基于requests和threading模块实现多线程爬虫
前言
此篇文章中介绍基于 requests 和 threading 模块实现多线程爬虫,并以 抓取Cocos中文社区中:热门主题下的帖子名称及id数据 为例进行讲解;因主要介绍如何使用多线程,所以爬取网页数据的方法可以参考:【Python_requests学习笔记(七)】基于requests模块 实现动态加载数据的爬取,下面直接进入正文。
正文
直接以代码为例进行讲解
1、程序实现
- 初始化函数
def __init__(self):
self.url = "https://forum.cocos.org/top.json?page={}&per_page=50" # url地址
self.q = Queue() # 创建队列
self.lock = Lock() # 创建线程锁
a、创建队列,是为了存放需要爬取网页的 url 地址;
b、创建线程锁,是为了防止多个线程在同时操作队列时,即 self.q 出现异常。
- 队列函数
def url_in(self):
"""
function: url地址入队列函数
in: None
out: None
return: int >0 ok, <0 some wrong
others: url Queue Func
"""
for page in range(10): # 爬取10页
url = self.url.format(page) # 创建所有需要抓取的url地址
self.q.put(url) # 入队列
- 多线程事件函数
def pares_html(self):
"""
function: 线程的事件函数:获取url,请求,解析,处理数据
in: None
out: None
return: int >0 ok, <0 some wrong
others: The Event Function Of The Thread
"""
while True:
self.lock.acquire() # 上锁
if not self.q.empty(): # 判断队列是否为空
url = self.q.get() # 出队列
self.lock.release() # 释放锁
headers = {"User-Agent": UserAgent().random} # 构造随机请求头
html = requests.get(url=url, headers=headers).json() # 获取响应内容
item = {} # 定义一个空字典
for dic in html["topic_list"]["topics"]:
item["id"] = dic["id"]
item["名称"] = dic["title"]
print(item)
print("**********")
else: # 当队列为空时,已经上锁未释放,所以需要释放锁
self.lock.release() # 释放锁
break
a、while循环是为了元素出队列的操作,当队列为空时,说明需要爬取的网页已经爬取完成,即可终止循环;
b、上锁和释放锁在元素出队列前后,每进行一次循环前要上锁,防止两个线程同时操作队列,当元素出队列后立即释放锁,让其他线程从队列中取 ur l地址;
c、注意:当队列为空时也需要释放锁,不然会造成堵塞。
- 程序入口函数
def run(self):
"""
function: 程序入口函数
in: None
out: None
return: None
others: Program Entry Func
"""
self.url_in() # 先让url地址入队列
t_list = [] # 创建多线程
for i in range(1): # 创建3个线程
t = Thread(target=self.pares_html) # 线程实例化
t_list.append(t)
t.start() # 线程开启
for t in t_list:
t.join() # 线程同步
创建线程实例后,要开启线程。
2、完整代码
import time
import requests
from queue import Queue
from threading import Thread, Lock
from fake_useragent import UserAgent
class CocosSpiderThread:
"""
基于requests和threading实现多线程爬虫:
多线程爬取Cocos中文社区中:热门主题下的帖子名称及id数据
"""
def __init__(self):
self.url = "https://forum.cocos.org/top.json?page={}&per_page=50" # url地址
self.q = Queue() # 创建队列
self.lock = Lock() # 创建线程锁
def url_in(self):
"""
function: url地址入队列函数
in: None
out: None
return: int >0 ok, <0 some wrong
others: url Queue Func
"""
for page in range(10): # 爬取10页
url = self.url.format(page) # 创建所有需要抓取的url地址
self.q.put(url) # 入队列
def pares_html(self):
"""
function: 线程的事件函数:获取url,请求,解析,处理数据
in: None
out: None
return: int >0 ok, <0 some wrong
others: The Event Function Of The Thread
"""
while True:
self.lock.acquire() # 上锁
if not self.q.empty(): # 判断队列是否为空
url = self.q.get() # 出队列
self.lock.release() # 释放锁
headers = {"User-Agent": UserAgent().random} # 构造随机请求头
html = requests.get(url=url, headers=headers).json() # 获取响应内容
item = {} # 定义一个空字典
for dic in html["topic_list"]["topics"]:
item["id"] = dic["id"]
item["名称"] = dic["title"]
print(item)
print("**********")
else: # 当队列为空时,已经上锁未释放,所以需要释放锁
self.lock.release() # 释放锁
break
def run(self):
"""
function: 程序入口函数
in: None
out: None
return: None
others: Program Entry Func
"""
self.url_in() # 先让url地址入队列
t_list = [] # 创建多线程
for i in range(3): # 创建3个线程
t = Thread(target=self.pares_html) # 线程实例化
t_list.append(t)
t.start() # 线程开启
for t in t_list:
t.join() # 线程同步
if __name__ == '__main__':
start_time = time.time() # 记录开始时间
spider = CocosSpiderThread()
spider.run()
end_time = time.time() # 记录结束时间
print("time:%.2fs" % (end_time - start_time)) # 打印总用时
3、实现效果
3个线程爬取:用时1.60s
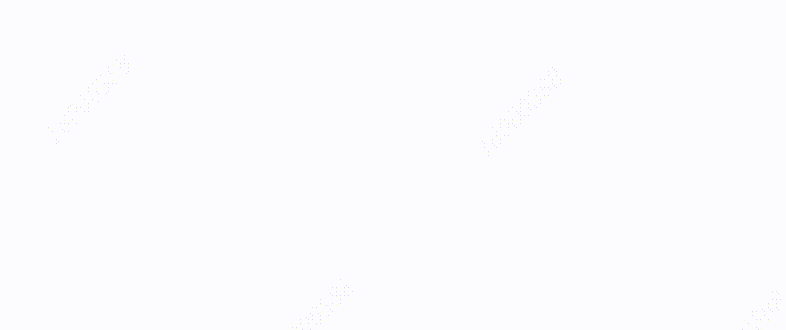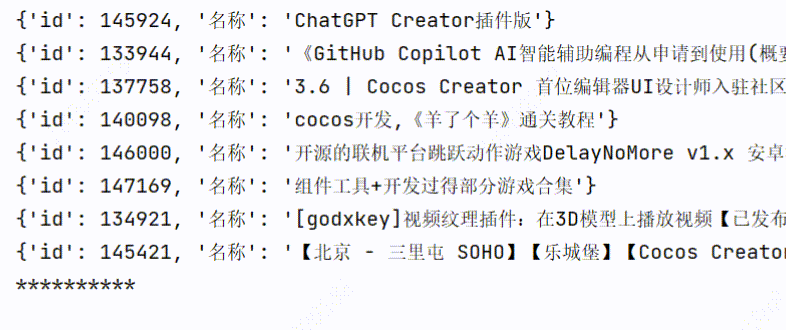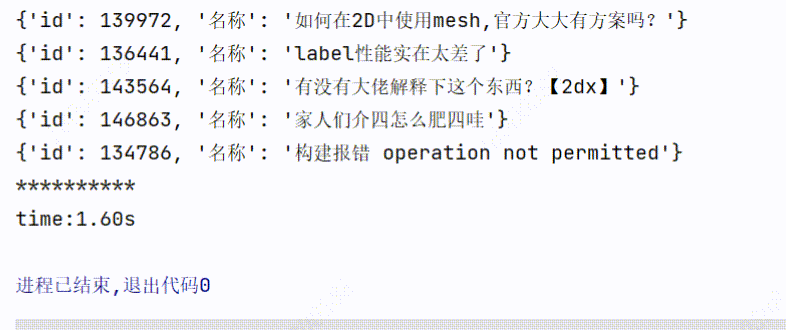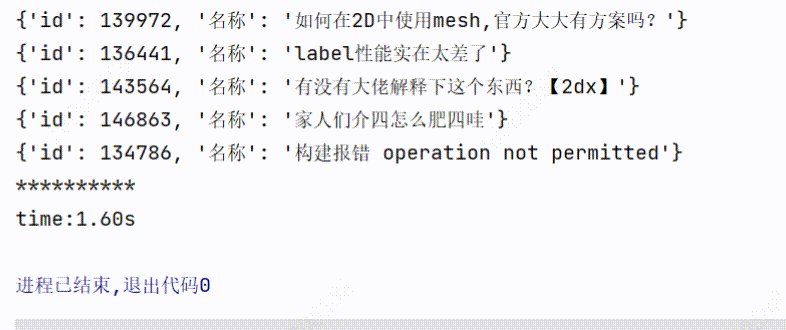
1个线程爬取:用时3.98s
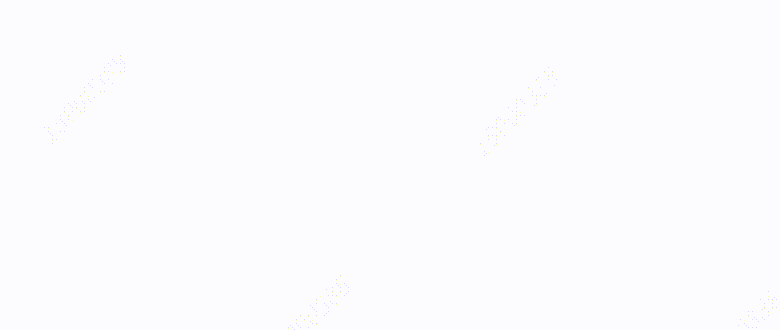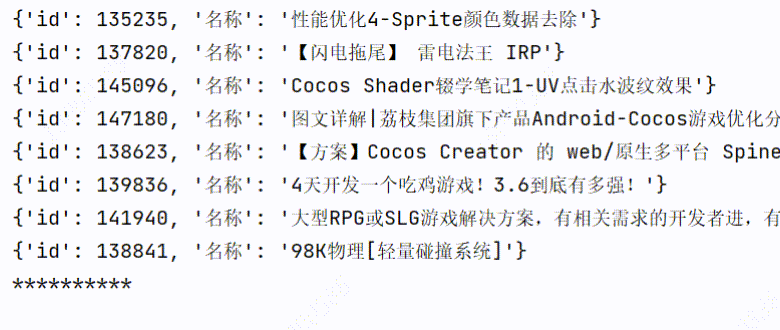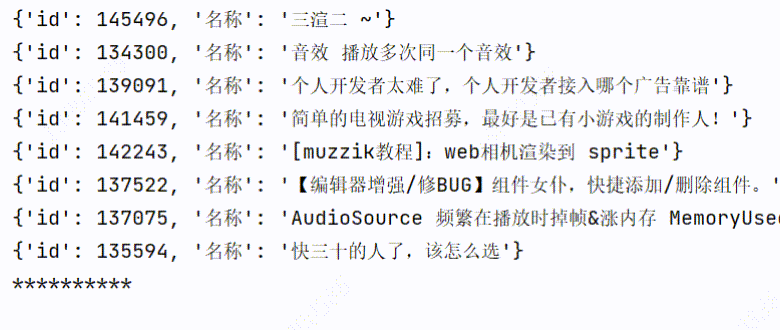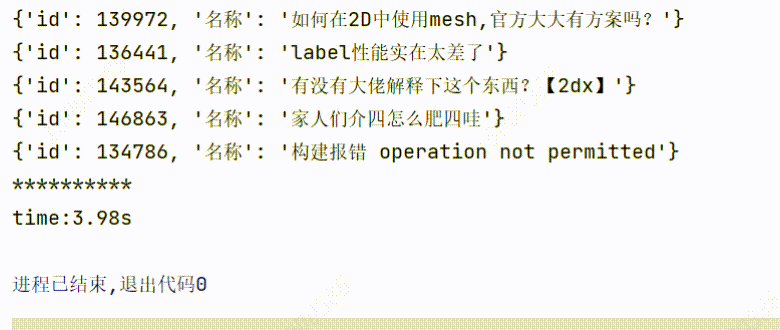
可以看到爬取的时间是有所缩短的。