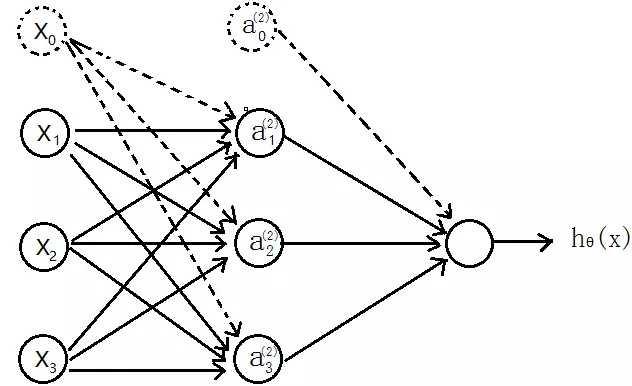
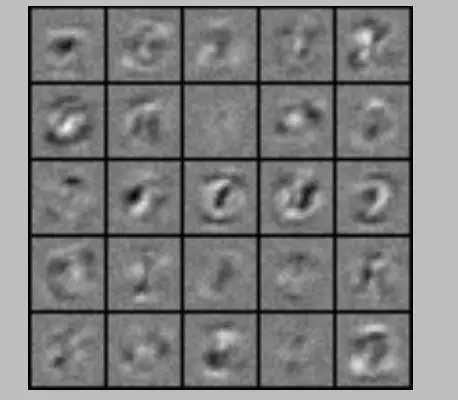
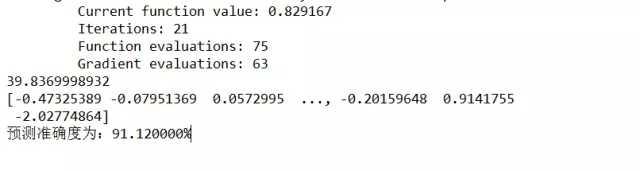
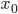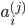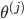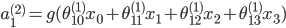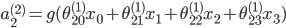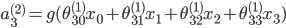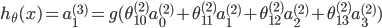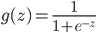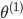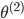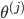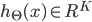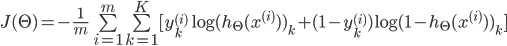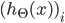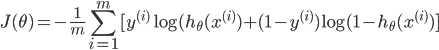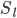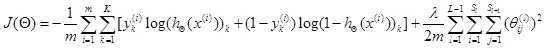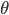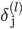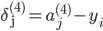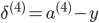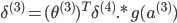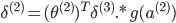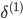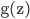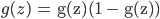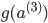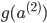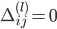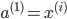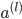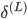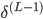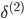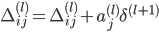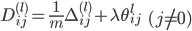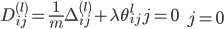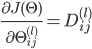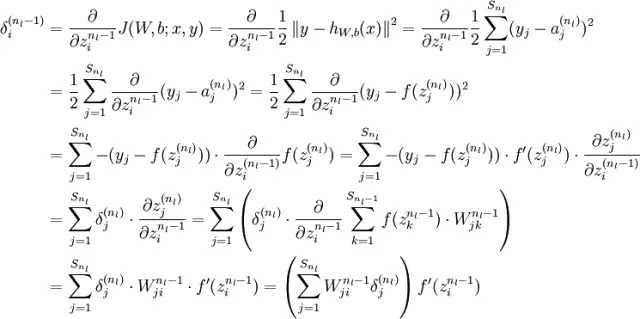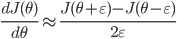| # 梯度
def nnGradient(nn_params,input_layer_size,hidden_layer_size,num_labels,X,y,Lambda):
length = nn_params.shape[0]
Theta1 = nn_params[0:hidden_layer_size*(input_layer_size+1)].reshape(hidden_layer_size,input_layer_size+1)
Theta2 = nn_params[hidden_layer_size*(input_layer_size+1):length].reshape(num_labels,hidden_layer_size+1)
m = X.shape[0]
class_y = np.zeros((m,num_labels)) # 数据的y对应0-9,需要映射为0/1的关系
# 映射y
for i in range(num_labels):
class_y[:,i] = np.int32(y==i).reshape(1,-1) # 注意reshape(1,-1)才可以赋值
'''去掉theta1和theta2的第一列,因为正则化时从1开始'''
Theta1_colCount = Theta1.shape[1]
Theta1_x = Theta1[:,1:Theta1_colCount]
Theta2_colCount = Theta2.shape[1]
Theta2_x = Theta2[:,1:Theta2_colCount]
Theta1_grad = np.zeros((Theta1.shape)) #第一层到第二层的权重
Theta2_grad = np.zeros((Theta2.shape)) #第二层到第三层的权重
Theta1[:,0] = 0;
Theta2[:,0] = 0;
'''正向传播,每次需要补上一列1的偏置bias'''
a1 = np.hstack((np.ones((m,1)),X))
z2 = np.dot(a1,np.transpose(Theta1))
a2 = sigmoid(z2)
a2 = np.hstack((np.ones((m,1)),a2))
z3 = np.dot(a2,np.transpose(Theta2))
h = sigmoid(z3)
'''反向传播,delta为误差,'''
delta3 = np.zeros((m,num_labels))
delta2 = np.zeros((m,hidden_layer_size))
for i in range(m):
delta3[i,:] = h[i,:]-class_y[i,:]
Theta2_grad = Theta2_grad+np.dot(np.transpose(delta3[i,:].reshape(1,-1)),a2[i,:].reshape(1,-1))
delta2[i,:] = np.dot(delta3[i,:].reshape(1,-1),Theta2_x)*sigmoidGradient(z2[i,:])
Theta1_grad = Theta1_grad+np.dot(np.transpose(delta2[i,:].reshape(1,-1)),a1[i,:].reshape(1,-1))
'''梯度'''
grad = (np.vstack((Theta1_grad.reshape(-1,1),Theta2_grad.reshape(-1,1)))+Lambda*np.vstack((Theta1.reshape(-1,1),Theta2.reshape(-1,1))))/m
return np.ravel(grad)
|