前言
帮朋友做一份数据处理,但是由于对excel的不熟悉,所以还是使用了python去做。本文主要是简单的python处理excel数据,具体服务于特定形式的excel表格
一、用到的模块是什么?
- xlrd
主要用于读取excel文件(由于一开始没有用到xlwings去读,所以后面也懒得改了)
- xlwings
主要是用于写excel文件(因为xlwt写好像只能一次处理256列,所有后面用到xlwings去写)
二、execl表格的样式
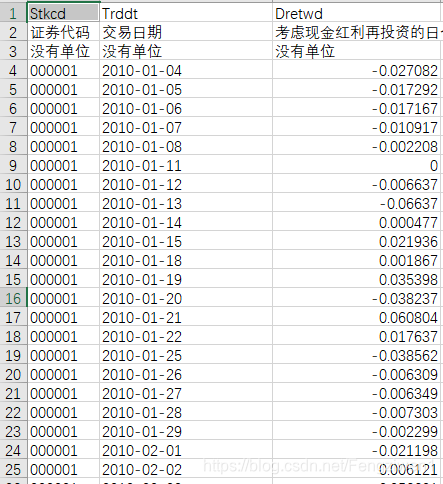
上图是要处理的excel表格,主要是有两个关注点:一是证券代码,二是回报率。每个股票都每一天都有不一样的回报率,这一张表中大概有43万条数据,而我要做的就是将数据整合在另一个表中,就是下图中的表。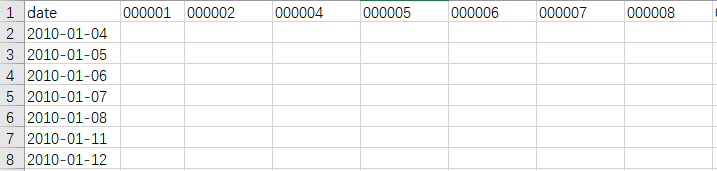
上图中关注的重点就是第一行的数据,而时间则是不太需要关注的,因为从第一张表的所得到的数据的时间已经是有序排列的了。
三、模块的使用
1.引入模块
代码如下(示例):
import xlrd
import xlwings as xw
import time #可不用
from progressbar import ProgressBar, Percentage, Bar #可不用
2.读取excel表数据
代码如下(示例):
sheet_done= xlrd.open_workbook(done_file_name).sheet_by_index(0)
for i in range(sheet_done.ncols): # 获取需要的证券代码
value.append(sheet_done.col_values(i))
该处主要是xlrd的使用。
3.将写入excel表
代码如下(示例):
app = xw.App(visible=False, add_book=False)
app.display_alerts = False
app.screen_updating = False
wb = app.books.open(file)
sheet.range('A1').options(transpose=True).value = list1
wb.save()
wb.close()
app.quit()
该处主要是xlwings的使用。
四、代码分析
1.代码逻辑
首先根据两个表的类似点可以得出,只要将股票号与回报率作一一对应就好了,时间已经是个有序排列了,在此可以忽略。那整个代码的逻辑就是要先将股票号跟回报率所关联起来,接着就另一个excel表中一列一列的写就好了。
2.选出有用的股票号并与回报率关联
代码如下(示例):
for i in range(sheet_done.ncols): # 获取需要的证券代码
value.append(sheet_done.col_values(i))
def set_dic(dic, value):
for i in range(len(value) - 1):
global_num.append(value[i + 1][0])
dic[value[i + 1][0]] = 0
由于最后需要的股票号不一定与全部数据中的股票号所对应,所以要先筛选出需要用到的股票号。然后运用字典,key则是股票号,key所对应的值就是每支股票每天的回报率,刚好我们后面使用的写excel的函数也是需要用到列表。

设置好关联后大概是这个样子的,后面就是往里面填入数据
3.将全部数据按照所需要的股票号进行分类
代码如下(示例):
def get_rate_by_num(num, value):
"""
根据股票分类相对应的利率
:param num: 股票编号
:param value: 整张表格数据
:return:
"""
print("开始分类数据:" + time.strftime("%Y-%m-%d %H:%M:%S"))
for i in range(len(value)):
if value[i][0] == "000001":
break
current_row = i
offset = 0
rate = []
for i in range(len(num)):
for j in range(len(value) - current_row): # 去除无用数据 开始轮询
j = j + offset
if num[i] == value[j + current_row][0]: # 判断是否是需要的数据
rate.append(value[j + current_row][2]) # 将需要的数据放入rate[]
if j + current_row == len(value) - 1: # 判断是否为最后一个数据
break
else:
if check_num(value[j + current_row][0]): # 判断数据是否是需要的
offset = j # 下次轮询就从上一个数据的末尾开始
break
else:
continue
global_value[num[i]] = rate
rate = []
print("结束分类数据:" + time.strftime("%Y-%m-%d %H:%M:%S"))
这里就是根据之前得出的有效股票号去进行轮询整张表格去进行匹配,然后将匹配到的值放入上面的字典中。这里有个小窍门就是根据我们的excel格式可以得出股票号都是按顺序来的,只要完成这一次股票号的分类后,那么接下来就不会再出现相同的股票号。所以每次轮询的使用不用由头到尾进行,只需要从每次分类好后的坐标进行轮询就好了。这里一开始我是每次都由头到尾进行查找,耗时可能都有30分钟了,后面改了后只需几秒。

4.将分类好的数据写入excel
代码如下(示例):
def write_excel_by_num(file):
"""
根据对应的股票号,将相对应的数据写入excel列中
:param num: 股票号
:param value: 数据
:return: None
"""
print("开始写excel:" + time.strftime("%Y-%m-%d %H:%M:%S"))
app = xw.App(visible=False, add_book=False)
app.display_alerts = False
app.screen_updating = False
wb = app.books.open(file)
progress_bar = ProgressBar(widgets=["正在写入", Percentage(), Bar()], maxval=len(global_value.keys())).start()
sheet = wb.sheets['Sheet1']
for i in range(len(global_value.keys())):
progress_bar.update(i)
sheet.range(get_cell_num(i + 1, cell_num_list)).options(transpose=True).value \
= global_value[list(global_value.keys())[i]]
progress_bar.finish()
wb.save()
wb.close()
app.quit()
print("结束写excel:" + time.strftime("%Y-%m-%d %H:%M:%S"))
写excel这边就是逐列写入,但由于不知道怎么确定写的时候那一列的单元格编号所以需要写一个函数根据这个数据在excel表格中的位置对应出他的单元格编号,get_cell_num()就是可以得到对应的单元格编号
五、成果展示
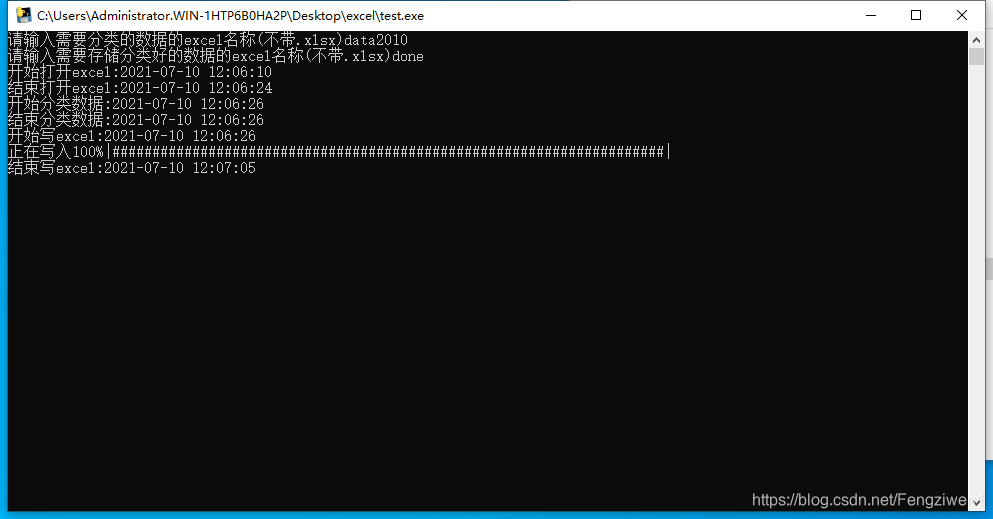
在打开excel跟写excel的时候还是比较慢的,但分类40万个数据还是挺快的。处理一次数据(40万左右)并写入新的excel表中大概是要2分钟的样子。

总结
本来主要是将excel数据分类导入至另一个excel表中,但对两个表的样式有比较高的要求,换了个样式就无法使用了。所以还是觉得应该用excel能有更好的方法,或者python里面别的模块处理上能更方便。要是有更好的方法,请留言告知我一声,谢谢!