Scikit-learn是一个免费的Python机器学习库。它具有多种算法,例如支持向量机,随机森林和k邻域,并且还支持Python数值和科学库,例如NumPy和SciPy。
在大数据分析Python中Scikit-learn机器学习库中,我们将学习scikit-learn库的帮助,学习如何对python进行编码和应用机器学习,该库的创建是为了使使用Python进行机器学习更轻松,更强大。
为此,我们将使用IBM Watson存储库中的Sales_Win_Loss数据集。我们将用pandas导入的数据集,用pandas的方法,如探索数据head(),tail(),dtypes(),然后试试我们的手在利用绘图技术,Seaborn可视化我们的数据。
然后,我们将深入研究scikit-learn,并preprocessing.LabelEncoder()在scikit-learn中使用它来处理数据,并将train_test_split()数据集拆分为测试样本和训练样本。我们还将使用备忘单来帮助我们决定对数据集使用哪种算法。最后,我们将使用accuracy_score()scikit-learn库提供的方法,使用三种不同的算法(朴素贝叶斯,LinearSVC,K-Neighbors分类器)进行预测并比较其性能。我们还将使用scikit-learn和Yellowbrick可视化来可视化不同模型的性能得分。
为了从大数据分析Python中Scikit-learn机器学习库中获得最大收益,您可能已经对以下内容感到满意:
1)pandas基础
2)Seaborn和Matplotlib基础
如果您需要复习这些主题,请查看这些pandas和数据可视化博客文章。
数据集
对于大数据分析Python中Scikit-learn机器学习库,我们将使用IBM Watson网站上可用的Sales-Win-Loss数据集。该数据集包含汽车零件批发供应商的销售活动数据。
我们将使用scikit-learn建立一个预测模型,以告诉我们哪些销售活动将导致亏损,哪些将导致获胜。
让我们从导入数据集开始。
导入数据集
首先,我们将导入pandas模块,并使用一个变量url来存储要从中下载数据集的url。

接下来,我们将使用read_csv()pandas模块提供的方法来读取csv包含逗号分隔值的文件,并将其转换为pandas DataFrame。

上面的代码片段返回一个变量sales_data,该变量现在存储在数据帧中。
对于那些不pd.read_csv()熟悉pandas的人,上面的代码中的方法将创建一个称为a的表格数据结构Dataframe,其中第一列包含唯一标记数据的每一行的索引,第一行包含每一列的标签/名称。这是从数据集中保留的原始列名。sales_data上面的代码片段中的变量将具有类似于下图所示的结构。

在上图中,row0,row1,row2是数据集中每个记录的索引,而col0,col1,col2等是数据集中每个列(功能)的列名。
现在,我们已经从数据源下载了数据集并将其转换为pandas数据框,现在让我们显示该数据框的一些记录。为此,我们将使用该head()方法。


从上面的显示中可以看出,该head()方法向我们显示了数据集中的前几条记录。该head()方法是pandas提供的一种非常漂亮的工具,可帮助我们了解数据集的内容。head()在下一节中,我们将详细讨论该方法。
数据探索
现在,我们已经下载了数据集并将其转换为pandas数据框,让我们快速浏览数据,看看数据可以告诉我们什么故事,以便我们计划行动方案。
在任何数据科学或机器学习项目中,数据探索都是非常重要的一步。即使快速浏览数据集也可以为我们提供否则可能会丢失的重要信息,并且该信息可以提出重要问题,我们可以尝试通过项目来回答。
为了探索数据集,我们将使用一些第三方Python库来帮助我们处理数据,以便可以与scikit-learn的强大算法有效地结合使用。但是我们可以从上head()一节中使用的相同方法开始,以查看导入的数据集的前几条记录,因为head()实际上它的功能远远超过此!我们可以自定义head()方法以仅显示特定数量的记录:


在上面的代码段中,我们在head()方法内部使用了一个参数,仅显示数据集中的前两个记录。参数中的整数“ 2” n=2实际上表示数据index帧的第二个Sales_data。使用此工具,我们可以快速了解必须处理的数据类型。例如,我们可以看到诸如“ Supplies Group”和“ Region”的列包含字符串数据,而诸如Opportunity Result,Opportunity Number等的列则包含整数。此外,我们可以看到“机会编号”列包含每条记录的唯一标识符。
现在我们已经查看了数据框的初始记录,让我们尝试查看数据集中的最后几条记录。可以使用tail()方法来完成此操作,该方法的语法与该head()方法相似。让我们看看该tail()方法可以做什么:


tail()上面的代码片段中的方法向我们返回了数据帧中的最后几条记录sales_data。我们也可以将参数传递给该tail()方法,以仅从数据框中查看有限数量的记录:

现在,我们只能查看数据框中的最后两个记录,如方法n=2内的参数所示tail()。与该head()方法类似,该方法的参数n=2中的整数“ 2” tail()指向数据集中最后两个记录中的第二个索引sales_data。
这最后两个记录告诉我们什么故事?从数据框中查看预告片记录的“机会编号”列,对于我们来说很明显,总共有78,024条记录可用。从该tail()方法显示的记录的“索引”编号可以明显看出这一点。
现在,如果我们能够看到此数据集中可用的不同数据类型,那就太好了;如果以后需要进行一些转换,此信息会很方便。我们可以使用dtypes()pandas中的方法来做到这一点:
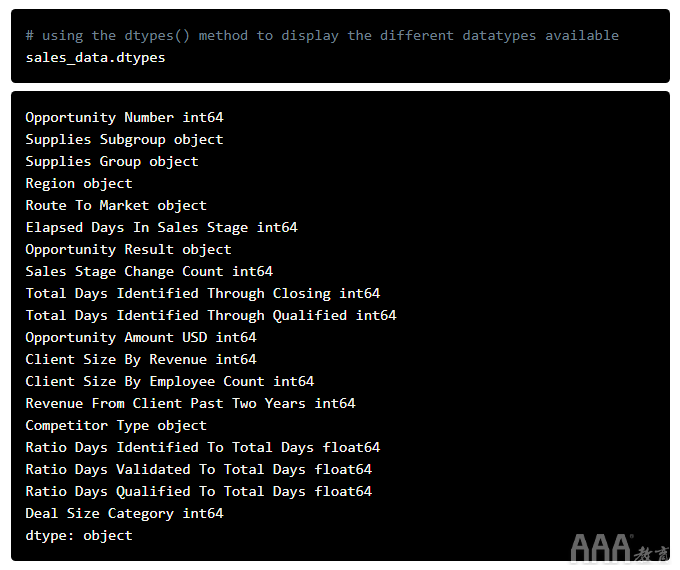
正如我们在上面的代码片段中看到的那样,使用该dtypes方法,我们可以列出Dataframe中可用的不同列以及它们各自的数据类型。例如,我们可以看到“耗材子组”列是object数据类型,“按收入划分的客户规模”列是integer数据类型。因此,现在我们知道哪些列中包含整数,哪些列中包含字符串数据。
数据可视化
现在,我们已经完成了一些基本的数据探索,让我们尝试创建一些漂亮的图来直观地表示数据并发现隐藏在数据集中的更多故事。
有许多python库提供用于进行数据可视化的功能。一个这样的库是Seaborn。要使用Seaborn绘图,我们应该确保已下载并安装了该python模块。
让我们设置使用Seaborn模块的代码:
现在我们已经完成了Seaborn的设置,让我们更深入地了解我们所做的事情。
首先,我们导入了Seaborn模块和matplotlib模块。set()下一行的方法有助于为绘图设置不同的属性,例如“样式”,“颜色”等。使用sns.set(style="whitegrid", color_codes=True)代码段将绘图的背景设置为浅色。然后,使用sns.set(rc={'figure.figsize':(11.7,8.27)})代码段设置地块大小,该代码段将地块图形大小定义为11.7px和8.27px。
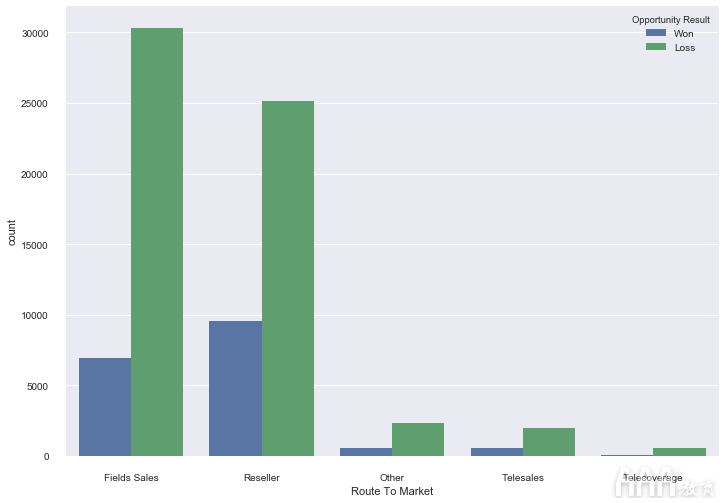
接下来,我们使用创建图sns.countplot('Route To Market',data=sales_data,hue = 'Opportunity Result')。该countplot()方法可帮助我们创建一个计数图,并公开了几个参数以根据需要定制计数图。在此,在方法的第一个参数中countplot(),我们将X轴定义为数据集中的“通往市场的路线”列。第二个参数是数据源,在这种情况下,它是sales_data我们在大数据分析Python中Scikit-learn机器学习库第一部分中创建的数据框。第三个参数是条形图的颜色,在数据框的“机会结果”列中,我们将其分配为标签“获胜”的标签为“蓝色”,为标签为“损失”的标签分配为“绿色” sales_data。
有关Seaborn计价器的更多详细信息,请参见此处。
那么,计数图告诉我们有关数据的信息是什么?第一件事是,数据集具有“亏损”类型的记录多于“获胜”类型的记录,从条形图的大小可以看出。查看x轴和x轴上每个标签的对应条形,我们可以看到数据集中的大多数数据都集中在图的左侧:朝向“现场销售”和“经销商”类别。要注意的另一件事是,“现场销售”类别的损失比“经销商”类别的损失更大。
我们选择了“市场路线”列,因为它在我们初步研究head()and tail()方法的输出后似乎会提供有用的信息。但是其他区域(例如“区域”,“供应组”等)也可以用于以相同方式绘制图。
现在我们已经对整体数据有了一个很好的可视化,让我们看看在其他Seaborn绘图的帮助下可以挖掘出更多的信息。另一个流行的选择是violinplots,因此让我们创建一个小提琴图,看看该图风格可以告诉我们什么。
我们将使用violinplot()Seaborn模块提供的方法来创建小提琴图。首先,导入seaborn模块并使用该set()方法来自定义绘图的大小。我们将看到图的大小为16.7px x 13.27px:
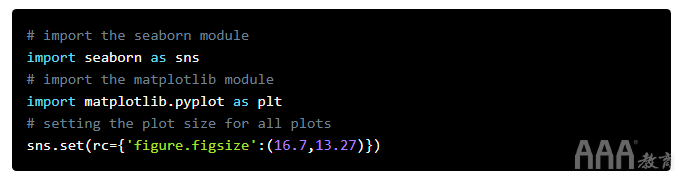
接下来,我们将使用该violinplot()方法创建小提琴图,然后使用show()方法来显示该图–

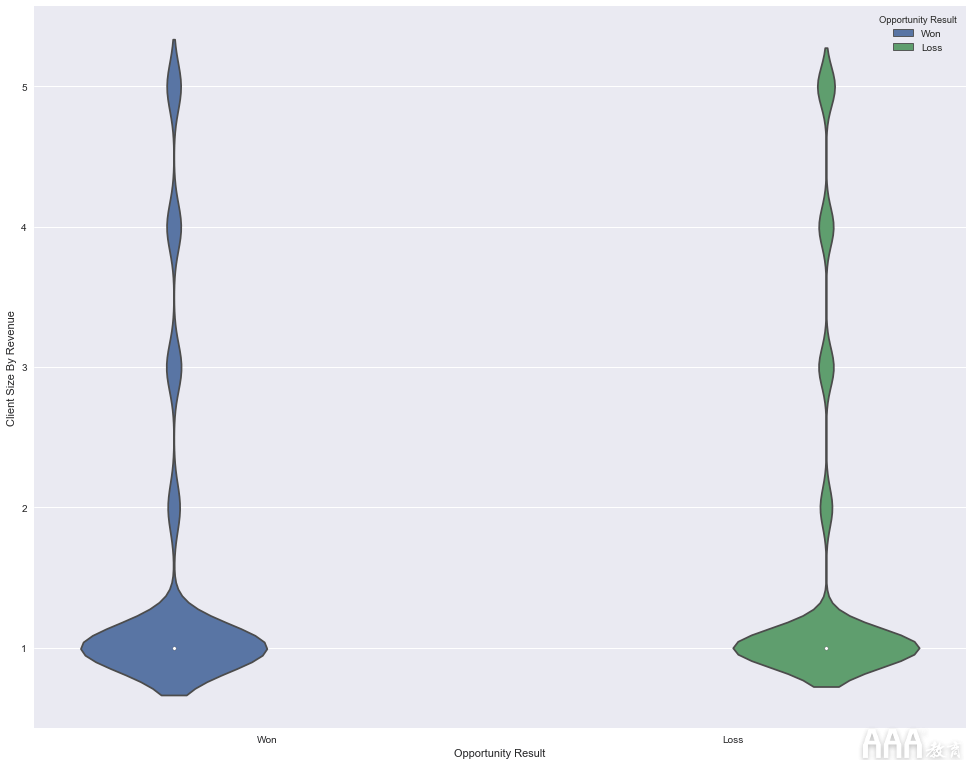
现在,我们的情节已经创建,让我们看看它告诉我们什么。小提琴图以最简单的形式显示标签上数据的分布。在上面的图中,我们在x轴上有标签“获胜”和“亏损”,在y轴上有“按收入划分的客户规模”的值。小提琴图显示出最大的数据分布是在客户端大小“ 1”中,其余的客户端大小标签中的数据较少。
该小提琴图使我们对数据的分布方式,哪些特征和标签具有最大的数据集中度具有非常有价值的洞察力,但是在小提琴图的情况下,所见之处不止于此。您可以通过该模块的官方文档更深入地了解小提琴图的其他用途Seaborn
预处理数据
既然我们对数据的外观有了很好的了解,我们就可以开始准备使用scikit-learn构建预测模型了。
在最初的探索中,我们看到数据集中的大多数列都是字符串,但是scikit-learn中的算法仅理解数字数据。幸运的是,scikit-learn库为我们提供了许多将字符串数据转换为数字数据的方法。一种这样的方法是该LabelEncoder()方法。我们将使用此方法将数据集中的分类标签(例如“赢”和“损失”)转换为数字标签。为了可视化我们试图通过该LabelEncoder()方法实现的目标,让我们考虑下图。
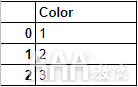
下图表示一个数据框,该数据框具有一个名为“ color”的列和三个记录“ Red”,“ Green”和“ Blue”的记录。

由于scikit-learn中的机器学习算法仅理解数字输入,因此我们希望将“红色”,“绿色”和“蓝色”等类别标签转换为数字标签。在原始数据帧中完成分类标签的转换后,我们将得到以下内容:
现在,让我们开始实际的转换过程。我们将使用fit_transform()提供的方法LabelEncoder()对分类框中的标签进行编码,例如sales_data数据框中的“通往市场的路线”,然后将它们转换为数字标签,类似于上图所示。该fit_transform()函数将用户定义的标签作为输入,然后返回编码的标签。让我们通过一个简单的示例来了解编码是如何完成的。在下面的代码示例中,我们有一个城市列表,即["paris", "paris", "tokyo", "amsterdam"],我们将尝试将这些字符串标签编码为类似于–的内容[2, 2, 1,3]。
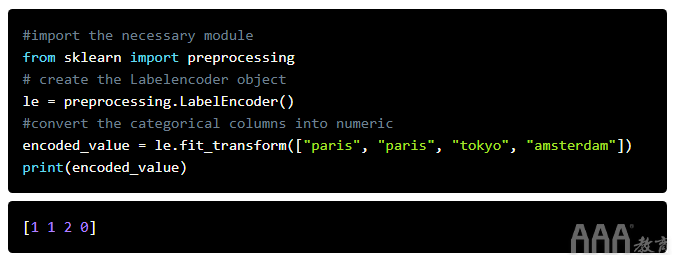
瞧!我们已经成功地将字符串标签转换为数字标签。我们怎么做到的?首先,我们导入了preprocessing提供该LabelEncoder()方法的模块。然后,我们创建了一个代表LabelEncoder()类型的对象。接下来,我们使用该对象的fit_transform()函数来区分列表的不同唯一类,["paris", "paris", "tokyo", "amsterdam"]然后返回带有相应编码值(即)的列表[1 1 2 0]。
请注意,该LabelEncoder()方法如何按照原始列表中类的第一个字母的顺序将数值分配给类:“(a)msterdam”获得的编码为“ 0”,“(p)aris获得的编码为1” ”和“(t)okyo”的编码为2。
在LabelEncoder()各种编码要求下,它们提供了许多方便的功能。我们在这里不需要它们,但是要了解更多信息,一个不错的起点是scikit-learn的官方页面,其中LabelEncoder()详细描述了及其相关功能。
由于我们现在对LabelEncoder()工作原理有了一个很好的了解,因此可以继续使用此方法对sales_data数据帧中的分类标签进行编码,并将其转换为数字标签。在对数据集进行初步探索的前几节中,我们看到以下各列包含字符串值:“供应子组”,“区域”,“进入市场的路线”,“机会结果”,“竞争对手类型”和“供应”组'。在开始编码这些字符串标签之前,让我们快速看一下这些列包含的不同标签:
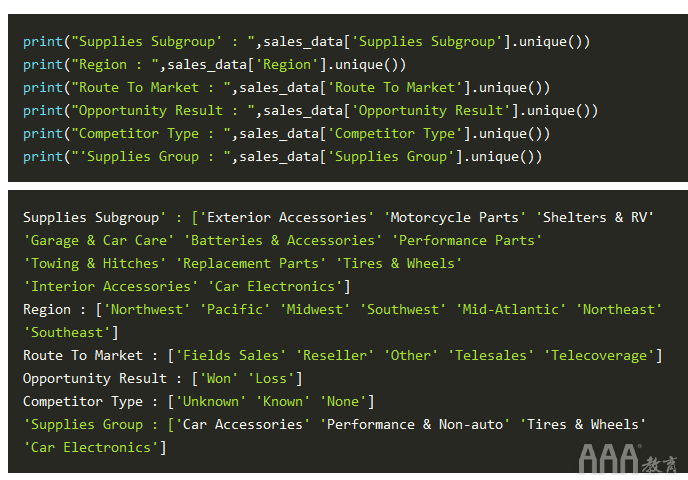
现在,我们从sales_data数据框中布置了不同的分类列,并在每个列下布置了唯一的类。现在,是时候将这些字符串编码为数字标签了。为此,我们将运行以下代码,然后深入研究其工作原理:
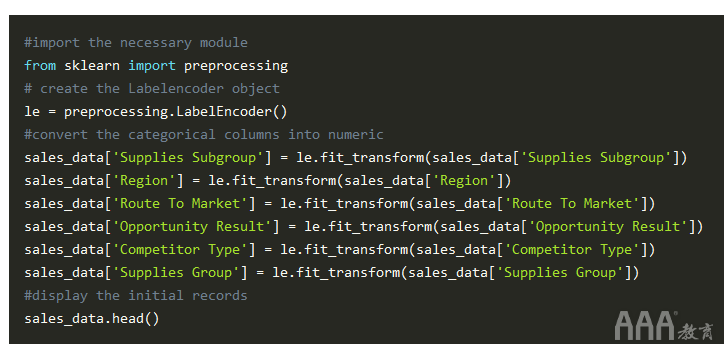

那我们刚才做了什么?首先,我们导入了preprocessing提供该LabelEncoder()方法的模块。然后,我们创建le了类型的对象labelEncoder()。在接下来的两行中,我们使用了fit_transform()提供的功能,LabelEncoder()并将不同列(例如“供应子组”,“区域”,“进入市场的路线”)的分类标签转换为数字标签。为此,我们成功地将所有分类(字符串)列转换为数值。
现在我们已经准备好数据并进行了转换,几乎可以将其用于构建我们的预测模型了。但是我们仍然需要做一件关键的事情:
训练集和测试集
需要在一组数据上训练机器学习算法,以学习不同特征之间的关系以及这些特征如何影响目标变量。为此,我们需要将整个数据集分为两组。一个是训练集,我们将在该训练集上训练算法以构建模型。另一个是测试集,我们将在该测试集上测试模型以查看其预测的准确性。
但是在进行所有拆分之前,我们先将功能和目标变量分开。和大数据分析Python中Scikit-learn机器学习库之前一样,我们将首先运行以下代码,然后仔细查看其功能:
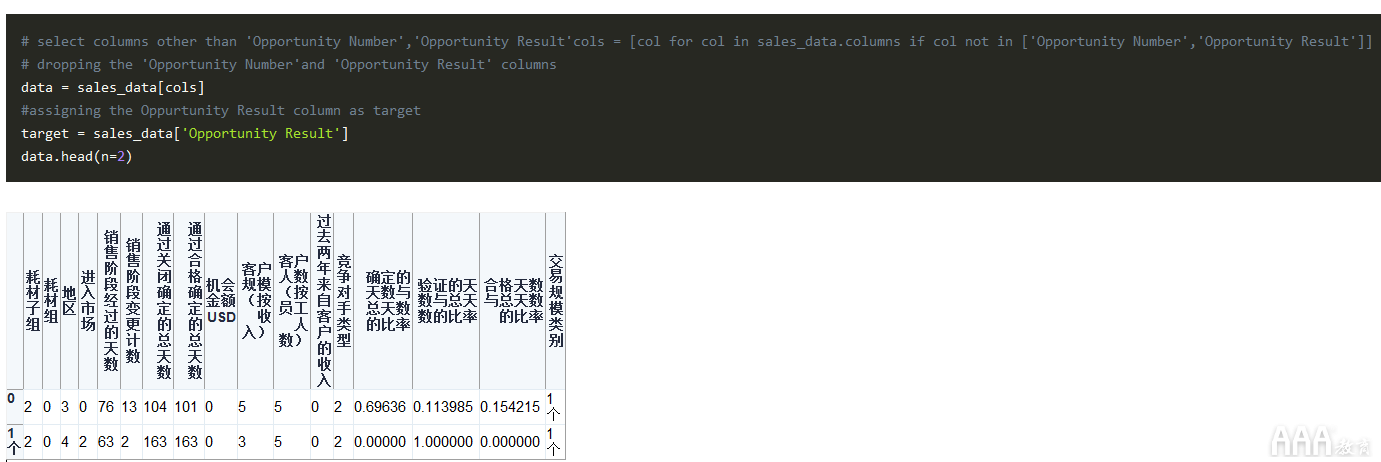
好,那我们刚才做了什么?首先,我们不需要“机会编号”列,因为它只是每条记录的唯一标识符。另外,我们要预测“机会结果”,因此它应该是我们的“目标”而不是“数据”的一部分。因此,在上述代码的第一行中,我们仅选择了与“商机编号”和“商机结果”不匹配的列,并将它们分配给了变量cols。接下来,我们data使用list中的列创建了一个新的数据框cols。这将用作我们的功能集。然后,我们从数据框中获取“机会结果”列,sales_data并创建了一个新的数据框target。
而已!我们已经准备好定义我们的功能并将目标定为两个单独的数据框。下一步,我们将分dataframes data并target投入到训练集和测试集。拆分数据集时,我们将保留30%的数据作为测试数据,其余70%作为训练数据。但是请记住,这些数字是任意的,最佳分割取决于您使用的特定数据。如果您不确定如何拆分数据,则将80%的数据保留为训练数据,而将其余20%的数据用作测试数据的80/20原则是不错的默认选择。但是,对于大数据分析Python中Scikit-learn机器学习库,我们将坚持我们先前的决定,即保留30%的数据作为测试数据。的train_test_split()在方法scikit学习可用于分割数据:

这样,我们现在已经成功地准备了测试集和培训集。在上面的代码中,我们首先导入了train_test_split模块。接下来,我们使用该train_test_split()方法将数据分为训练集(data_train,target_train)和测试集(data_test,data_train)。方法的第一个参数train_test_split()是我们在上一节中分离出的功能,第二个参数是target('Opportunity Result')。第三个参数'test_size'是我们想作为训练数据分开的数据的百分比。在我们的例子中是30%,尽管可以是任何数字。第四个参数“ random_state”仅确保我们每次都能获得可重复的结果。
现在,我们已经准备就绪,这是大数据分析Python中Scikit-learn机器学习库最重要,最有趣的部分:使用scikit-learn提供的庞大算法库构建预测模型。
建立模型
scikit Learn的网站上有machine_learning_map可用的内容,可供我们在选择算法时用作快速参考。看起来像这样:
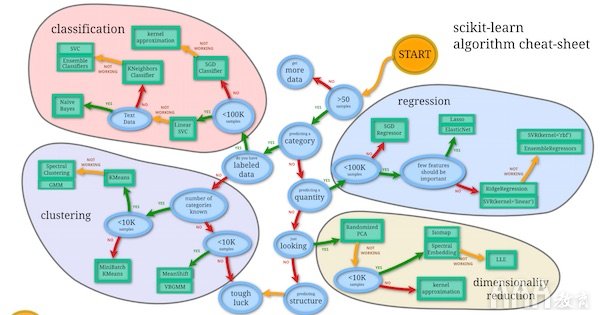
我们可以将此地图用作备忘单,以列出可以尝试构建预测模型的算法。使用清单,让我们看看我们属于哪一类:
1)超过50个样本–检查
2)我们要预测类别吗?
3)我们已经标记了数据?(带有明确名称的数据,例如机会金额等)–检查
4)少于10万个样本–检查
基于上面准备的清单,我们machine_learning_map可以尝试以下提到的算法。
1)朴素贝叶斯
2)线性SVC
3)K邻居分类器
scikit-learn库的真正优点在于,它公开了适用于不同算法的高级API,这使我们更容易尝试不同的算法并比较模型的准确性,从而确定最适合我们的数据集的方法。
让我们开始尝试一种不同的算法。
朴素贝叶斯
Scikit-learn提供了一组分类算法,这些分类算法“天真”地假设在数据集中每对特征都是独立的。这个假设是贝叶斯定理的基本原理。基于此原理的算法称为朴素贝叶斯算法。
在非常高的水平上,朴素贝叶斯算法会计算特征与目标变量的连接概率,然后选择概率最高的特征。让我们尝试通过一个非常简单的问题陈述来理解这一点:今天会下雨吗?假设我们拥有一组天气数据,这将成为我们的特征集,而“降雨”的概率将成为我们的目标。基于此功能集,我们可以创建一个表以向我们显示特定功能/目标对的出现次数。它看起来像这样:
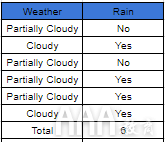
在上方的表格(列)中,“天气”包含标签(“部分多云”和“多云”),“雨”列包含与“天气”特征一致的降雨发生(是/否)。每当某个功能与下雨同时发生时,会记录为“是”,而当该功能没有导致下雨时,则会记录为“否”。现在,我们可以使用出现表中的数据来创建另一个表,称为“频率表”,在该表中,我们可以记录每个功能所涉及的“是”和“否”答案的数量:
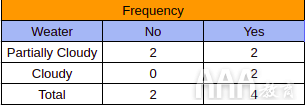
最后,我们结合来自“出现表”和“频率表”的数据,并创建一个“可能性表”。下表列出了每个功能部件的“是”和“否”的数量,然后使用此数据来计算每个功能部件对降雨的影响概率:
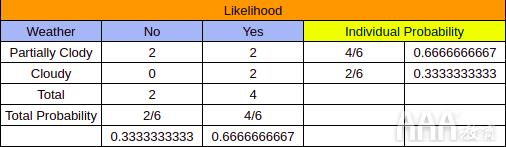
请注意上表中的“个体概率”列。我们从“出现表”和“似然表”中出现了6次“部分多云”和“多云”特征,很明显,特征“部分多云”有4次出现(对于“否”为2次,对于“部分多云”为2次。 '是')。当我们将特定特征的“否”和“是”的出现次数除以“出现表”的“总数”时,我们就可以得出该特定特征的概率。在我们的案例中,如果我们需要找出哪个要素最有可能促成降雨的发生,那么我们将每个要素的“否”总数取为“”,然后将其加到“频率表”,然后将总和除以“合计表”中的“总计”。
我们将用于销售数据的算法是Gaussian Naive Bayes,它基于与上面刚刚探讨的天气示例类似的概念,尽管在数学上要复杂得多。对于那些想深入研究的人,可以在这里找到“朴素贝叶斯”算法的更详细说明。
现在,让我们实现GaussianNBscikit-learn 的高斯朴素贝叶斯或算法来创建我们的预测模型:
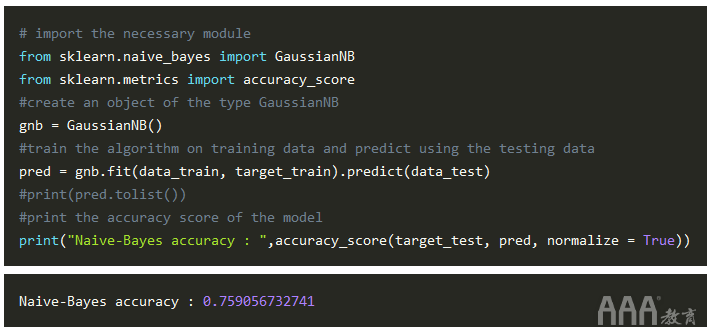
现在,让我们仔细看看我们所做的。首先,我们导入了GaussianNB方法和accuracy_score方法。然后,我们创建gnb了类型的对象GaussianNB。此后,我们使用该fit()方法对测试数据(data_train)和测试目标(target_train)进行了算法训练,然后使用该方法预测了测试数据中的目标predict()。最后,我们使用该accuracy_score()方法打印了分数,并以此成功地将Naive-Bayes算法应用到了预测模型中。
现在,让我们看看列表中的其他算法与Naive-Bayes算法相比的性能如何。
线性SVC
LinearSVC或线性支持向量分类是SVM(支持向量机)类的子类。我们不会涉及这类算法中的数学的复杂性,但是在最基本的层次上,LinearSVC会尝试将数据划分为不同的平面,以便可以找到不同类别的最佳分组。为了清楚地了解这个概念,让我们想象一下“点”和“正方形”的数据集沿两个轴分为二维空间,如下图所示:
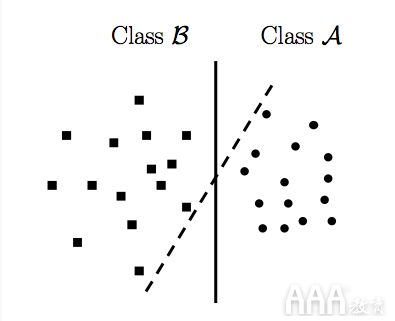
在上面的图像中,一种LinearSVC实现方式尝试以这种方式划分二维空间,以使两类数据(即dots和)squares被清晰地划分。在这里,这两行直观地表示了LinearSVC试图实现以区分出两个可用类的各种划分。
对于那些想了解更多细节的人,Support Vector Machine(SVM)可以在这里找到一篇很好的解释a的文章,但是现在,让我们深入研究一下,让我们变得肮脏:
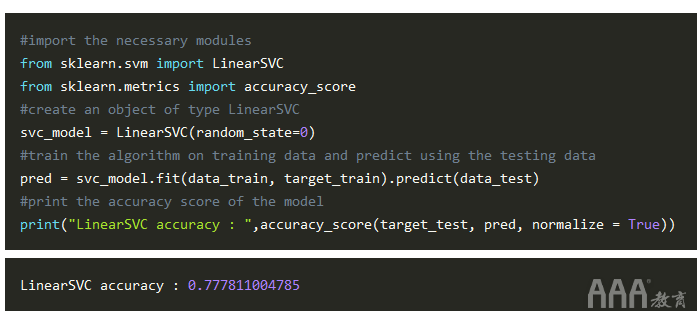
与在实施GaussianNB期间所做的类似,我们在前两行中导入了所需的模块。然后,我们创建了svc_model类型为LinearSVC 的对象,其中random_state为'0'。坚持,稍等!什么是“ random_state”?简单地说,random_state是对内置随机数生成器的一条指令,以特定顺序对数据进行随机排序。
接下来,我们在训练数据上训练了LinearSVC,然后使用测试数据预测了目标。最后,我们使用该accuracy_score()方法检查了准确性得分。
现在我们已经尝试了GaussianNB和LinearSVC算法,我们将尝试列表中的最后一个算法,那就是K-nearest neighbours classifier
K邻居分类器
与我们之前使用的两种算法相比,该分类器稍微复杂一些。就大数据分析Python中Scikit-learn机器学习库而言,最好使用KNeighborsClassifierscikit-learn提供的类,而不必担心算法的工作原理。(但是,如果您有兴趣,可以在此处找到有关此类算法的非常详细的说明)
现在,让我们实现K-Neighbors分类器并查看其得分:
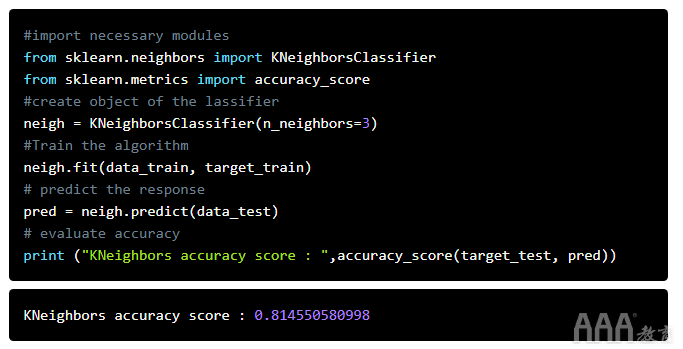
可以像前面的实现一样解释上面的代码。首先,我们导入了必要的模块,然后创建了neighKNeighborsClassifier类型的对象,其邻居数为n_neighbors=3。然后,我们使用该fit()方法在训练集上训练算法,然后在测试数据上测试了模型。最后,我们打印出准确性得分。
现在我们已经实现了列表中的所有算法,我们可以简单地比较所有模型的得分以选择得分最高的模型。但是,如果我们有一种视觉上比较不同模型性能的方法,那会不会很好?我们可以yellowbrick在scikit-learn中使用该库,该库提供了直观地表示不同评分方法的方法。
性能比较
在前面的部分中,我们使用了该accuracy_score()方法来测量不同算法的准确性。现在,我们将使用库ClassificationReport提供的类为我们提供有关Yellowbrick模型性能的直观报告。
高斯NB
让我们从GaussianNB模型开始:
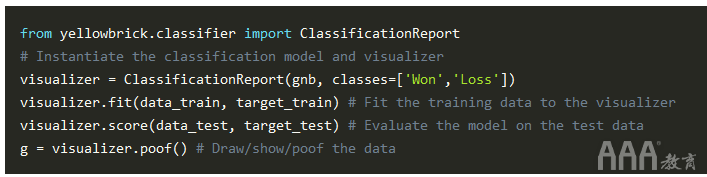
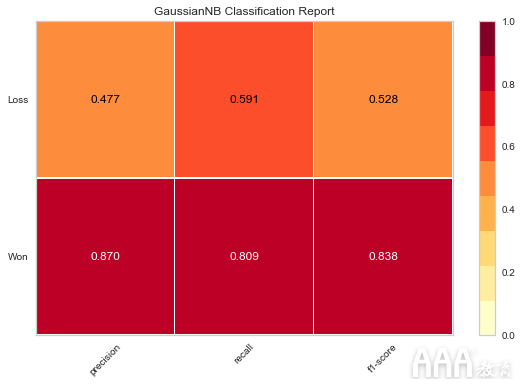
在上面的代码中,首先我们导入模块ClassificationReport提供的类yellowbrick.classifier。接下来,创建visualizer该类型的对象ClassificationReport。这里的第一个参数是在实现“朴素贝叶斯”部分中的算法时创建的GaussianNB对象。第二个参数包含数据框“机会结果”列中的标签“获胜”和“损失” 。gnbNaive-Bayessales_data
接下来,我们使用该fit()方法来训练visualizer对象。接下来是该score()方法,该方法使用gnb对象根据GaussianNB算法执行预测,然后计算该算法做出的预测的准确性得分。最后,我们使用该poof()方法为GaussianNB算法绘制不同分数的图。请注意,如何分别对“ Won”和“ Loss”标签布置不同的分数;这使我们能够可视化不同目标类别的分数。
线性SVC
与我们在上一节中所做的类似,我们还可以绘制LinearSVC算法的准确性得分:
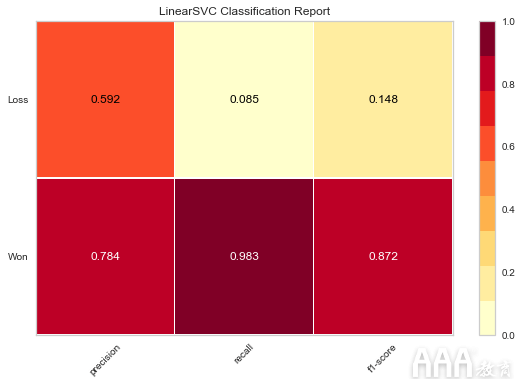
在上面的代码中,首先我们导入ClassificationReport了yellowbrick.classifier模块提供的类。接下来,创建一个visualizer类型的对象ClassificationReport。这里的第一个参数是LinearSVCobject svc_model,它是LinearSVC在“ LinearSVC”部分中实现算法时创建的。第二个参数包含sales_data数据框“机会结果”列中的标签“获胜”和“损失” 。
接下来,我们使用该fit()方法来训练“ svc_model”对象。接下来是score()一种方法,该方法使用svc_model对象根据LinearSVC算法进行预测,然后计算由该算法得出的预测的准确性得分。最后,我们使用该poof()方法为LinearSVC算法绘制了不同分数的图。
KNeighborsClassifier
现在,让我们对K邻居分类器分数做同样的事情。
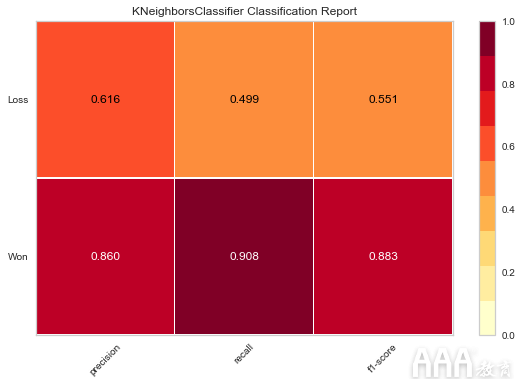
再一次,我们首先导入模块ClassificationReport提供的类yellowbrick.classifier。接下来,创建visualizer该类型的对象ClassificationReport。这里的第一个参数是KNeighborsClassifierobject neigh,它是在实现KNeighborsClassifier“ KNeighborsClassifier”部分中的算法时创建的。第二个参数包含sales_data数据框“机会结果”列中的标签“获胜”和“损失” 。
接下来,我们使用该fit()方法训练“邻居”对象。接下来是score()一种方法,该方法使用neigh对象根据KNeighborsClassifier算法进行预测,然后计算由该算法得出的预测的准确性得分。最后,我们使用该poof()方法为KNeighborsClassifier算法绘制了不同分数的图。
现在我们已经可视化了结果,现在我们可以轻松比较分数并选择最能满足我们需求的算法。
结论
scikit-learn库提供了许多不同的算法,这些算法可以导入到代码中,然后用于构建模型,就像我们导入其他任何Python库一样。这使快速构建不同模型并比较这些模型以选择得分最高的模型变得更加容易。
在大数据分析Python中Scikit-learn机器学习库中,我们仅介绍了scikit-learn库所能提供的功能。为了最大程度地使用此机器学习库,scikit-learn的官方页面上提供了许多资源,并提供了详细的文档供您参考。scikit-learn的快速入门指南可以在这里找到,对于刚开始探索机器学习世界的初学者来说,这是一个很好的切入点。
但是要真正欣赏scikit-learn库的真正功能,您真正需要做的是开始在不同的开放数据集上使用它,并使用这些数据集建立预测模型。开放数据集的来源包括Kaggle和Data.world。两者都包含许多有趣的数据集,可以使用scikit-learn库提供的算法在这些数据集上练习构建预测模型。
摘自:https://www.aaa-cg.com.cn/data/2663.html