符号表
1、用来存储程序中的变量相关信息
2、必须非常高效
符号表的接口
#ifndef TABLE_H
#define TABLE_H
typedef ... Table_t; // 数据结构
// 新建一个符号表
Table_t Table_new();
// 符号表的插入
void Table_enter (Table_t, Key_t, value_t);
// 符号表的查找
Value_t Table_lookup (Table_t, Key_t);
#endif
注:符号表的具体数据结构我们下面给出。
符号表的典型数据结构
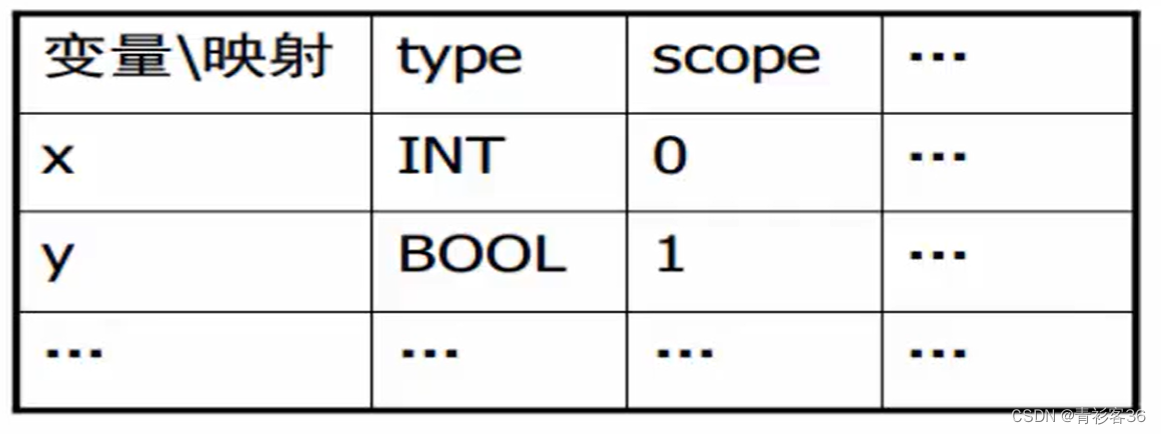
符号表是典型的字典结构:symbolTable:key-> value
一种简单的数据结构定义(概念上的):
typedef char *key ; // 关键字
// key映射到值可能不止一种,比如类型、作用域等
// 所以一般将Value组织成结构体
typedef struct value{ // value中的字段为要维护的变量上的各种信息
Type_t type ;
scope_t scope ;
//必要的其他字段
}value;
符号表的高效实现
- 为了高效,可以使用哈希表等数据结构来实现符号表,查找是O(1)时间
- 为了节约空间,也可以使用红黑树等平衡树,查找是O(lg N)时间
符号表实现时需关注的点
作用域
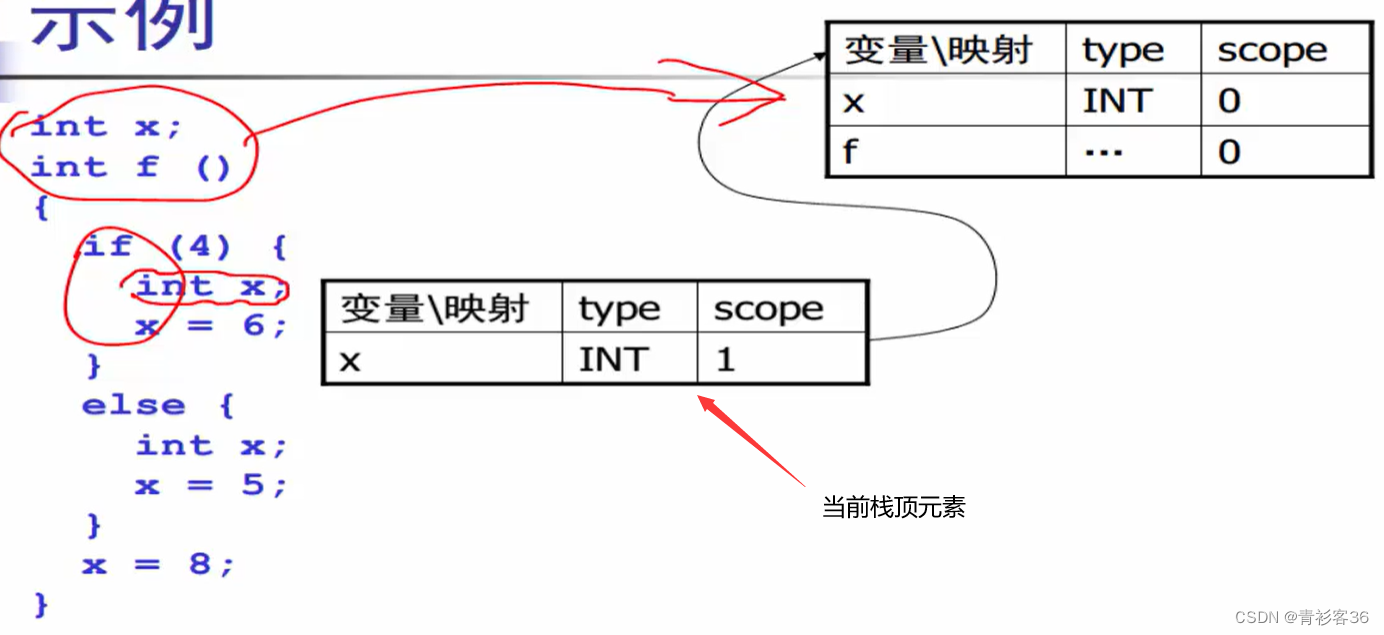
我们来看下面这段程序
int x;
int f()
{
if (4) {
int x;
x = 6;
}
else {
int x;
x = 5;
}
x = 8;
}
符号表处理作用域的方法
方法一:一张表的方法(hash表)
进入作用域时,插入元素。
退出作用域时,删除元素。

实现正确的变量屏蔽,需要对hash表做仔细的处理。比如,hash表是一个数组,当在某一个位置发生冲突时,若采用拉链法解决冲突的话,需要保证后面插入的x要插入在表头上面,想一下为什么在这儿用头插法,而不是尾插法?因为要访问最近作用域的变量呀hh~。
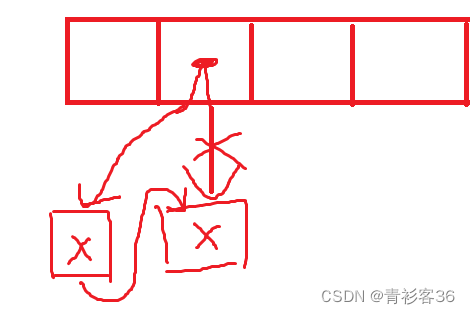
方法二:采用符号表构成的栈
进入作用域时,插入新的符号表。
退出作用域时,删除栈顶符号表。
名字空间
在一个程序中,有可能许多地方用到同一个变量名,但是这些变量名的作用是不一样的,他们可以同时存在。如下面这段程序:
struct list
{
int x;
struct list *list;
} *list;
void walk(struct list *list)
{
list:
printf("%d\n", list->x);
if (list == list->list)
goto list;
}
该程序中虽然有多个list,但每个list属于不同的分类。
① 结构体的名字 ② 变量名 ③ 结构体的域(结构体中的*list域)④ 标号(label)
那么做语义分析时如何处理这种情况呢?
用符号表处理名字空间
每个名字空间用一个表来处理,以C语言为例,有不同的名字空间:变量、标签、标号......
可以每一类定义一张符号表。当变量使用时,需要根据变量类别的不同,到不同的符号表中去查找这个变量。
上面说的,用hash表或栈的方式来组织符号表,是指具体的每一种符号表该怎么来做。