umi-request 网络请求之路
背景
在做中台业务应用开发的过程中,我们发现在请求链路上存在以下问题:
-
请求库各式各样,没有统一。 每次新起应用都需要重复实现一套请求层逻辑,切换应用时需要重新学习请求库 API。
-
各应用接口设计不一致、混乱。 前后端同学每次需重新设计接口格式,前端同学在切换应用时需重新了解接口格式才能做业务开发。
-
接口文档维护各式各样。 有的在语雀(云端知识库)上,有的在 RAP (开源接口管理工具)上,有的靠阅读源码才能知道,无论是维护、mock 数据还是沟通都很浪费人力。
针对以上问题,我们提出了请求层治理,希望能通过统一请求库、规范请求接口设计规范、统一接口文档这三步,对请求链路的前中后三个阶段进行提效和规范, 从而减少开发者在接口设计、文档维护、请求层逻辑开发上花费的沟通和人力成本。其中,统一请求库作为底层技术支持,需要提前打好基地,为上层提供稳定、完善的功能支持,基于此,umi-request 应运而生。
umi-request
umi-request 是基于 fetch 封装的开源 http 请求库,旨在为开发者提供一个统一的 API 调用方式,同时简化使用方式,提供了请求层常用的功能:
- URL 参数自动序列化
- POST 数据提交方式简化
- Response 返回处理简化
- 请求超时处理
- 请求缓存支持
- GBK 编码处理
- 统一的错误处理方式
- 请求取消支持
- Node 环境 http 请求
- 拦截器机制
- 洋葱中间件机制
与 fetch、axios 的异同?

umi-request 底层抛弃了设计粗糙、不符合关注分离的 XMLHttpRequest,选择了更加语义化、基于标准 Promise 实现的 fetch(更多细节详见);同时同构更方便,使用 isomorphic-fetch(目前已内置);而基于各业务应用场景提取常见的请求能力并支持快速配置如 post 简化、前后缀、错误检查等。
上手便捷
安装
npm install --save umi-request
执行 GET 请求
import request from "umi-request";
request
.get("/api/v1/xxx?id=1")
.then(function(response) {
console.log(response);
})
.catch(function(error) {
console.log(error);
});
// 也可将 URL 的参数放到 options.params 里
request
.get("/api/v1/xxx", {
params: {
id: 1
}
})
.then(function(response) {
console.log(response);
})
.catch(function(error) {
console.log(error);
});
执行 POST 请求
import request from "umi-request";
request
.post("/api/v1/user", {
data: {
name: "Mike"
}
})
.then(function(response) {
console.log(response);
})
.catch(function(error) {
console.log(error);
});
实例化通用配置
请求一般都有一些通用的配置,我们不想在每个请求里去逐个添加,例如通用的前缀、后缀、头部信息、异常处理等等,那么可以通过 extend 来新建一个 umi-request 实例,从而减少重复的代码量:
import { extend } from "umi-request";
const request = extend({
prefix: "/api/v1",
suffix: ".json",
timeout: 1000,
headers: {
"Content-Type": "multipart/form-data"
},
params: {
token: "xxx" // 所有请求默认带上 token 参数
},
errorHandler: function(error) {
/* 异常处理 */
}
});
request
.get("/user")
.then(function(response) {
console.log(response);
})
.catch(function(error) {
console.log(error);
});
内置常见请求能力
fetch 本身并不提供请求超时、缓存、取消等能力,而在业务开发中却常常需要,因此 umi-request 对常见的请求能力进行封装内置,减少重复开发:
{
// 'params' 是即将于请求一起发送的 URL 参数,参数会自动 encode 后添加到 URL 中
// 类型需为 Object 对象或者 URLSearchParams 对象
params: { id: 1 },
// 'paramsSerializer' 开发者可通过该函数对 params 做序列化(注意:此时传入的 params 为合并了 extends 中 params 参数的对象,如果传入的是 URLSearchParams 对象会转化为 Object 对象
paramsSerializer: function (params) {
return Qs.stringify(params, { arrayFormat: 'brackets' })
},
// 'data' 作为请求主体被发送的数据
// 适用于这些请求方法 'PUT', 'POST', 和 'PATCH'
// 必须是以下类型之一:
// - string, plain object, ArrayBuffer, ArrayBufferView, URLSearchParams
// - 浏览器专属:FormData, File, Blob
// - Node 专属: Stream
data: { name: 'Mike' },
// 'headers' 请求头
headers: { 'Content-Type': 'multipart/form-data' },
// 'timeout' 指定请求超时的毫秒数(0 表示无超时时间)
// 如果请求超过了 'timeout' 时间,请求将被中断并抛出请求异常
timeout: 1000,
// 'prefix' 前缀,统一设置 url 前缀
// ( e.g. request('/user/save', { prefix: '/api/v1' }) => request('/api/v1/user/save') )
prefix: '',
// 'suffix' 后缀,统一设置 url 后缀
// ( e.g. request('/api/v1/user/save', { suffix: '.json'}) => request('/api/v1/user/save.json') )
suffix: '',
// 'credentials' 发送带凭据的请求
// 为了让浏览器发送包含凭据的请求(即使是跨域源),需要设置 credentials: 'include'
// 如果只想在请求URL与调用脚本位于同一起源处时发送凭据,请添加credentials: 'same-origin'
// 要改为确保浏览器不在请求中包含凭据,请使用credentials: 'omit'
credentials: 'same-origin', // default
// 'useCache' 是否使用缓存,当值为 true 时,GET 请求在 ttl 毫秒内将被缓存,缓存策略唯一 key 为 url + params 组合
useCache: false, // default
// 'ttl' 缓存时长(毫秒), 0 为不过期
ttl: 60000,
// 'maxCache' 最大缓存数, 0 为无限制
maxCache: 0,
// 'charset' 当服务端返回的数据编码类型为 gbk 时可使用该参数,umi-request 会按 gbk 编码做解析,避免得到乱码, 默认为 utf8
// 当 parseResponse 值为 false 时该参数无效
charset: 'gbk',
// 'responseType': 如何解析返回的数据,当 parseResponse 值为 false 时该参数无效
// 默认为 'json', 对返回结果进行 Response.text().then( d => JSON.parse(d) ) 解析
// 其他(text, blob, arrayBuffer, formData), 做 Response[responseType]() 解析
responseType: 'json', // default
// 'errorHandler' 统一的异常处理,供开发者对请求发生的异常做统一处理,详细使用请参考下方的错误处理文档
errorHandler: function(error) { /* 异常处理 */ },
}
中间件机制方便拓展
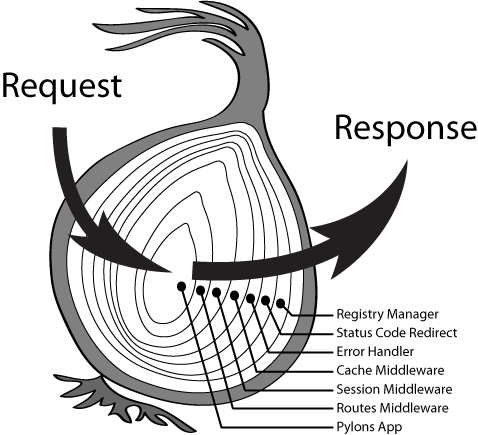
复杂场景应用对请求前后有定制化的处理需求,请求库除了提供基础的内置能力外,也需要提升自身拓展性,基于此 umi-request 引入中间件机制,选择了类 KOA 的洋葱圈模型:

(中间件洋葱图)
由上图可看出,每一层洋葱圈为一个中间件,请求经过一个中间件都会执行两次,开发者可以根据业务需求很方便地实现请求前后增强处理:
import request from "umi-request";
request.use(function(ctx, next) {
console.log("a1");
return next().then(function() {
console.log("a2");
});
});
request.use(function(ctx, next) {
console.log("b1");
return next().then(function() {
console.log("b2");
});
});
// 执行顺序如下:
// a1 -> b1 -> b2 -> a2
// 使用 async/await 能让结构、顺序更清晰明了:
request.use(async (ctx, next) => {
console.log("a1");
await next();
console.log("a2");
});
request.use(async (ctx, next) => {
console.log("b1");
await next();
console.log("b2");
});
const data = await request("/api/v1/a");
// 执行顺序如下:
// a1 -> b1 -> b2 -> a2
实现原理
那么洋葱圈的中间件机制是如何实现的呢?它主要由中间件数组和中间件组合两部分组成,前者负责存储挂载的中间件,后者负责将中间件按照洋葱的结构进行组合并返回真实可执行函数:
存储中间件
class Onion {
constructor() {
this.middlewares = [];
}
// 存储中间件
use(newMiddleware) {
this.middlewares.push(newMiddleware);
}
// 执行中间件
execute(params = null) {
const fn = compose(this.middlewares);
return fn(params);
}
}
组合中间件
上述代码中的 compose 即为组合中间件的函数实现,精简后逻辑如下(详见):
export default function compose(middlewares) {
return function wrapMiddlewares(params) {
let index = -1;
function dispatch(i) {
index = i;
const fn = middlewares[i];
if (!fn) return Promise.resolve();
return Promise.resolve(fn(params, () => dispatch(i + 1)));
}
return dispatch(0);
};
}
compose 函数通过 dispatch(0) 先执行了第一个中间件 fn(params, () => dispatch(i +1)) ,并提供 () => dispatch(i +1) 作为入参供每个中间件能在下一个中间件执行完毕后回来继续处理自己的事务,直到所有中间件完成后执行 Promise.resolve() ,形成洋葱圈中间件机制。
丰富请求能力
面对多端、多设备应用,umi-request 不仅支持 browser http 请求,也同时满足 node 环境、自定义内核请求等能力。
支持 node 环境发送 http 请求
基于 isomorphic-fetch 实现对 node 环境的请求支持:
const umi = require("umi-request");
const extendRequest = umi.extend({ timeout: 10000 });
extendRequest("/api/user")
.then(res => {
console.log(res);
})
.catch(err => {
console.log(err);
});
支持自定义内核请求能力
移动端应用一般都会有自己的请求协议如 RPC 请求,前端会通过 SDK 去调用客户端请求 API,umi-request 支持开发者自己封装请求能力,例子:
// service/some.js
import request from "umi-request";
// 自定义请求内核中间件
function SDKRequest(ctx, next) {
const { req } = ctx;
const { url, options } = req;
const { __umiRequestCoreType__ = "normal" } = options;
if (__umiRequestCoreType__.toLowerCase() !== "SDKRequest") {
return next();
}
return Promise.resolve()
.then(() => {
return SDK.request(url, options); // 假设已经引入了 SDK 并且能通过 SDK 发起对应请求
})
.then(result => {
ctx.res = result; // 将结果注入到 ctx 的 res 里
return next();
});
}
request.use(SDKRequest, { core: true }); // 引入内核中间件
export async function queryUser() {
return request("/api/sdk/request", {
__umiRequestCoreType__: "SDKRequest", // 声明使用 SDKRequest 来发起请求
data: []
});
}
六、uniapp教程(需求分析、各模块及其节点文档、各模块案例)
另外一个项目基于Java+SpringBoot+Vue+Uniapp(有教程)前后端分离健身预约系统设计与实现

总结
随着 umi-request 能力的完善,已经能够支持各个场景、端应用的请求,前端开发只需要掌握一套 API 调用就能实现多端开发,再也不用关注底层协议实现,把更多的精力放在前端开发上。而基于此,umi-request 能在底层做更多的事情,如 mock 数据、自动识别请求类型、接口异常监控上报、接口规范校验等等,最终实现请求治理的目标。umi-request 还有很多能力没有在文中提及,如有兴趣欢迎查看详细文档。