br />","")#列表转为字符串并替换多余符号
with open('动物农场/'+title+'.txt','w',encoding='utf-8') as f:
f.write(title)
f.write(content_str)
end=time.time()
print(f'单线程耗时{end-start}')
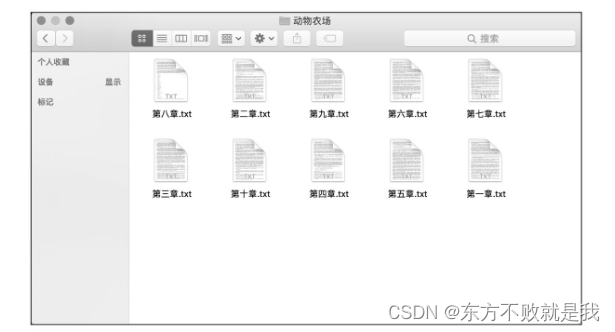
结果,文件夹是自己手动创建的,生成如下十个章节txt文件。
文件为每个章节的内容。
如果看不到,在文件夹右键,reload from disk
这个记录了下耗时,可以看到是13秒多。
单线程耗时13.868733167648315
多线程
#使用requests获取网页源代码
import requests
import re
import time
from multiprocessing.dummy import Pool
def get_html():
#获取首页源码
html=requests.get('https://www.kanunu8.com/book3/6879/').content.decode(encoding='gbk')
# print(html)
#获取所有章节链接
herf=re.findall('<a href="(13.*?)">',html,re.S)
return herf
def get_every_chapter(i):
#通过链接获取每一章的源码
chapter_html=requests.get('https://www.kanunu8.com/book3/6879/'+i).content.decode(encoding='gbk')
# print(chapter_html)
title=re.search('size="4">(.*?)<',chapter_html,re.S).group(1)#获取章节名称
content=re.findall('<p>(.*?)</p>',chapter_html,re.S)#获取每一张p标签内的内容,结果返回为列表
content_str="\n".join(content).replace("<br />","")#列表转为字符串并替换多余符号
with open('动物农场/'+title+'.txt','w',encoding='utf-8') as f:
f.write(title)
f.write(content_str)
if __name__ == '__main__':
start = time.time()
herf=get_html()#html内容
print(herf)
pool = Pool(3)#创建三个线程
pool.map(get_every_chapter,herf) #章节链接列表传给函数入参
end=time.time()
print(f'多线程耗时{end-start}')
这里使用了3个线程,耗时5.348664283752441
需要注意的一个点,map的第一个参数只写函数名,不用写()
4个线程,耗时4.111229181289673
另外试了5个线程,耗时耗时5.717579126358032
可见,3,4,5中,4个线程耗时最少,线程数不是越多越好。
书上实现

文件路径

且实现了一个保存文件的函数
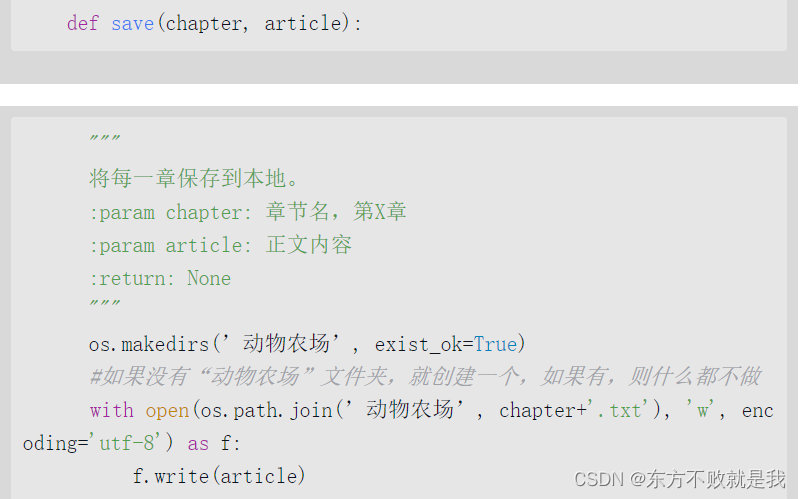
爬虫部分差不多,需要注意的是findall输出为列表,和search结果为字符串。

总结:先自己写,再看书上实现,才能锻炼能力。
内容参考: