一、背景
大语言模型应用未来一定是开发热点,现在一个比较成功的应用是外挂知识库。相比chatgpt这个知识库比较庞大,效果比较好的接口。外挂知识库+大模型的方式可以在不损失太多效果的条件下获得数据安全。
二、原理
现在比较流行的一个方案是langchain+chatglm,这已经算是一个成品了,也可以考虑自己上手捏一下泥巴,langchain学习成本有点高,可以直接利用prompt来完成问问题会简单很多。具体方案我参考了这个文章:大模型外挂(向量)知识库 - 知乎 (zhihu.com) 基本的思路简化成这张图
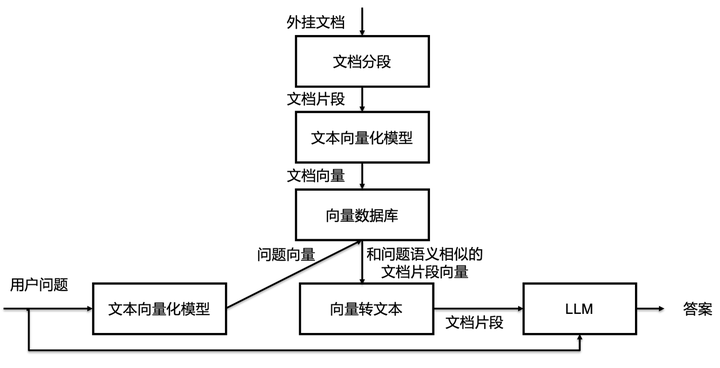
简单的说就是根据用户问题,从知识库获取与“问题”相关的“文档片段”, 让大模型根据文档片段来回答“问题”。其实这种根据指定内容回答问题的模型也是挺成熟的,至少huggingface上就有很多,只不过那些模型是根据BERT模型+QA数据集微调好的。我们相信chatglm这类大模型理解问题和总结内容的能力一定更强。
这里就涉及到一个如何获取“问题”相关的“文档片段”的过程了,其实可以直接用文本检索方式,但传统的全文检索由于是词的匹配,因此对纯粹的问句效果可能不好。因此现在主流的方式是用向量匹配,就是把“问题”和知识库的文本都转成向量,再用向量的近似搜索获取更为相关的结果。
应用这种方式会很容易想到一个问题,也是上面知乎文章中提到的对称语义检索。即一定会把与“问题”接近的语句作为第一返回,它只是文字表述和问题一样,但并不是问题的答案。例如

也许这不是个问题,因为谁会在知识库里留下大量问句呢?或者你可以通过预处理把问题和大量正文绑定起来就不会匹配出“问题”了。所以使用向量的效果到底比纯粹的全文检索是否更好我也不清楚,毕竟检索效果还和预处理时候文本片段的切割、向量转换、向量最近邻查询效果 有关系。
三、实现
这里我直接使用了text2vec + chromadb简单实现。text2vec负责对文本转为向量, chromadb负责进行向量检索。
text2vec地址在shibing624/text2vec-base-chinese · Hugging Face ,预训练模型不算大
chromadb是一个新出的向量数据库,很多功能不完善,只是为了快速地体验一下向量存储检索功能,
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)