并发编程
1、java线程
1.1 创建线程
1.1.1 Thread
//匿名内部类实现Thread线程
new Thread("t1"){
@Override
public void run() {
// ...
}
}.start();
1.1.2 Runnable
new Thread(new Runnable() {
@Override
public void run() {
// ...
}
}).start();
//可以使用lambda表达式简化
new Thread(() -> {
// ...
}).start();
1.1.3 FutureTask
FutureTask<Integer> task = new FutureTask<Integer>(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
return 100;
}
});
new Thread(task).start();
Integer i = task.get();
//也可以使用lambda表达式简化
FutureTask<Integer> task = new FutureTask<>(() -> 100);
new Thread(task).start();
//会阻塞当前线程,直到对应有返回值的线程结束
Object o=task.get();
1.1.4 CompletableFuture
没有指定Executor的方法,直接使用默认的ForkJoinPool.commonPool()作为它的线程池执行异步代码
- runAsync: 无返回值
- supplyAsync: 有返回值
// 无返回值
CompletableFuture<Void> future1 = CompletableFuture.runAsync(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
// 有返回值
CompletableFuture<String> future2 = CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
return "aaaa";
}
});
String s = future2.get();
简单使用:
chain链式编程
CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
return "aaaa";
}
}).whenComplete((value,error) -> {
if (error == null) {
System.out.println(value);
}
}).exceptionally(error -> {
error.printStackTrace();
return null;
});
1.2 原理与线程
1.2.1 栈与栈帧
Java Virtual Machine Stacks(Java虚拟机栈)
我们都知道JVM中由堆、栈、方法区所组成,其中栈内存是给谁用的呢?其实就是线程,每个线程启动
后,虚拟机就会为其分配一块栈内存。
- 每个栈由多个栈帧(Frame)组成,对应着每次方法调用时所占用的内存
- 每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法
1.2.2 线程上下文切换(Thread Context Switch)
因为以下一些原因导致CPU不再执行当前的线程,转而执行另一个线程的代码
- 线程的CPU时间片用完
- 垃圾回收
- 有更高优先级的线程需要运行
- 线程自己调用了sleep、yield、wait、join、park、synchronized、lock等方法
当Context Switch发生时,需要由操作系统保存当前线程的状态,并恢复另一个线程的状态,Java中对应的
概念就是程序计数器(Program Counter Register),它的作用是记住下一条JVM指令的执行地址,是线程私有
的
- 状态包括程序计数器、虚拟机栈中每个栈帧的信息,如局部变量、操作数栈、返回地址等
- Context Switch频繁发生会影响性能
1.3 interrupt方法详解
//打断调用线程,设置打断标记
t1.interrupt()
//两种判断打断标记的方法
//静态方法,判断当前线程的打断标记,并清空打断标记(设置为false)
Thread.interrputed()
//成员方法,判断当前线程的打断标记
Thread.currentThread.isInterrupted()
1.3.1 打断sleep、wait、join的线程
此时会清空打断标记,并且抛出异常,结束当前等待,打断标记默认为false
Thread t1 = new Thread(()->{
try {
Thread.sleep(1000); //这时候被打断会抛出异常
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
},"t1");
t1.start();
Thread.sleep(500);
t1.interrupt(); //打断t1线程的sleep
System.out.println(t1.isInterrupted()); //输出为false
1.3.2 打断正常运行的线程
此时会把打断标记设置为true,不会影响线程的正常运行,可以在线程中使用isInterrupt方法自行判断退出
Thread t1 = new Thread(()->{
while(true){
if(Thread.currentThread().isInterrupted()){
break; //自行判断是否有人打断,自行退出
}
}
},"t1");
t1.start();
Thread.sleep(500);
t1.interrupt();
System.out.println(t1.isInterrupted()); //此时输出true
1.3.2 打断LockSupport的park
此时线程不会在park等待unpark才继续执行,直接正常执行后续代码,但是在打断标记为true时,再进行park操作也无法停下
Thread t1 = new Thread(()->{
LockSupport.park();
log.debug("被打断了,执行后续代码");
LockSupport.park();
log.debug("后续的park还是无法继续停下执行");
},"t1");
t1.start();
Thread.sleep(500);
t1.interrupt();
1.4 守护线程
把调用线程设置为当前线程的守护线程,但当前线程执行完毕后,守护线程会自动提前结束
Thread t1 = new Thread(()->{
while (true) {
}
},"t1");
t1.setDaemon(true);
t1.start();
Thread.sleep(500);
log.debug("主线程结束了");
2、锁
2.1 Monitor概念
2.1.1 java对象头
32位虚拟机为例:
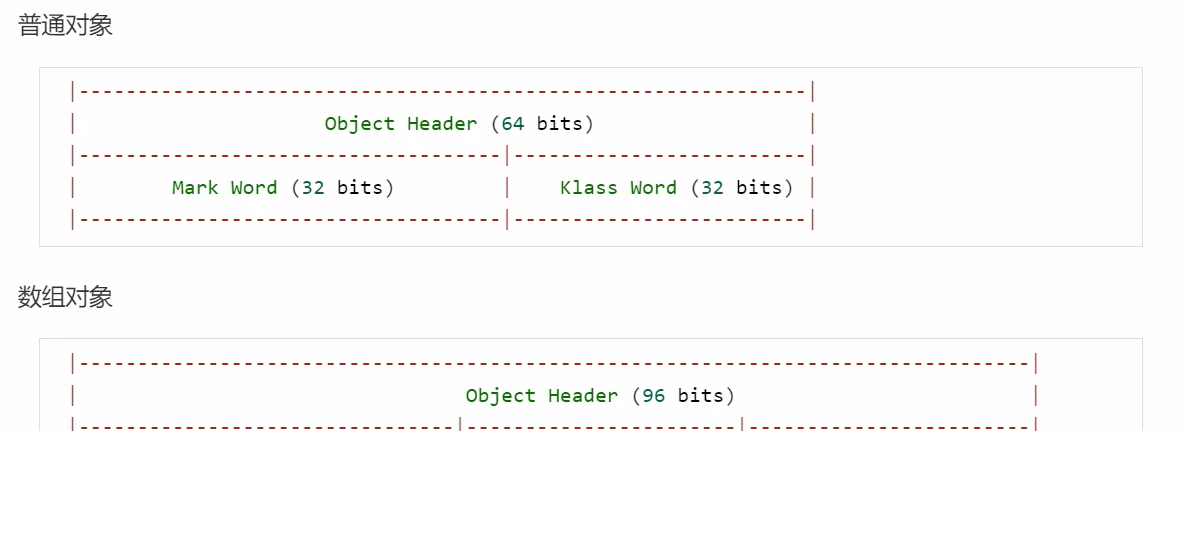
其中Mark Word的结构如下:
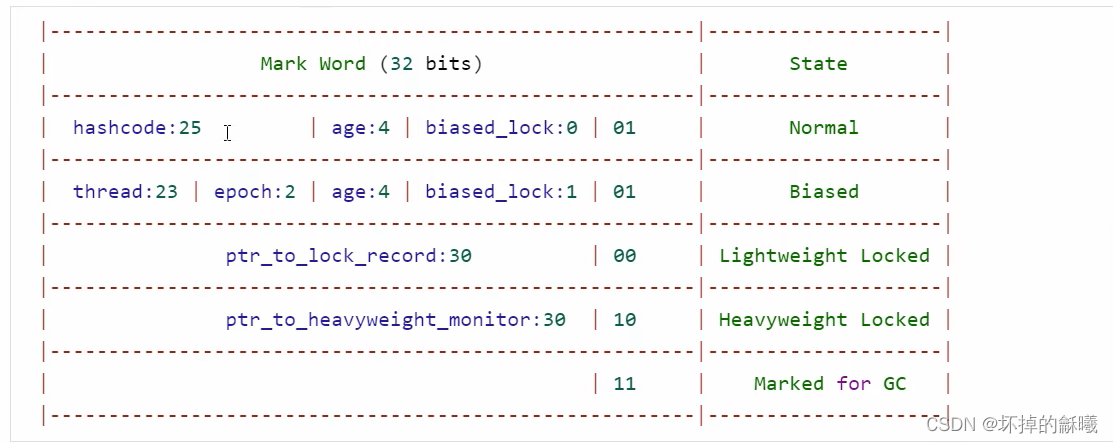
- normal: 正常不加锁状态
- biased: 偏向锁状态,当第一个进程获得锁后,记录偏向的线程的id在thread,当有其他的线程来获得锁后取消偏向锁
- Lightweight Locked: 轻量级锁,当有不同的线程有同时竞争锁时,进行锁膨胀,变为重量级锁
- Heavyweight Locked: 重量级锁,使用Monitor来进行多线程对锁竞争的管理
- Marked for GC: 对象被GC垃圾回收后的Mark Word状态
2.1.2 Monitor
monitor结构如下
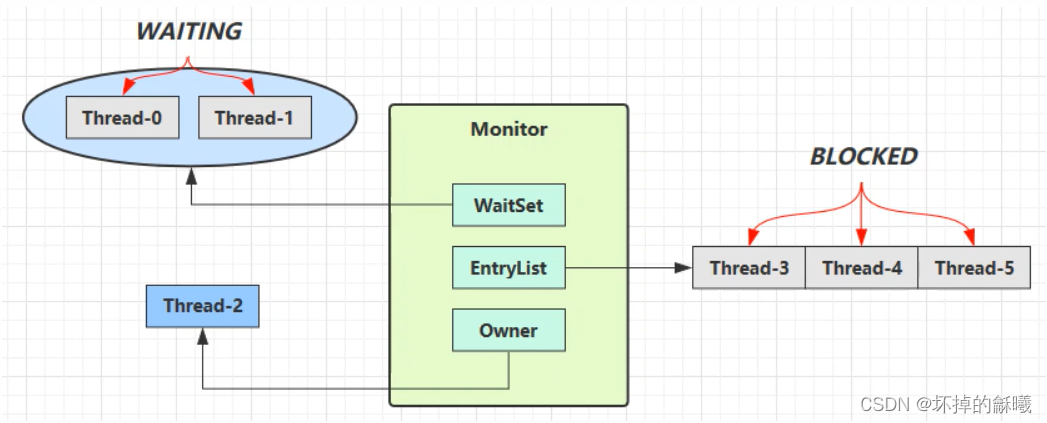
- 刚开始Monitor中Owner为null
- 当Thread-2执行synchronized(obj)就会将Monitor的所有者Owner置为Thread-2,Monitor中只能有一个
Owner
- 在Thread-2上锁的过程中,如果Thread–3,Thread-4,Thread-5也来执行synchronized(obj),就会进入
EntryList BLOCKED
- Thread-2执行完同步代码块的内容,然后唤醒EntryList中等待的线程来竞争锁,竞争的时是非公平的
- 图中WaitSet中的Thread-O,Thread-l是之前获得过锁,但条件不满足进入WAITING状态的线程,后面
讲wait-notify时会分析
2.2 synchronized
语法:
synchronized(对象){
// 临界区
}
2.2.1 wait/notify
在多个线程竞争锁时,锁变为重量级锁,使用Monitor结构
当一个线程获得锁后条件暂不满足,执行不了临界区的后续代码,可以使用wait来进入WaitSet中等待
当其他获得锁的线程使用锁对象的notify/notifyAll方法后会把WaitSet中的线程唤醒,重新进入EntryList尝试获取锁执行后续代码
2.3 LockSupport
语法:
LockSupport.park();
LockSupport.unpark(目标线程对象);
特点:
与Object的wait¬ify相比
- wait,notify和notifyAll必须配合Object Monitor一起使用,而park,unpark不必
- park&unpark是以线程为单位来【阻塞】和【唤醒】线程,而notify只能随机唤醒一个等待线程,
notifyA1l是唤醒所有等待线程,就不那么【精确】
- park&unpark可以先unpark,而wait¬ify不能先notify
- 当打断标记为true时,不会进入阻塞状态
2.3.1 原理
每个线程都有自己的一个Parker对象,由三部分组成_Counter,_Cond和_Mutex打个比喻
- 线程就像一个旅人,Parker就像他随身携带的背包,条件变量就好比背包中的帐篷。counter就好比背包
中的备用干粮(0为耗尽,1为充足)
- 调用park就是要看需不需要停下来歇息
- 如果备用干粮耗尽,那么钻进帐篷歇息
- 如果备用干粮充足,那么不需停留,继续前进
- 调用unpark,就好比令干粮充足
- 如果这时线程还在帐篷,就唤醒让他继续前进
- 如果这时线程还在运行,那么下次他调用pak时,仅是消耗掉备用干粮,不需停留继续前进
- 因为背包空间有限,多次调用unpark仅会补充一份备用干粮
2.4 ReentrantLock
相对于synchronized它具备如下特点
- 可中断
- 可以设置超时时间
- 可以设置为公平锁
- 支持多个条件变量
- 与synchronized一样,都支持可重入
语法:
ReentrantLock lock = new ReentrantLock();
// 获取锁
lock.lock();
try{
// 临界区
}finally{
// 释放锁
lock.unlock();
}
可重入:
可重入是指同一个线程如果首次获得了这把锁,那么因为它是这把锁的拥有者,因此有权利再次获取这把锁
如果是不可重入锁,那么第二次获得锁时,自己也会被锁挡住
2.4.1 可打断
语法:
//获得可打断锁,防止死等
lock.lockInterruptibly();
2.4.2 尝试获得锁
语法:
//返回false,代表获得不到锁,获得则放回true
lock.tryLock();
//设置尝试等待时间
lock.tryLock(1,TimeUnit.SECONDS);
2.4.3 公平锁
ReentrantLock默认是不公平的
ReentrantLock lock = new ReentrantLock(true);
2.4.4 条件变量
synchronized中也有条件变量,就是我们讲原理时那个waitSet休息室,当条件不满足时进入waitSet等待
ReentrantLock的条件变量比synchronized强大之处在于,它是支持多个条件变量的,这就好比
- synchronized是那些不满足条件的线程都在一间休息室等消息
- 而ReentrantLock支持多间休息室,有专门等烟的休息室、专门等早餐的休息室、唤醒时也是按休息室来
唤醒
语法:
Condition waitcigaretteQueue lock.newCondition();
Condition waitbreakfastQueue lock.newCondition();
waitcigaretteQueue.await();
waitcigaretteQueue.signal();
waitcigaretteQueue.signalAll();
3、共享模型内存
在线程中有三大特性需要保证来提升线程的安全与需求实现:
volatile:
-
如果线程要频繁从主内存中读取number的值,JIT编译器会将number的值缓存至自己工作内存中的高速缓存
中,减少对主存中un的访问,提高效率
-
其他线程修改了number的值,并同步至主存,而t是从自己工作内存中的高速缓存中读取这个变
量的值,结果永远是旧值,无法实现新的读取,导致无法完成想要的结果
-
synchronized语句块既可以保证代码块的原子性,也同时保证代码块内变量的可见性。但缺点是
synchronized是属于重量级操作,性能相对更低
-
对变量加上volatile就可以保证变量的可见性,线程每次读取就不会从缓存中读取。
3.1 如何保证可见性
- 写屏障(sfence) 保证在该屏障之前的,对共享变量的改动,都同步到主存当中
public void actor2(I_Result r){
num =2;
ready=true;//ready是volatile赋值带写屏障
//写屏障
}
- 而读屏障(1 fence)保证在该屏障之后,对共享变量的读取,加载的是主存中最新数据
public void actor1(I_Result r){
//读屏障
//ready是volatile读取值带读屏障
if(ready){
r.r1 numnum;
} else{
r.r1=1;
}
}
3.2 如何保证有序性
- 写屏障仅仅是保证之后的读能够读到最新的结果,但不能保证读跑到它前面去
- 而有序性的保证也只是保证了本线程内相关代码不被重排序
4、CAS乐观锁
4.1 CAS的特点
结合CAS和volatile可以实现无锁并发,适用于线程数少、多核CPU的场景下。
- CAS是基于乐观锁的思想:最乐观的估计,不怕别的线程来修改共享变量,就算改了也没关系,我吃亏
点再重试呗。
- synchronized是基于悲观锁的思想:最悲观的估计,得防着其它线程来修改共享变量,我上了锁你们都别
想改,我改完了解开锁,你们才有机会。
- CAS体现的是无锁并发、无阻塞并发
- 因为没有使用synchronized,所以线程不会陷入阻塞,这是效率提升的因素之一
- 但如果竞争激烈,可以想到重试必然频繁发生,反而效率会受影响
4.2 原子整数
- AtomicBooleanI
- AtomicInteger
- AtomicLong
以AtomicInteger为例
简单使用:
public AtomicInteger value=new AtomicInteger(1);
public void increment() {
while(true){
int prev = value.get();
int next = prev + 1;
//当运行这个语句时会检查此时的value的值和prev比较,相同才会去修改,返回true
//这个操作时原子的
if(!value.compareAndSet(prev, next)){
break;
}
}
}
value.getAndIncrement(); // i++
value.incrementAndGet(); // ++i
value.getAndAdd(10);
value.addAndGet(10);
value.updateAndGet(num-> num * 10);
value.getAndUpdate(num-> num * 10);
4.3 原子引用
- AtomicReference
- AtomicMarkableReference
- AtomicStampedReference
4.3.1 AtomicReference
public AtomicReference<String> reference=new AtomicReference<String>("a");
public void change(String s){
while(true){
String prev = reference.get();
String next = prev + s;
if(reference.compareAndSet(prev,next)){
break;
}
}
}
但是此方法只能判断值与之前获得的值相同
如果中途有其他线程修改值后又修改回当前线程之前获得的值,当前线程的compareAndSet方法是不会发现有其他线程修改了的,此时我们就需要使用AtomicStampedReference
4.3.2 AtomicStampedReference
public AtomicStampedReference<String> reference=new AtomicStampedReference<>("a",0);
public void change(String s){
while(true){
String prev = reference.getReference();
String next = prev + s;
// 获得版本号
int stamp = reference.getStamp();
if(reference.compareAndSet(prev,next,stamp,stamp + 1)){
break;
}
}
}
4.4 原子数组
- AtomicIntegerArray
- AtomicLongArray
- AtomicReferenceArray
相比前面的原子整数和原子数组就是方法都添加了一个index属性,操作原子数组中的对应下标的对象
public AtomicIntegerArray value = new AtomicIntegerArray(10);
public void change(int index) {
while (true) {
int prev = value.get(index);
int next = prev + 1;
if(value.compareAndSet(index, prev, next)) {
break;
}
}
}
4.5 原子累加器
AtomicInteger虽然也能实现原子操作的累加器,但是效率不如接下来要写的LongAdder
性能提升的原因很简单,就是在有竞争时,设置多个累加单元,Thread-0累加Cell[0],而Thread-1累加
Cell[1].最后将结果汇总。这样它们在累加时操作的不同的Ce变量,因此减少了CAS重试失败,从而提
高性能。
public static void main(String[] args) {
// 46ms
demo(
()->new AtomicLong(0),
AtomicLong::getAndIncrement
);
// 15ms
demo(
LongAdder::new,
LongAdder::increment
);
}
public static <T> void demo(Supplier<T> supplier, Consumer<T> consumer){
T t = supplier.get();
List<Thread> threads = new ArrayList<Thread>();
for (int i = 0; i < 4; i++) {
threads.add(new Thread(() -> {
for (int j = 0; j < 500000; j++) {
consumer.accept(t);
}
}));
}
long start = System.currentTimeMillis();
threads.forEach(Thread::start);
threads.forEach(thread -> {
try {
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
long end = System.currentTimeMillis();
System.out.print("结果是"+t+"\t");
System.out.println("用时"+(end - start)+" ms");
}
4.6 ★Unsafe
cas的底层都是使用的Unsafe类来实现原子操作,如AtomicInteger,LongAdder
自己简单实现AtomicInteger类的原子操作
public class MyAtomicInteger {
private volatile int value;
static final Unsafe UNSAFE;
static final long VALUE_OFFSET;
static{
try {
// 获取Unsafe对象
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
UNSAFE = (Unsafe) theUnsafe.get(null);
// 获取域的偏移地址
VALUE_OFFSET = UNSAFE.objectFieldOffset(MyAtomicInteger.class.getDeclaredField("value"));
} catch (NoSuchFieldException | IllegalAccessException e) {
throw new RuntimeException(e);
}
}
public void addAndGet(int num) {
while(true) {
int prev = value;
int next = prev + num;
if (UNSAFE.compareAndSwapInt(this,VALUE_OFFSET,prev,next)) {
break;
}
}
}
}
5、并发工具
5.1 线程池
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7wMNhgOj-1659175633594)(https://cdn.jsdelivr.net/gh/l1727894442/image/ThreadPoolExecutor.png)]
5.1.1 构造方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
- corePoolSize核心线程数目(最多保留的线程数)
- maximumPoolSize最大线程数目(减核心线程数量为救急队列数目)
- keepAliveTime生存时间-针对救急线程
- unit时间单位-针对救急线程
- workQueue阻塞队列
- threadFactory线程工厂-可以为线程创建时起个好名字
- handler拒绝策略
5.1.2 运行过程
- 线程池中刚开始没有线程,当一个任务提交给线程池后,线程池会创建一个新线程来执行任务。
- 当线程数达到corePoolSize并没有线程空闲,这时再加入任务,新加的任务会被加入workQueue队列排
队,直到有空闲的线程。
- 如果队列选择了有界队列,那么任务超过了队列大小时,会创建maximumPoolSize-corePoolSize数目的
线程来救急。
- 如果线程到达maximumPoolSize仍然有新任务这时会执行拒绝策略。拒绝策略jd提供了4种实现,其它
著名框架也提供了实现
- AbortPolicy让调用者抛出RejectedExecutionException异常,这是默认策略
- CallerRunsPolicy让调用者运行任务
- DiscardPolicy放弃本次任务
- DiscardOldestPolicy放弃队列中最早的任务,本任务取而代之
- Dubbo的实现,在抛出RejectedExecutionException异常之前会记录日志,并dump线程栈信息,方便定
位问题
- Netty的实现,是创建一个新线程来执行任务
- ActiveMQ的实现,带超时等待(60s)尝试放入队列,类似我们之前自定义的拒绝策略
- PinPoint的实现,它使用了一个拒绝策略链,会逐一尝试策略链中每种拒绝策略
- 当高峰过去后,超过corePoolSize的救急线程如果一段时间没有任务做,需要结束节省资源,这个时间由
keepAlive Time和unit来控制。
5.1.3 具体线程池
5.1.3.1 newFixedThreadPool
固定大小线程池
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
特点:
- 核心线程数==最大线程数(没有救急线程被创建),因此也无需超时时间
- 阻塞队列是无界的,可以放任意数量的任务
评价
适用于任务量已知,相对耗时的任务
自定义取名规则使用:
ExecutorService pool = Executors.newFixedThreadPool(2, new ThreadFactory() {
final AtomicInteger i = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "my_thread_name_"+i.getAndIncrement());
}
});
5.1.3.2 newCachedThreadPool
带缓冲线程池
public static ExecutorService newcachedThreadPool(){
return new ThreadPoolExecutor(0,Integer.MAX_VALUE,
60L,TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
特点:
- 核心线程数是0,最大线程数是Integer…MAX VALUE,救急线程的空闲生存时间是6Os,意味着全部都是敕急线程(60s后可以回收)
- 救急线程可以无限创建
- 队列采用了SynchronousQueue实现特点是,它没有容量,没有线程来取是放不进去的(一手交钱、一手
交货)
5.1.3.3 newSingleThreadPool
单线程线程池
public static ExecutorService newsingleThreadExecutor(){
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1,1,
OL,TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
特点:
希望多个任务排队执行。线程数固定为1,任务数多于1时,会放入无界队列排队。任务执行完毕,这唯一
的线程也不会被释放。
区别:
- 自己创建一个单线程串行执行任务,如果任务执行失败而终止那么没有任何补救措施,而线程池还会新建
一个线程,保证池的正常工作
- Executors.newSingleThreadExecutor()线程个数始终为l,不能修改
- FinalizableDelegatedExecutorService应用的是装饰器模式,只对外暴露了ExecutorService接口,因此不
能调用ThreadPoolExecutor中特有的方法
- Executors…newFixedThreadPool(1)初始时为1,以后还可以修改
- 对外暴露的是ThreadPoolExecutor对象,可以强转后调用setCorePoolSize等方法进行修改
5.1.3.4 定时任务
ScheduledExecutorService
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
//参数列表 任务 延时执行时间 定时执行时间 时间单位
//以任务时间和定时执行时间最大值最为真正的定时执行任务时间
//ps:以下任务每4s执行一次
pool.scheduleAtFixedRate(()->{
try {
Thread.sleep(4000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
},10,2, TimeUnit.SECONDS);
//以任务时间+定时执行时间最为真正的定时执行任务时间
//ps:以下任务每6s执行一次
pool.scheduleWithFixedDelay(()->{
try {
Thread.sleep(4000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
},10,2, TimeUnit.SECONDS);
5.2 JUC
5.2.1 AQS
全称AbstractQueuedSynchronizer
特点:
- 用state属性来表示资源的状态(分独占模式和共享模式),子类需要定义如何维护这个状态,控制如何获取锁和释放锁
- getState
- setState
- compareAndSetState
- 独占模式只能有一个线程来访问资源,共享模式可以允许多个线程访问资源
- 提供了基于FIFO的等待队列,类似于Monitor的EntryList
- 条件变量来实现等待、唤醒机制,类似于Monitor的WaitSet
自定义不可重入锁:
class MyLock implements Lock{
class MySync extends AbstractQueuedSynchronizer {
@Override
protected boolean tryAcquire(int arg) {
if(compareAndSetState(0,1)){
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
@Override
protected boolean tryRelease(int arg) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
@Override
protected boolean isHeldExclusively() {
return getState() == 1;
}
}
1
private MySync sync=new MySync();
@Override
public void lock() {
sync.acquire(1);
}
@Override
public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}
@Override
public boolean tryLock() {
return sync.tryAcquire(1);
}
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
return sync.tryAcquireNanos(1,unit.toNanos(time));
}
@Override
public void unlock() {
sync.release(1);
}
@Override
public Condition newCondition() {
return null;
}
}
5.2.2 ReentrantReadWriteLock
简介:
- 读锁不支持条件变量,写锁支持条件变量
- 重入时升级不支持:即持有读锁的情况下去获取写锁,会导致获取写锁永久等待
- 重入时降级支持:即持有写锁的情况下去获取读锁
- 读读共享,读写、写写互斥
简单使用:
@Slf4j
public class ReadWriteLock {
public static void main(String[] args) {
ReadWriteLock data = new ReadWriteLock();
data.data = 10;
ExecutorService pool = Executors.newFixedThreadPool(2);
pool.submit(data::readData);
pool.submit(data::writeData);
}
public int data;
private final ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
private final ReentrantReadWriteLock.ReadLock readLock = lock.readLock();
private final ReentrantReadWriteLock.WriteLock writeLock = lock.writeLock();
public void readData() {
readLock.lock();
try {
log.debug("readData: " + data);
}finally {
readLock.unlock();
}
}
public void writeData() {
writeLock.lock();
try {
log.debug("writeData: " + data);
}finally {
writeLock.unlock();
}
}
}
5.2.3 StampedLock
简介:
该类自JDK8加入,StampedLock支持tryOptimisticRead()方法(乐观读),读取完毕后需要做一次戳校验如果校验通过,表示这期间确实没有写操作,数据可以安全使用,如果校验没通过,需要重新获取读锁,保证数据安全。
提供一个数据容器类内部分别使用读锁保护数据的read()方法,写锁保护数据的write()方法
特点:
- StampedLock不支持条件变量I
- StampedLock不支持可重入
简单使用:
@Slf4j
public class ReadWriteLock {
StampedLock lock = new StampedLock();
private void readLock() {
long stamp = lock.tryOptimisticRead();
// 验戳,判断是否有其他线程进行了写操作
if(lock.validate(stamp)) {
log.debug("读取成功,返回数据");
return;
}
// 加读锁进行读取
stamp = lock.readLock();
log.debug("Read lock");
lock.unlockRead(stamp);
}
private void writeLock() {
long stamp = lock.writeLock();
log.debug("Write lock");
lock.unlockWrite(stamp);
}
}
5.2.4 SemaPhore
-
使用Semaphore限流,在访问高峰期时,让请求线程阻塞,高峰期过去再释放许可,当然它只适合限制单机线程数量,并且仅是限制线程数,而不是限制资源数(例如连接数,请对比Tomcat LimitLatch的实现)
-
用Semaphore实现简单连接池,对比『享元模式』下的实现(用wait notify),性能和可读性显然更好,注意实现中线程数和数据库连接数是相等的
简单使用:
@Slf4j
public class SemaphoreTest {
public static void main(String[] args) {
Semaphore s=new Semaphore(3);//限制上限为3
for (int i = 0; i < 10; i++) {
new Thread(()->{
try {
s.acquire();
Thread.sleep(1000);
log.debug("线程"+Thread.currentThread().getName()+"获得了信号量");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}finally {
// 释放信号量
s.release();
}
}).start();
}
}
}
5.2.5 CountDownLatch
用来进行线程同步协作,等待所有线程完成倒计时。其中构造参数用来初始化等待计数值,await()用来等待计数归零,countDown()用来让计数减一
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(3);
for (int i = 0; i < 3; i++) {
new Thread(()->{
log.debug("begin");
latch.countDown();
log.debug("end");
}).start();
}
latch.await();
log.debug("所有线程执行完毕");
}
5.2.6 CyclicBarrier
CountDownLatch不能重复使用,重置自己的countDown计数。这时候CyclicBarrier的作用就体现出来了。
简单使用:
@Slf4j
public class CyclicBarrierTest {
public static void main(String[] args) {
CyclicBarrier barrier = new CyclicBarrier(2);
//线程池大小应该和任务数相同,不然可能会出现下一次循环的task 1和本次的task 1执行了一次整体任务
ExecutorService pool = Executors.newFixedThreadPool(2);
for (int i = 0; i < 4; i++) {
pool.submit(()->{
try {
log.debug("begin barrier task 1");
Thread.sleep(1000);
barrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
throw new RuntimeException(e);
}
});
pool.submit(()->{
try {
log.debug("begin barrier task 2");
Thread.sleep(2000);
barrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
throw new RuntimeException(e);
}
});
}
pool.shutdown();
}
}
5.2.7 线程安全的集合类
-
遗留的线程安全集合如Hashtable,Vector
-
使用Collections装饰的线程安全集合,如:
- Collections.synchronizedCollection
- Collections.synchronizedList
- Collections.synchronizedMap
- Collections.synchronizedSet
- Collections.synchronizedNavigableMap
- Collections.synchronizedNavigableSet
- Collections.synchronizedSortedMap
- Collections.synchronizedsortedset
-
java.util.concurrent.*
-
重点介绍java.util.concurrent.*下的线程安全集合类,可以发现它们有规律,里面包含三类关键词:Blocking、CopyOn Write、Concurrent
5.3 ForkJoin
Fok/Joi是JDK1.7加入的新的线程池实现,它体现的是一种分治思想,适用于能够进行任务拆分的cpu密集型运算
所谓的任务拆分,是将一个大任务拆分为算法上相同的小任务,直至不能拆分可以直接求解。跟递归相关的一些计算,如归并排序、斐波那契数列、都可以用分治思想进行求解
Fok/Joi在分治的基础上加入了多线程,可以把每个任务的分解和合并交给不同的线程来完成,进一步提升了运算效率
Fork/Join默认会创建与cpu核心数大小相同的线程池
简单使用:
提交给Fork/Join线程池的任务需要继承RecursiveTask(有返回值)或RecursiveAction(没有返回值)
@Slf4j
public class ActionTask extends RecursiveTask<Integer> {
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool(4);
Integer result = pool.invoke(new ActionTask(1, 10));
log.debug("result: " + result);
}
private int begin;
private int end;
public ActionTask(int begin, int end) {
this.begin = begin;
this.end = end;
}
@Override
protected Integer compute() {
if (begin == end) {
return end;
}
if (begin == end - 1) {
return begin + end;
}
int mid = begin + ((end - begin)>>2);
ActionTask task1 = new ActionTask(begin, mid);
task1.fork();
ActionTask task2 = new ActionTask(mid + 1, end);
task2.fork();
int result = task1.join()+task2.join();
return result;
}
}