文章目录
- 零、写在前面
- 一、窗口排序函数
- 1、基础
- 2、rank() over()——跳跃式排序
- 3、dense_rank() over()
- 4、raw_number() over()
- 5、注意
- 二、窗口偏移函数
-
注意:这些函数是必须在MySQL3.8版本以上才能使用,否则都是会出错的。
零、写在前面
本文所有代码均是在SQL ZOO平台进行,数据也该平台下的world表和一些其他平台提供的数据表,所有代码均已通过测试。

一、窗口排序函数
1、基础
- 标准语法:over (partition by 字段名 order by 字段名 asc/desc)
- over()两个子句为可选项,partition by指定分区依据,order by指定排序依据
- 比较:
rank函数:对于4,4,4,8,也就是如果有并列名次的行,排序结果是:1,1,1,4
dense_rank函数:对于4,4,4,8,也就是如果有并列名次的行,排序结果是:1,1,1,2
row_number函数:对于4,4,4,8,也就是如果有并列名次的行,排序结果是:1,2,3,4
2、rank() over()——跳跃式排序
(1)说明
比如数值为99, 99, 90, 89, 那么通过这个
函数得到的排名为1, 1, 3, 4
因为前面2个同为第一位,且都占了一个位置。
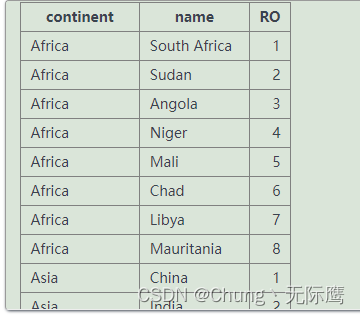
(2)练习:查询每个大洲里面国土面积大于100万、首都城市的名字不是以A,M,C开头的分别在每个大洲人口数量降序的大洲和国家名。(相等人口的国家排名相同,但各占一个位置)
select continent,name,
rank() over(PARTITION BY continent ORDER BY population desc) RO
from world
where area>=1000000 and left(capital,1) not in ('A','M','C')
(3)其他条件不变,若我们只想要看每个大洲人口排名前二的国家,这时候RO这个命名就起作用了(需要用到子查询):
select RF.continent,RF.name
from (select continent,name,
rank() over(PARTITION BY continent ORDER BY population desc) as RO
from world
where area>=1000000 and left(capital,1) not in ('A','M','C')) as RF
where RF.RO=2
3、dense_rank() over()
(1)说明:dense. _rank();并列连续型排序–比如数值为99, 99,90, 89,
那么通过这个函数得到的排名为1, 1, 2, 3
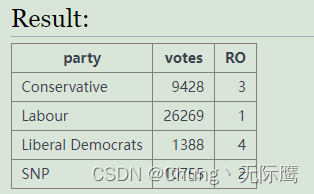
(2)练习:查询选号为’S14000024’且选举年份为2017年的按照选举票数排序的党派和票数。
select party,votes,
dense_rank() over(ORDER BY votes desc) as RO
from ge
where constituency='S14000024' and yr=2017
group by party,votes
order by party
4、raw_number() over()
(1)说明:row _number():连续型排序–比如数值为99, 99, 90, 89, 那么通
过这个函数得到的排名为1, 2, 3, 4
根据对排序值的需求选择相应排序窗口函数,由于值的不同特性(比如数值不重复) , 这三个函数可以通用
(2)练习:查询日期为’2020-4-25’的所有姓名和确诊日期,并列出它们的确诊日期和死亡日期的降序排名
select name,confirmed,
row_number() over(ORDER BY confirmed desc) RC
,deaths
,row_number() over(ORDER BY deaths desc) RD
from covid
where whn='2020-4-25'
order by confirmed desc;
5、注意
1、窗口函数只能在select子句中使用
2、窗口函数中的partition by子句可以指定数据的分区,和group by要去重分组不同的是,partition by只分区不去重
3、窗口函数中没有partition by子句时,即不对数据分区,直接整个表为一个区
4、排序窗口函数中order by子句是必选项,窗口函数中order by子句在分区内,依据指定字段和排序方法对数据行排序
5、窗口函数必须有个名字,比如常用的RO,RI等
二、窗口偏移函数
1、lag()
lag(字段名,偏移量,默认值) over()
select
name,
date_format(whn,'%Y-%m-%d') date,
confirmed 当天截至时间累计确诊人数,
lag(confirmed,1) over(partition by name order by whn) 昨天截至时间累计确诊人数,
(confirmed-lag(confirmed,1) over(partition by name order by whn)) 每天新增确诊人数
from covid
where name in ('France','Germany') and month(whn)=1
group by name,whn,confirmed
order by whn;
2、lead()
lead(字段名,偏移量,默认值) over()
允许我们从窗口分区中,根据给定的相对于当前行的前偏移量(LAG)或后偏移量(LEAD),并返回对应行的值,默认的偏移量为1。当指定的偏移量没有对用的行是,LAG 和LEAD 默认返回 NULL,当然可用其他值替换 LAG(val,1,0.00) 第3个参数就是替换值。
3、综合练习
select name,date_format(whn,'%Y-%m-%d') date,
confirmed - lag(confirmed,1) over(PARTITION BY name ORDER BY whn) Week_New
from covid
where name='Italy' and weekday(whn)=0
group by name,whn,confirmed
order by whn
confirmed 本周一的确诊人数,weekday(whn)=0筛选出周一(把计算范围都控制在周一,每个周一相减就是一周的新增)
文章总结归纳于自戴师兄的课程:https://www.bilibili.com/video/BV1ZM4y1u7uF?p=4,在此课程学习的基础上进行了一些修改和验证。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)